市場機会と顧客ニーズが変化する中で、データを中心とするアプローチが企業成長の鍵を握っています。大量のデータから新しいビジネスの洞察と将来の予測を導き出し、意思決定を高度化するために、AI・機械学習モデルの必要性も高まっています。dotData Enterpriseは、特徴量設計と機械学習を含むAI開発の全体を自動化し、AIを活用して予測分析やビジネスユースケースの開発を加速します。この機械学習ツールの導入メリットは、機械学習プロセスの大幅な効率化、データ分析の精度向上、そして迅速かつ戦略的な意思決定の実現です。
データからビジネスインサイトと将来の予測を導き出す
ノーコードの自動化で企業の予測AIを民主化する
dotData Enterpriseは、専門的な知識がなくても、GUIからのクリック操作のみで、AIによる予測モデルをノーコードで開発することができる機械学習プラットフォームです。dotData独自の特徴量自動設計技術によって、生のビジネスデータから特徴量を発見し、機械学習自動化による予測モデルの構築をワンストップで実現します。さらに、このプラットフォームは、企業が自社のニーズに合わせて機械学習サービスを活用しやすくする基盤として機能し、業務効率や意思決定の高度化を支援します。dotData Enterpriseは、企業におけるデータ活用とデジタルトランスフォーメーション(DX)を推進し、予測AIを民主化し、データとAIプラットフォームの利点を活かしてビジネスを加速します。

製品の特長
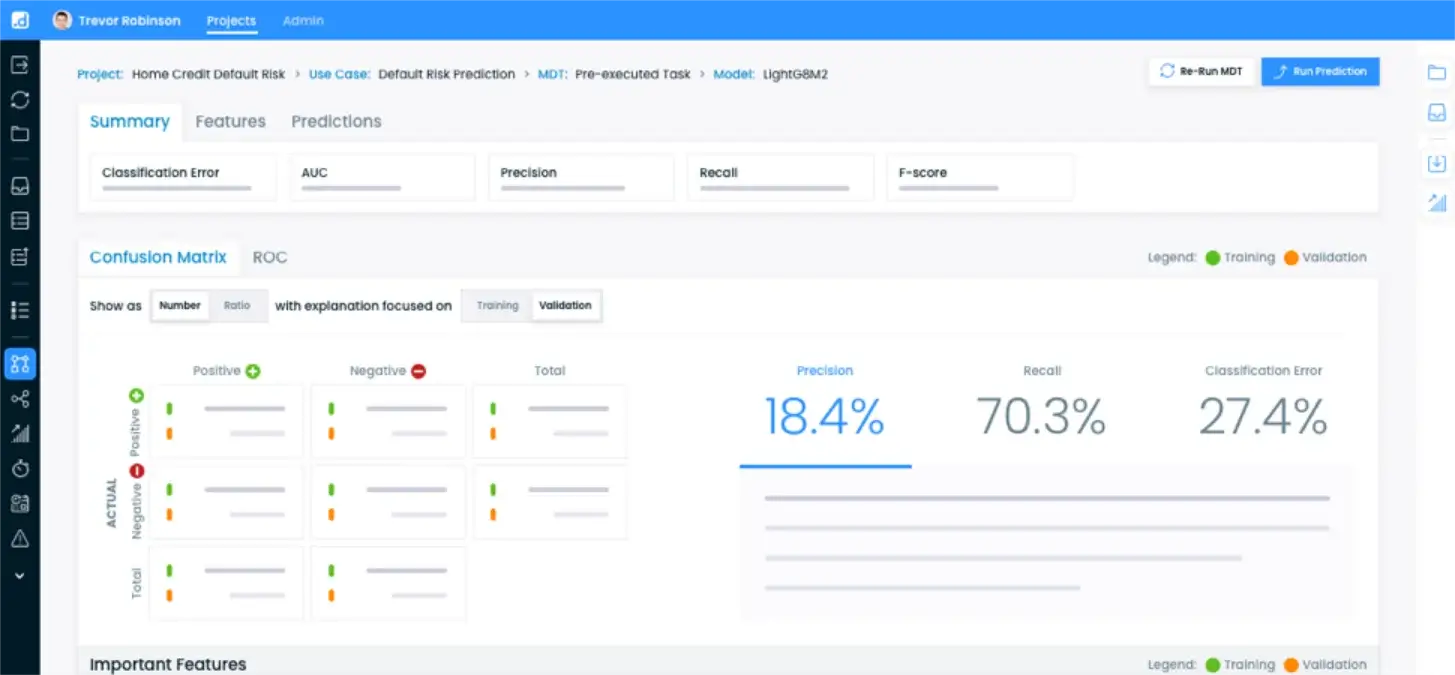
予測AIのワークフロー全体を自動化するdotData Enterpriseは、業務データから特徴量を発見し、高精度な機械学習モデルを構築します。人工知能(AI)による自動化によって、膨大なデータの効率的な分析を可能にします。これにより、企業は効果的にビジネスインサイト(洞察)導き出し、データドリブンな意思決定を実現できます。
複数ソース、複数表からの特徴量エンジニアリング
dotData独自の特徴量自動設計技術が、ターゲットテーブル(目的変数)、ソーステーブル(入力テーブル)、テーブル間の関係(エンティティリレーション)を指定するだけで、数値、カテゴリ、時系列、テキスト、地理空間などのマルチモーダルなデータセットから、機械学習モデルの予測力を高め、ビジネスインサイト(洞察)をもたらす特徴量を発見します。
データ加工&
データクレンジング
不正なデータ値、欠損値、外れ値、カテゴリ値の正規化、レコードの重複などを自動的に検出し、ソースデータをクレンジングします。これにより、時間がかかり、またエラーが発生しやすいデータ加工の作業を最小化し、特徴量と予測の品質を最大化します。
企業データにおける
スケーラビリティ
dotData Enterpriseは分散計算技術によって、大規模データに対するスケーラビリティを備えて構築されています。これにより、数十のテーブル、数千の列、数 十億の行を処理することができます。企業の大量のデータを処理をする際に、高度な分散計算技術で通常必要となる煩雑な設定や調整は必要ありません。
複数のデータソースを統合
Oracle、Teradata、MS SQL ServerのようなデータウェアハウスやGoogle Big Query、Amazon Redshift、Snowflakeのようなデータレイクなどの複数のデータソースから収集されたデータを自動的に統合・マッピングし、データソース間のメタ情報の違い意識せずに、データを統一的に扱うことができます。
機械学習自動化(AutoML)
最先端の機械学習アルゴリズム、ハイパーパラメータの調整、欠測値の補完、外れ値のクレンジングなどを活用します。特徴量自動設計と機械学習の自動化(AutoML)を組み合わせ、ビジネスの生データから特徴量、そして予測モデルの構築までワンストップで実行します。柔軟で効率的な機械学習ツールと、データ処理や分析に適した環境構築により、AI開発の自動化を実現します。
時系列モデリング
AIの説明性と透明性
dotData Enterpriseは、予測AIの説明性を強化するように設計されており、実践的で信頼できるAI戦略を提供します。特徴量の説明文、設計図、さまざまな可視化分析機能を提供し、特徴量とモデルの透明性を促進します。
dotData Opsと統合
dotData Enterpriseで特徴量と予測モデルを構築したら、dotData Opsとシームレスに連携し、 本番環境へ移行、運用が可能です。これにより、予測を継続的に実行し、モデルのパフォ ーマンスと品質を監視できます。
利用のステップ
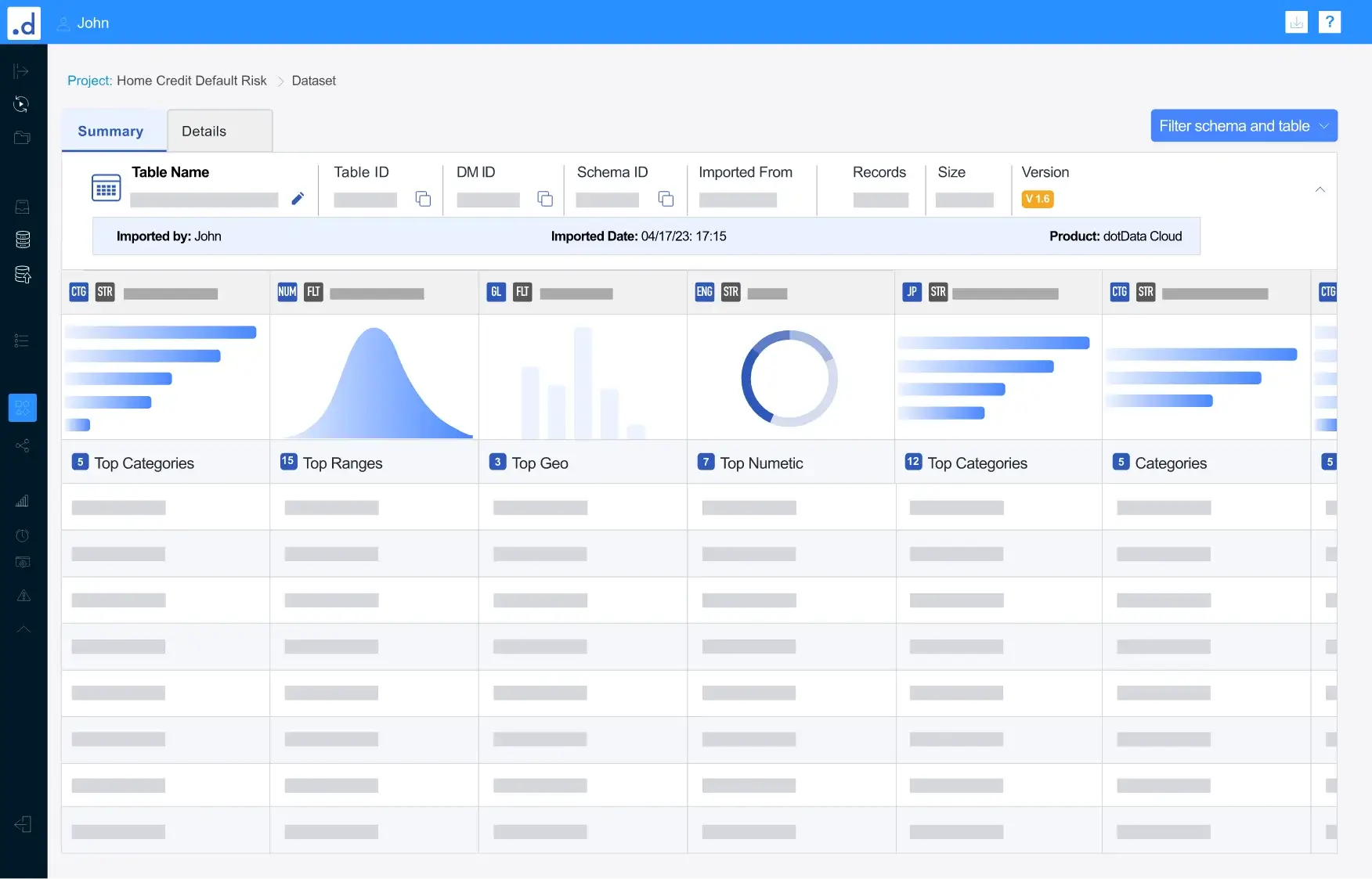
データレイクやデータウェアハウスに接続し、保有するリレーショナルデータの全てを活用
- 最新のクラウドデータマート(Amazon Redshift、Google Big Query、Snowflake、MS Azure Synapseなど)、従来のデータウェアハウス(Oracle、Teradata、MS SQL Server)、フラットデータソース(CSVファイル、Tableau Hyperファイルなど)からデータをロード
- データソースから直接データスキーマやエンティティ・リレーションなどのメタデータ情報を抽出または推定します。また、異なるソースからのメタデータを自動的に正規化
- 数十億のレコードと数百のカラムを持つデータを可視化し、データ品質を評価して、探索的なデータ分析やカスタマイズされたデータ変換を実行
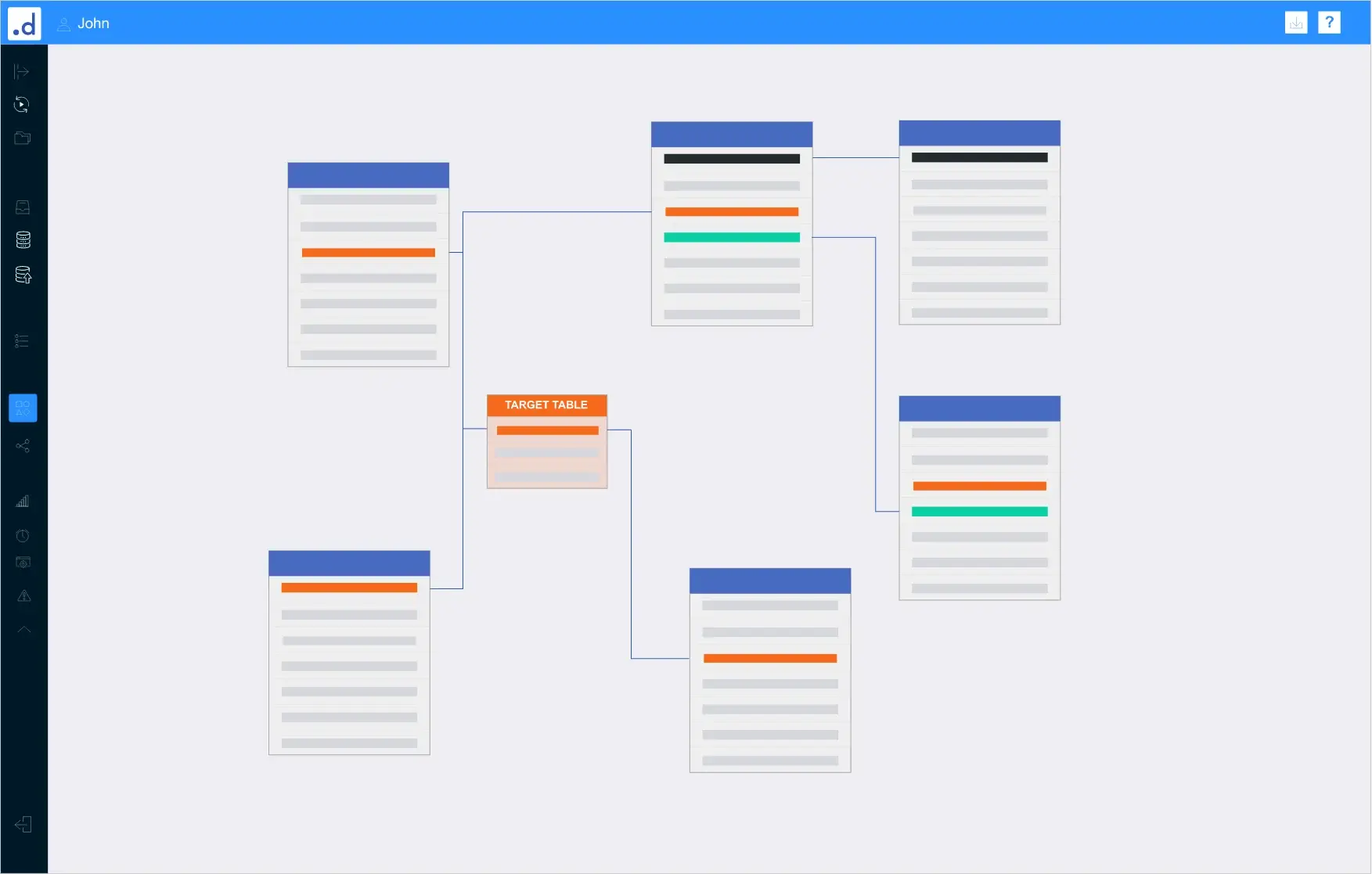
特徴量を探索するために使用するターゲット変数とソーステーブルを選択し、実行をクリックすると、dotDataが最も難しくて手間がかかる作業を短時間で実行
- 不正な値、外れ値、データの正規化、欠損値、ターゲットラベルのマッピングなど、自動的にクレンジングを実行し、データ品質を改善
- dotData独自のアルゴリズムに基づいて、数値、カテゴリ、時系列、テキスト、空間データから、数百万もの特徴量仮説を生成・探索
- 予測に有効な特徴量を自動的に選択・レコメンドすることで、ドメインバイアスを最小化
- 勾配ブースティング、ニューラルネットワーク、アンサンブルモデル、決定木、ロジスティック回帰などを用いて最先端の機械学習モデルを構築
- 機械学習モデルのパラメータを調整し、最も性能の良いモデルを選択
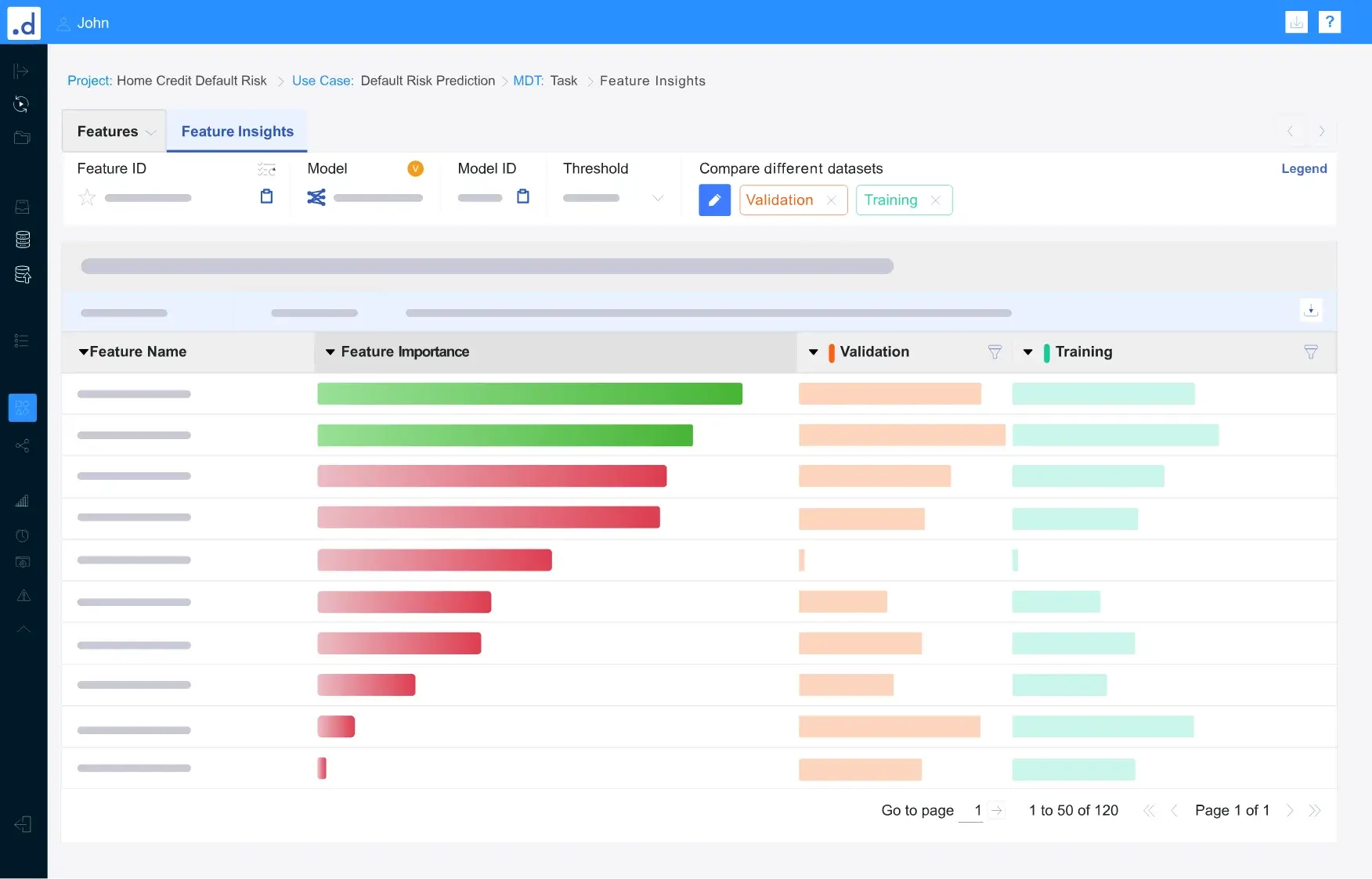
特徴量を分析、評価することで、ビジネスインサイトをもたらすパターンを発見
- 自動生成された特徴量説明文により、各特徴量の意味を定性的に理解し、特徴量設計図により、各特徴量の生成手順を理解
- 相関係数、特徴量ごとのAUC、特徴量重要度、局所性など、各種のメトリクスに基づいて、特徴量を定量的に理解し選択
- 特徴量のセグメンテーション分析を実行し、特徴量間または特徴量とターゲット変数との間の深い関係を発見
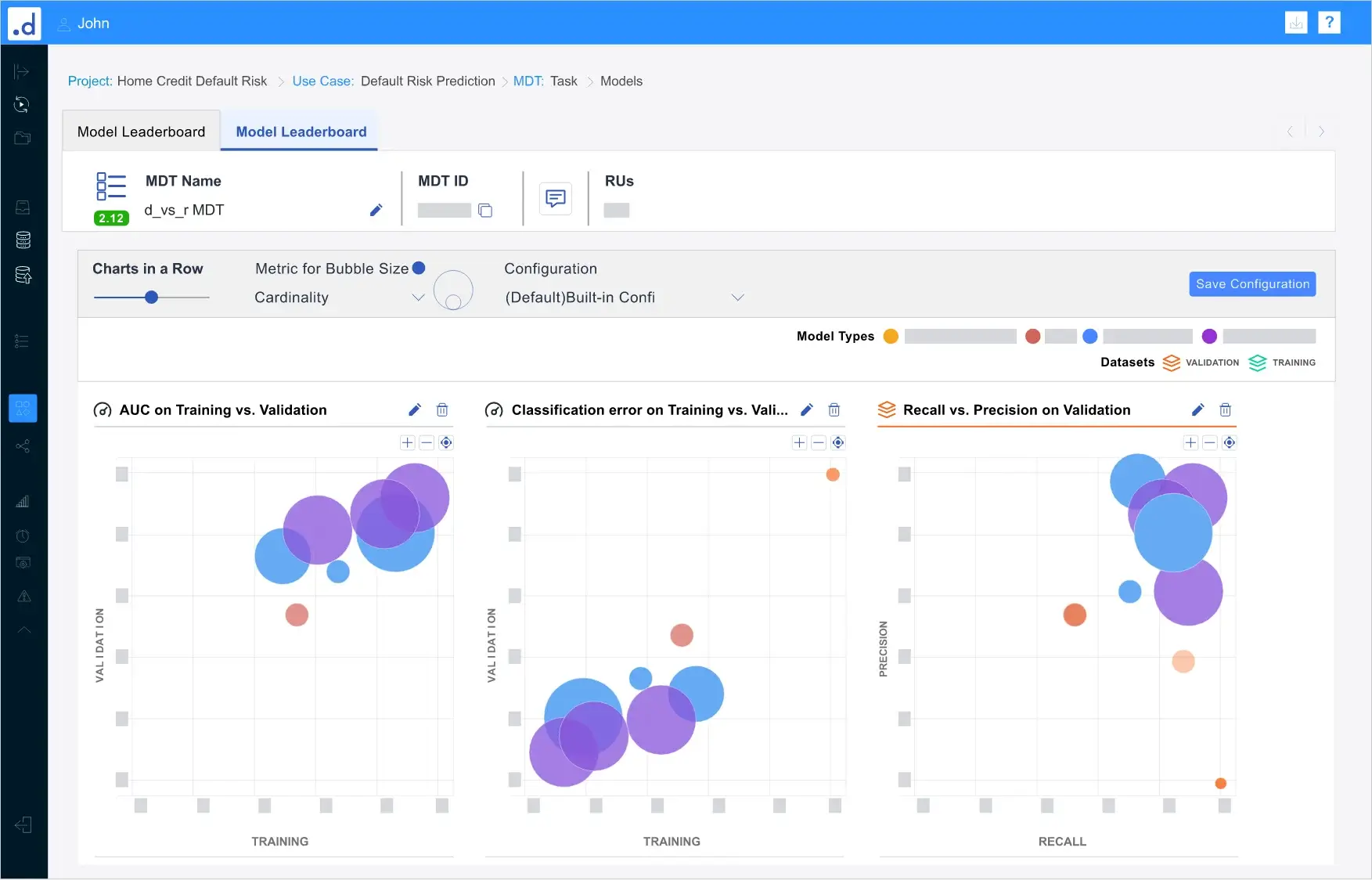
機械学習自動化(AutoML)により、ビジネスの予測モデルを構築するのに最適なMLモデルを選択
- モデルの可視化やリーダーボードを使用して、機械学習モデル間のトレードオフを分析し、適切なモデルを選択
- モデルのレコメンド機能を活用して、モデルの精度、ロバスト性、複雑度、解釈性を比較し、最適なモデルを簡単に発見
- 混同行列、ROC曲線、リフトチャート、誤差分布などのさまざまな手法で各モデルを可視化分析
dotData Opsとの連携で、データ加工、特徴量生成、予測実行、監視や再学習をワンストップで運用化
- dotData EnterpriseからdotData Opsへモデルパッケージをエクスポートすることでモデルを自動デプロイ。GUI上で簡単に予測ジョブをスケジュール
- dotDataのAPIとJDBCコネクタを使用して、BIダッシュボードやビジネスプラットフォームで結果を利用
- dotData EnterpriseのGUI上でモデルを使用して、予測を実行
お客様の声
株式会社大塚商会
AIやビッグデータという言葉が生まれる前から、大塚商会では大量のデータを蓄積してきました。顧客のニーズや購買パターンをAIにより発見し、営業力のさらなる強化を進めています。
三井住友海上火災保険株式会社
dotDataの特徴量を通じた営業活動や顧客接点におけるデータの有効性が実感できたことで、データドリブンな発想を持つ風土が醸成されつつあり、社員・代理店のDXが飛躍的に進んでいます。
横浜ゴム株式会社
dotDataによって到底発想し得ないような、斬新な切り口の特徴量が多く抽出され、タイヤ開発のイノベーションに繋がっています。
AI活用事例


ニュース
プレスリリース
dotDataが「dotData ビジネスアナリティクス人材育成サービス」を発表
プレスリリース
dotData、「dotData Insight」を発表 – 生成AIと特徴量自動設計がデータからビジネス仮説を生成
プレスリリース
dotDataがdotData Enterprise 3.2をリリース
プレスリリース
dotData Enterprise 2.12をリリース
プレスリリース
「dotData Enterprise Version 2」、大幅に機能更新したUXのフルモデル・チェンジで提供開始、誰もがデータサイエンスを実行できる「データサイエンスの民主化」を実現
プレスリリース
dotDataがTableauと連携し、BIユーザー向けにAI / 機械学習の利用を加速
dotDataのAIプラットフォーム 特徴量がデータ活用の成否を決める
dotDataは、独自の特徴量自動設計技術をコアとして、機械学習でAIモデルを構築する、特徴量をアセットとして蓄積しデータを強化する、データインサイト(洞察)を抽出して業務をデータドリブンに変革するといった、様々なシーン毎に最適なAIプラットフォームを提供し、データ活用、AIによるビジネスのDXを支援します。
お問い合わせ・
資料ダウンロード
気軽に話を聞いてみたい、ユースケースを知りたいなど、お客様のニーズに合わせてサポート致しますので、まずはお気軽にお問い合わせください。また、資料ダウンロードもご利用ください。
よくある質問
dotData Enterpriseは、特徴量エンジニアリングを自動化する独自の技術を組み込んだ特化型AIを開発するための機械学習プラットフォームです。最大の特長は、機械学習自動化(AutoML)による機械学習モデルの最適化だけでなく、AIモデルやデータインサイト(洞察)にとって最も重要となる「データに隠れたパターン」を「特徴量」として、独自のアルゴリズムが自動的に発見する点です。これによって、データ分析の80%の工数を占めると言われる、目的別のデータ加工、特徴量設計を大幅に省力化し、AIモデル開発の短期化、データ活用の民主化、そして人間が気がつかなかった新たな気付き(データインサイト)を企業に提供します。
dotData Enterpriseを含むdotDataのAIプラットフォームは、「dotData Cloud」という形でクラウドで、データ活用やAI開発に利用することができます。dotData Cloudには、dotData社のクラウド環境にプラットフォームをホスティングする「Starter」、セキュリティ強化版である「Standard」、そしてユーザーのクラウド環境にStandardと同等の環境を構築する「Private」という提供形態があります。
dotData Enterpriseは、ノーコードでデータ加工、特徴量設計、機械学習モデルの構築が必要なため、最小限の事前知識で、データサイエンスや機械学習の高度な専門知識がなくても使いこなすことができます。また、dotDataのAIプラットフォームは、データや機械学習の専門知識を持ったIT部門やデータサイエンティスト向けの「dotData Feature Factory」、分析部門や業務部門が予測分析をノーコードで実施するための「dotData Enterprise」、特徴量を通じてビジネスインサイト(洞察)を見つけ出す「dotData Insight」と、組織のデータ活用に対する成熟度(知識やスキル)に応じて使い分けることができます。また、データ活用がはじまったばかり(或いは、これから始めようとしている)の企業には、dotDataのサポートチームがトライアルや伴走支援などを通じて、成功へと導きます。
dotDataの特徴量自動設計は、ディープラーニング(深層学習)のような高次元のブラックボックス化された特徴量とは異なり、説明性の高い特徴量に絞って探索を行います。これによって、業務部門が特徴量を通じた予測結果を理解し、またデータを活用してビジネスインサイト(洞察)を発見することを支援します。また、dotDataは、ディープラーニングが扱うことができない、複数表を直接入力として、業務データを直接探索することで、よりよい特徴量を探索することができる点も、大きな利点です。
データ準備やデータ前処理には、汎用の処理、目的別の処理があります。前者(汎用)は、マスターデータマネージメントと呼ばれ、業務データを企業として整理、管理、蓄積するプロセスとなり、dotDataのAIプラットフォームは、汎用のデータ準備と前処理には対応していません。一方で、汎用のデータ準備や前処理が完了した業務データに対して、例えば、ある製品を購入するお客様の特徴を知りたい、あるサービスを解約するお客様を予測したいなどの目的ごとにデータの前処理、加工、クレンジングが必要となり、dotDataはこの工程を自動化し、目的に対応したデータのパターンを発見します。
dotDataは、主に企業の業務データ(ファーストパーティーデータ)から特定にビジネスの目的に対応する特徴量を通じて、数値やカテゴリ、テキストなど様々なデータからの知識や知見を発見します。一方で、生成AIは、世の中に存在する大量のデータを目的を限定せずに大規模言語モデルとして学習し、いわゆる「世界知識」によって、非常に汎用的な質疑応答を実現したり、業務知識を読み込ませることで、特定目的に特化した要約や質疑を得意とします。dotDataと生成AIは、得意なデータや知識に違いはありますが、どちらも特化型AIであり、dotDataと生成AIを組み合わせることで、より高次のデータインサイト(洞察)を導き出すことが可能です。