
解説:機械学習のための特徴量設計
- 特徴量
- 時系列データ
- 機械学習
- データ分析
- ビジネスアナリティクス
例えば、機械学習や人工知能を応用した顧客の解約予測、製品需要予測、商品の売上予測など、ビジネス上の重要かつ複雑な問題に取り組んでいるとしましょう。機械学習による予測分析では、よりよい機械学習のアルゴリズムや手法を選ぶことが成功の鍵であると思われがちです。ロジスティック回帰、決定木、ブースティング、ニューラルネットワークなど、適切な機械学習のモデルを選び、予測精度と解釈性のトレードオフを考慮しながらモデルをチューニングする作業も、モデル開発にとって欠かせない工程です。一方で、Garbage-in, Garbage-out(ゴミを入力すると、ゴミが出力される)という有名な言葉の通り、機械学習モデルを訓練するための入力データの準備が、多くの場合、機械学習の成否を決めます。この、機械学習モデルを訓練するための入力データ(説明変数)の準備を、特徴量設計、或いは、特徴量エンジニアリング、といい、特徴量とは説明変数とほぼ同じ意味と考えることができます(現代機械学習における特徴量は、ディープラーニングに非構造化データからの特徴量を含み、古典統計における特徴量よりも広い意味で使われます)。
機械学習や統計の教科書では、目的変数(Y)と説明変数(X)があり、その関係性を統計的に学習或いはモデル化すると説明されています。また、説明変数Xに対して、例えば、カテゴリ変数に対してワンホットエンコーディングを適用したり、数値変数に対する四則演算或いはlog変換を適用したり、或いは主成分分析のような多変量解析を利用して、Xから新しい変数を作成する工程が特徴量設計として説明されています。
この「説明変数(X)」は、どこからやってくるのでしょうか?実際の業務データは、顧客、製品、従業員などエンティティの異なるマスターテーブルや、履歴テーブルや時系列データのようなトランザクションなど、様々な形の異なるテーブルにデータが分かれて、データベースに蓄積されています。現実の機械学習プロジェクトにおける特徴量設計とは、このように業務のために蓄積されたローデータからドメイン知識に基づいて機械学習に入力できる説明変数(一枚表)を作成するプロセスです。目的変数(業務課題)に対して適切な特徴量を設計するためには、業務知見、データ加工、数学・統計など、さまざまなスキルが必要になります。特徴量を設計するためには、通常、SQLなどを駆使して多数のクエリを実装し、多くのデータ操作と変換を実行する必要があります。以下の模式図は、構造化データ(業務データの多くは、構造化されデータベースに蓄積されています)を特徴量に変換する様子を表しています。
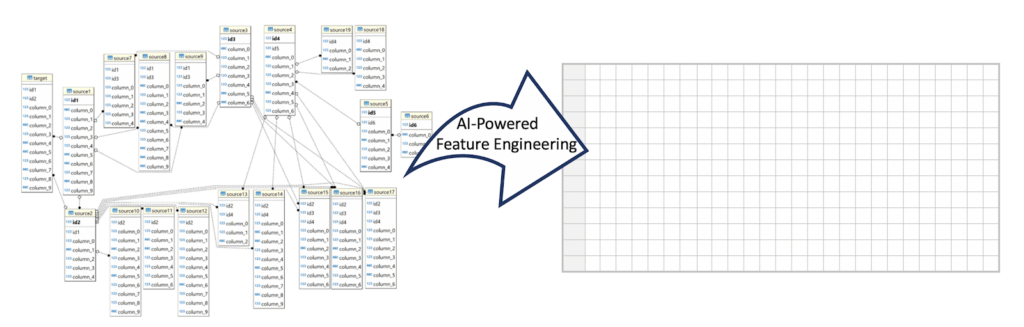
なお、本ブログでは、特徴量エンジニアリングの中でも、複数のテーブルに分かれた業務データから機械学習の入力となる説明変数(特徴量)を見つけ出す工程に焦点をあて、特徴量選択には深く踏み込みません。特徴量の選択は多数の特徴量の候補がから、有効な特徴量を選択する重要な工程ですが、説明変数Xが準備されてから適用することができます(なお、dotDataの特徴量自動設計のように数百万もの特徴量を探索させる場合には、Xをメモリ上に展開することができないため、特殊な特徴量選択のテクニックが必要となります)。
前節で説明したように、機械学習による予測モデルの品質や予測精度は、入力データとなる特徴量の品質に左右されます。例えば、顧客が短期間のうちにコールセンターに何度も問い合わせをしてきた場合には、顧客が何らかの不満やトラブルを抱えている可能性が高く、例えば「3日間のコールセンターへの問い合わせ回数」は、解約予測のための有効な特徴量となるかもしれません。或いは、小売り店舗にとって、「周辺2km以内で体育祭をやる学校があるかどうか」が、商品の需要予測精度向上に効く特徴量になるでしょう。
このように、特徴量設計は、予測精度を高めるための複雑な数学や統計的な変換を見つけ出す以上に、目的変数(ビジネスの課題)と関係性の深い意味のある「特徴」を見つけ出すことが重要です。一方で、そのような特徴量を見つけ出すためには、ドメインの知識(業務に関する知識や、ビジネス課題に対する経験と直感)、データの知識(データ項目の意味や、テーブル間の関係性)、統計・機械学習の知識(統計的な安定性や予測力)といった様々な知識が求められ、特徴量設計は機械学習モデルを開発するプロセスの中で、最も重要かつ最も難しい工程と言われています。データ加工、特徴量設計、機械学習と可視化という一連のプロセスの中で、機械学習は統計数理という業界非依存のスキルとして比較的身につけやすい一方で、データ加工や特徴量設計は、業界や業務、或いは個別企業に特有のデータやドメインの知識が求められるため、知識やノウハウの蓄積が非常に重要になります。

特徴量設計には、様々な手法がありますが、大きくは入力データのタイプによって分類することができます。
例えば、カテゴリ属性に対する最も一般的な特徴量設計の方法は、カテゴリ属性を数値表現に変換するというものです。これは、カテゴリ値を数値へとエンコード(符号化)し、これによって多くの機械学習アルゴリズムにとって扱いやすい新しい数値属性を生成します。基本的なワンホット・エンコーディングやラベル・エンコーディング、目的変数の情報を考慮したターゲット・エンコーディングなどが代表的です(各手法の詳細は、カテゴリ属性に対する特徴量設計を参照してください)。
時間情報に基づく特徴量も非常に重要かつ、特に時系列予測において、機械学習モデルの予測精度の向上に大きく寄与します。時系列データに対する特徴量には、ラグ特徴、時間間隔特徴、タイムスタンプと時間的イベント、フーリエ変換やウェーブレット変換などより高度な数学的変換に基づく特徴などが代表的です(各手法の詳細は、時系列データの特徴量設計 – パート2を参照してください)。
その他にも、位置・空間情報に基づく特徴量や、テキストや音声などの非構造化データからの特徴量など、データの性質や、ビジネスの課題(目的変数)によって、特徴量とは無限に可能性があり、特徴量設計は分析者のアイデアやスキルといった属人性が高くなりがちです。
前節で、いくつかのデータタイプに関する特徴量と特徴量設計について説明しましたが、このブログの冒頭で説明したように、現実のプロジェクトにおける特徴量設計の難しさは、多数の異なるテーブルから特徴量のアイデアを考え、そのデータを加工する複数表の取り扱いにあります(複数表からなる業務データからの特徴量設計については、このブログでより詳細を解説します)
例えば、クレジットカードの解約予測を考えてみます。解約者の情報、顧客マスター、支払い履歴という3つのテーブルがあったとします。この例では、例えば、顧客の職種という特徴は、顧客マスターと解約者テーブルを結合(join)すれば特徴量化することができますが、支払い履歴は一人の顧客が複数レコードを持つために、各顧客ごとにどの期間のデータを紐づけるのか?また複数のレコードをどのように集約して一つの特徴量とするのか?といった問題があります。さらに、男性の顧客に限定して支払い履歴を分析しようとすれば、顧客マスターと支払い履歴のテーブルの組み合わせを考えることが必要になります。
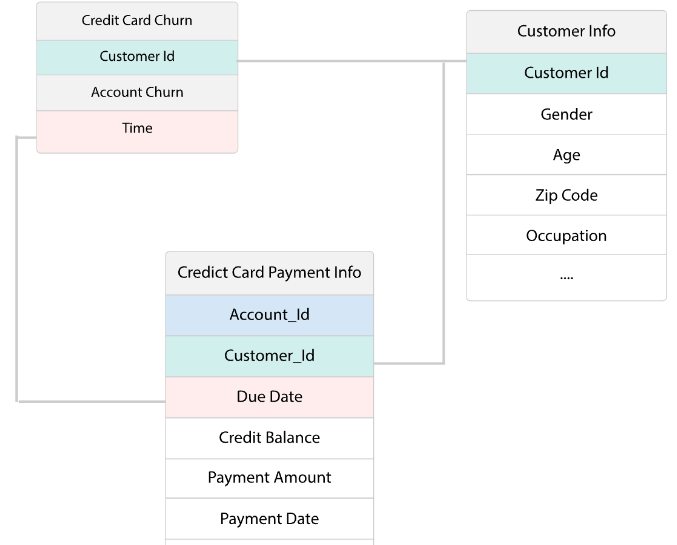
テーブル数が3つのケースであれば、まだ手作業による特徴量設計もできそうですが、現実の業務データはさらに多数のテーブルが、より複雑な関係性でつながっています。このような複雑なデータに対して、経験や直感、属人的なスキルによって特徴量を設計することは容易ではなく、経験豊富な専門家であっても、一つの機械学習プロジェクトに対して数週間から数ヶ月もの時間がかかる大きな要因となっています。

dotDataは、独自のAI(特徴量自動設計技術)の導き出す特徴量によって、全ての企業がデータに基づき、より良い製品やサービスを生み出すことができる世界を目指し、特徴量を自動的に抽出し、高度な予測分析やビジネスの洞察を導き出します。
特徴量設計の自動化は、従来のデータ分析や機械学習のプロセスを大きく変える可能性を秘めています。スキルの障壁を大幅に下げ、手作業による何百、何千ものSQLクエリ実装作業を排除し、完全なドメイン知識がなかったとしても、素早く分析プロジェクトを回すことができます。また、膨大な特徴の仮説をわずか数時間で探索し、これまで気づかなかったデータに隠された知見を発見し、データから得られるビジネスの洞察を強化します。
dotData Feature Factoryは、特徴量エンジニアリングをデータ中心のアプローチへと進化させます。特徴量空間をプログラム的に定義することで、手作業では不可能な圧倒的に広い範囲の特徴量仮説を自動生成し、ユーザーのデータや業務に関する知識を再利用可能なプロセスとして分析データベースに記憶します。また、発見した新しい特徴量を、本番環境で利用可能な特徴量パイプラインを自動生成ます。
dotData Enterpriseは、特徴量自動設計と機械学習自動化(AutoML)によって、AIの専門知識やコーディングなしで、業務データから特徴量の抽出、そして機械学習による予測モデルの構築まで、ワンストップでAIを開発することができます。dotData Insightは、特徴量を、生成AIの「世界知識」で補完し、実用的なビジネス仮説を生み出すビジネスアナリティクスのプラットフォームです。この融合により、業務部門は、データの洞察を直感的に理解し、新しいビジネス仮説を立て、戦略立案や施策実行をより効果的に行うことができます。


