dotData Feature Factoryは、企業のキュレーションされたデータ(すなわち特徴量)を開発するために、データ加工に関するノウハウを再利用可能なアセットとして蓄積する仕組みを提供し、企業におけるデータの扱い方を根本的に変えるものです。データ中心に自動構築される特徴量空間から、アルゴリズムによってデータに隠れたパターン(特徴量)を発見し、特徴量発見のスピードと効率、再利用性と再現性、専門家間の連携、品質と透明性を向上します。dotData Feature Factoryは、企業データのサイロ(縦割り構造)を破壊し、データから最大限の価値を引き出します。
特徴量が企業のデータの価値を最大化
特徴量エンジニアリングが全てのデータ活用、AI開発を強化
特徴量の発見と設計は、職人芸とも言える、経験と勘による手作業が中心で、属人性が高く、また大きな工数のかかるプロセスです。dotData Feature Factoryは、特徴量エンジニアリングをデータ中心のアプローチへと進化させます。特徴量空間をプログラム的に定義することで、手作業では不可能な圧倒的に広い範囲の特徴量仮説を自動生成し、ユーザーのデータや業務に関する知識を再利用可能なプロセスとして分析データベースに記憶します。また、発見した新しい特徴量を、本番環境で利用可能な特徴量パイプラインを自動生成し、目的別に加工されたデータ(特徴量)を供給するハブとして、データ活用、AI開発、ビジネスインテリジェンス(BI)といった、全てのデータアプリケーションを強化します。

製品の特長
dotData Feature Factoryは、独自の特徴量エンジアリングによって、企業のデータ加工のノウハウを再利用可能なアセット化し、業務データに隠れたビジネスのパターンの発見します。企業に蓄積されている大量のデータを、効果的にビジネスインサイト(洞察)に変換し、データドリブンな意思決定を実現します。
複数ソース、複数テーブルの
特徴量設計
dotData独自の特徴量自動設計技術が、ターゲットテーブル(目的変数)、ソーステーブル(入力テーブル)、テーブル間の関係(エンティティリレーション)を指定するだけで、数値、カテゴリ、時系列、テキスト、地理空間などのマルチモーダルなデータセットから、機械学習モデルの予測力を高め、ビジネスインサイト(洞察)をもたらす新しい特徴量を発見します。
特徴量設計を再利用可能な
アセット化
スキーマやエンティティリレーションといったデータのメタ情報、データクレンジングなどの前処理、データ加工と特徴量変換の全てのステップを分析データベースへ記録し、特徴量に関する「ノウハウ」を再利用可能なアセットとして蓄積し、組織やチームでのデータ活用やAI開発の生産性を圧倒的に向上します。
データ加工&
データクレンジング
不正なデータ値、欠損値、外れ値、カテゴリ値の正規化、レコードの重複などを自動的に検出し、ソースデータをクレンジングします。これにより、時間がかかり、またエラーが発生し やすいデータ加工の作業を最小化し、特徴量と予測の品質を最大化します。
既存のPython環境、Python
エコシステム上で利用可能
dotData Feature Factoryは、Jupyter Notebook、Databricks、Azure Machine Learning Studioなど、ユーザーが利用しているPython環境上にインストール可能で、データフレームなどの標準的なインターフェースを通じて、既存の分析環境を変更せずに利用できます。
企業データにおける
スケーラビリティ
dotData Feature Factoryは分散計算技術によって、大規模データに対するスケーラビリティを備えて構築されています。これにより、数十のテーブル、数千の列、数 十億の行を処理することができます。企業の大量のデータを処理をする際に、高度な分散計算技術で通常必要となる煩雑な設定や調整は必要ありません。
本番品質の特徴量パイプライン
を自動生成
dotData Feature Factoryで設計された特徴量は、本番品質・スケーラビリティをもった特徴量パイプラインを自動生成可能です。分析環境で発見した価値のある特徴量を、直ちに本番環境で運用することができます。
利用のステップ
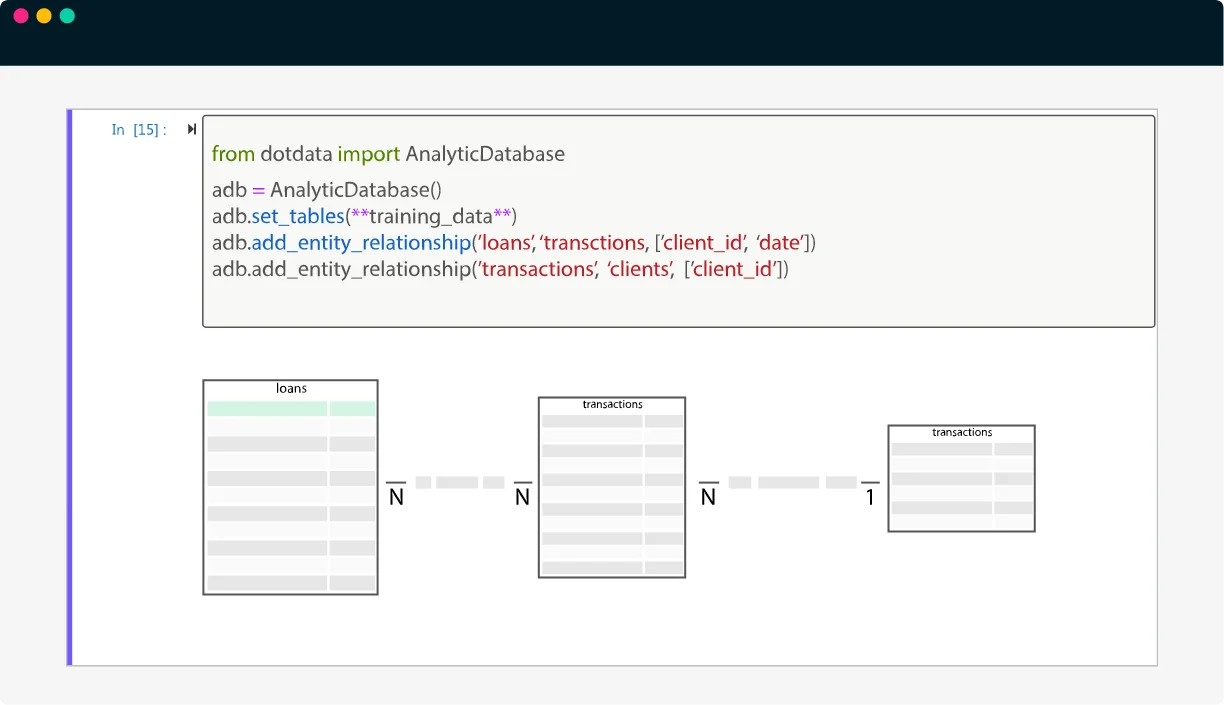
複数のデータソース、データレイク、データウェアハウスに接続し、データフレームとしてデータを準備
- クラウドのデータストレージ(Amazon Redshift、Google Big Query、Snowflake、MS Azure Synapseなど)、データウェアハウス(Oracle、Teradata、MS SQL Server)、ローカルファイルからPythonのデータフレームとしてデータをロード
- データフレームを「分析データベース」へ設定し、データ型の自動検出とデータスキーマの自動推論
- データフレーム間の関係(分析エンティティ・リレーション)を定義し、複数テーブルを接続
- 時間方向に特徴量を探索するためには、時間エンティティ・リレーションを利用
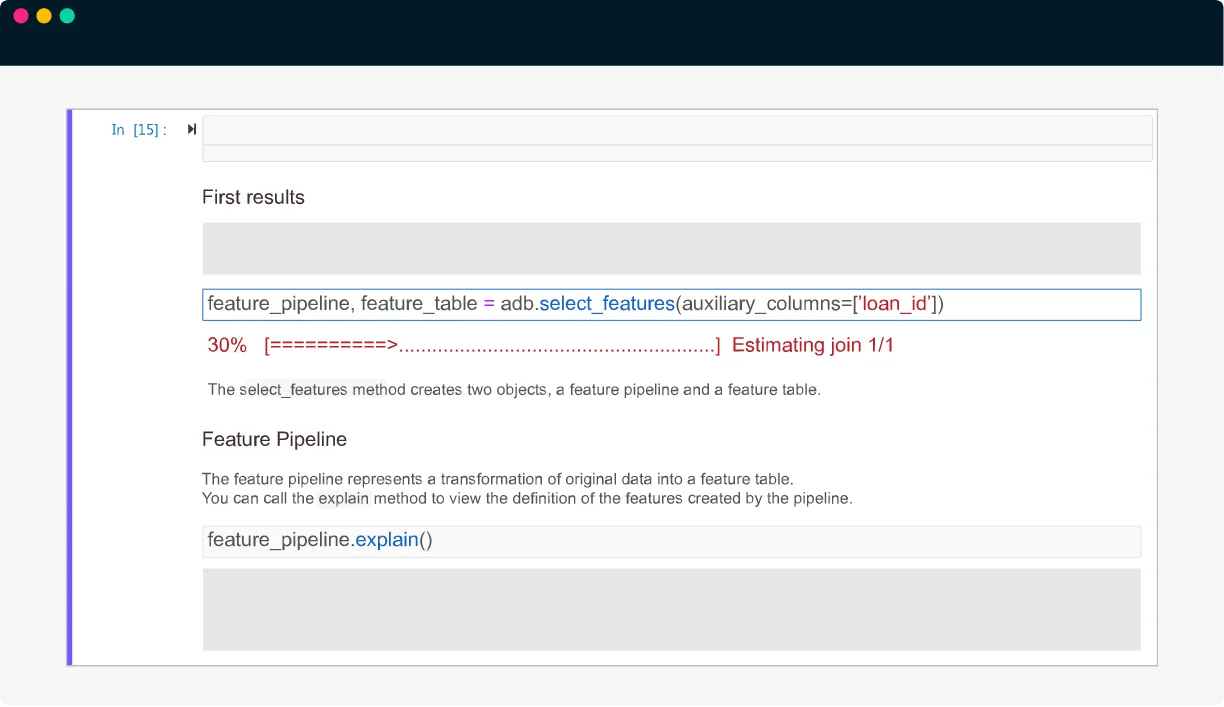
ターゲット変数と特徴量の探索元となる(複数の)ソーステーブルを指定し、dotData Feature Factoryを実行
- 分析データベースの情報から、dotData Feature Factoryが自動的に作成可能な特徴量を「特徴量空間」として構築
- 不正な値や外れ値の処理、データの正規化、欠損値、ターゲットラベルのマッピングの誤りなど、データを自動的にクレンジング
- dotData独自のアルゴリズムに基づいて数値、カテゴリ、時系列、テキスト、空間データから、数百万もの特徴量仮説を生成・探索し、特徴量の過学習、共線性、ドリフト、冗長性などの問題を解決
- 特徴量空間と探索基準をカスタマイズし、独自のドメイン特徴量を追加
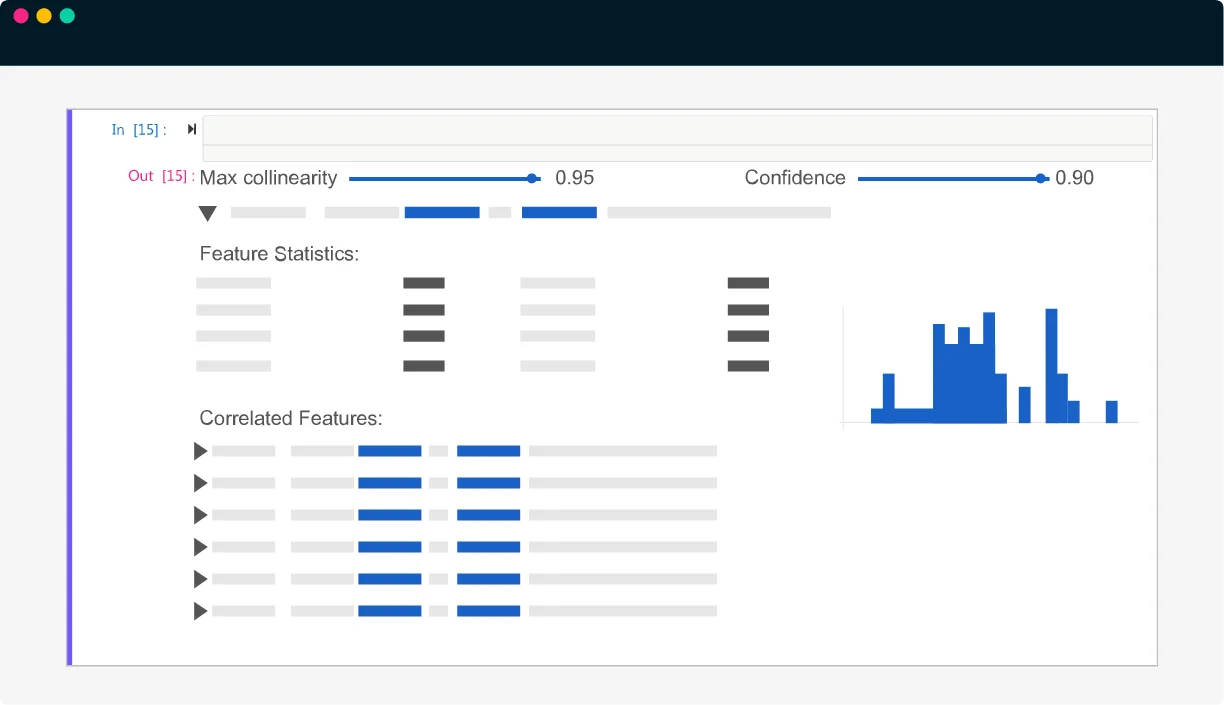
特徴量を探索的に評価しながら、目的にあった特徴量を発見
- 特徴量のリーダーボードにより、ターゲット変数と最も関連性が高く、安定した特徴量を確認
- 自動生成された特徴量の説明文により、各特徴量の意味を定性的に理解
- 相関係数、特徴量ごとのAUC、特徴量重要度、局所性などに基づいて、特徴量を定量的に理解
- 特徴量テーブルをデータフレームとして抽出し、組み込みの可視化ツールまたは任意の可視化ライブラリを使用して各特徴量を可視化
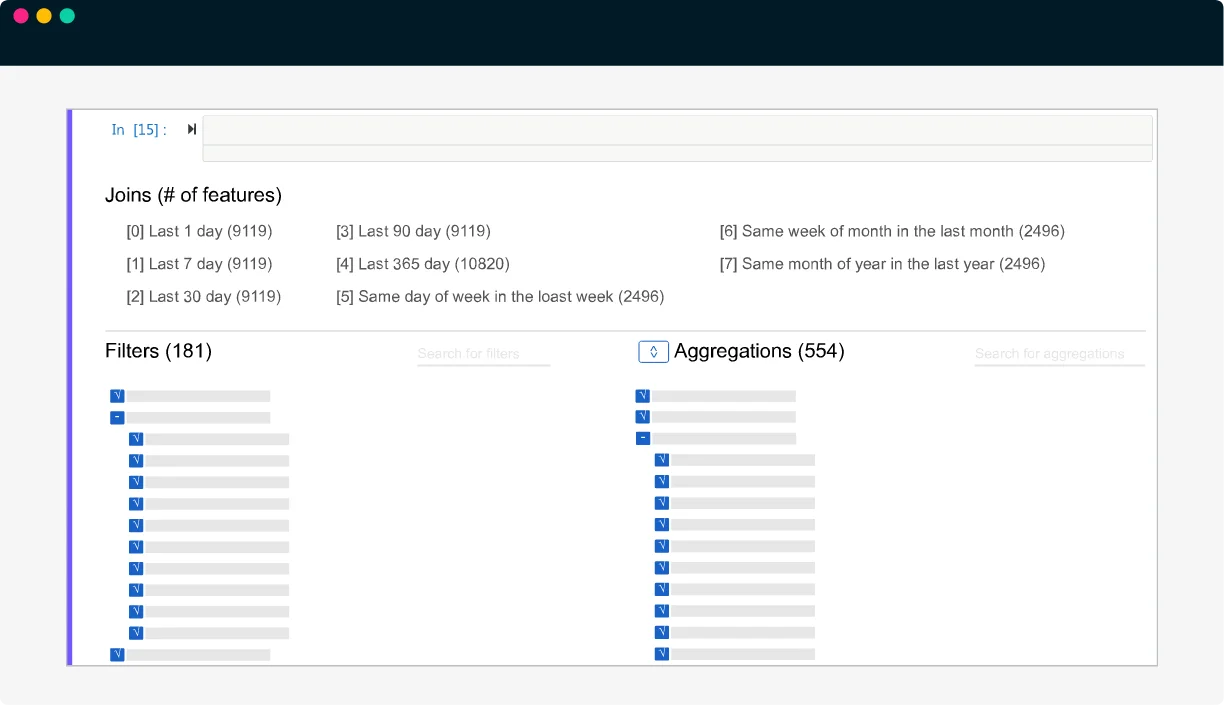
dotData Feature Factoryを用いて特徴量をさまざまな角度から繰り返し抽出し、高品質かつ高次の特徴量を発見
- 発見した特徴量を、ドメイン知識に合うように書き換えカスタマイズ
- データを追加して、新たな実験を実行。複数の実験から得られた特徴量を組み合わせ
- すべてのデータ変換の手順と特徴量空間の詳細がブラックボックス化されることなく確認可能
- モジュール化された実行により、任意のステップから実験を開始し、検証を繰り返す
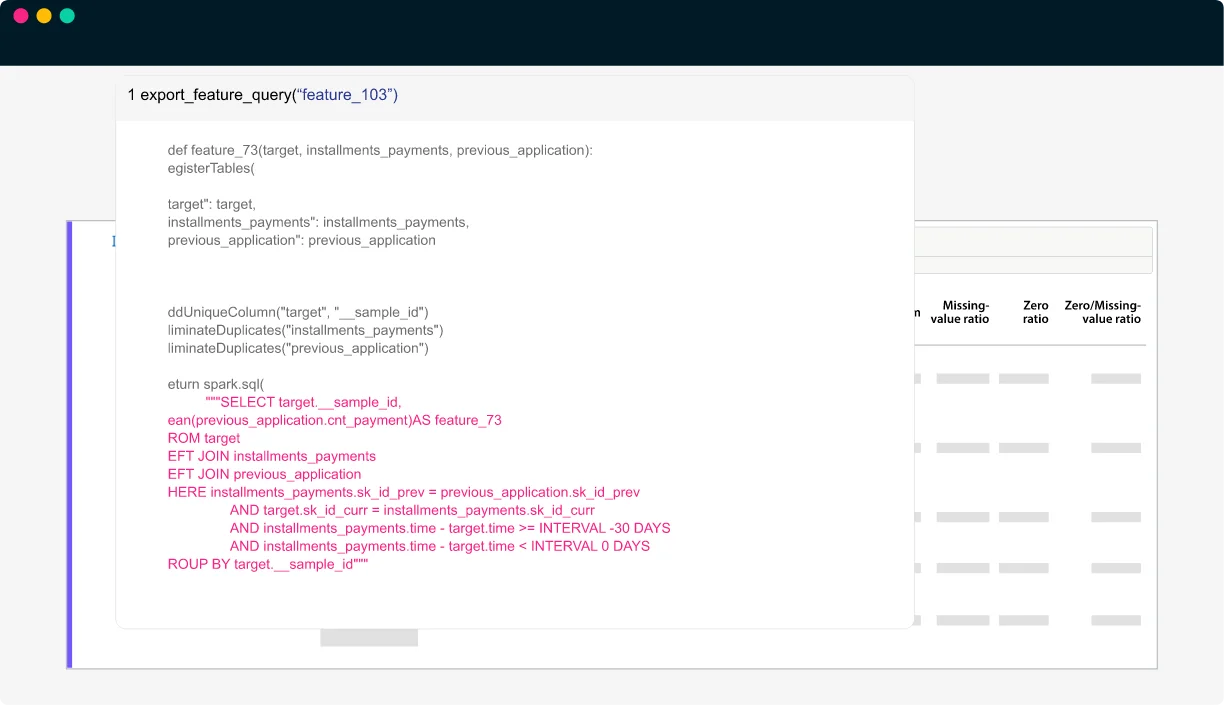
本番品質の特徴量パイプラインを生成・蓄積し、継続的に
アップデート
- 特徴量とその説明文、メトリック、スキーマを、Databricks、Snowflake、AWS SageMakerなどの特徴量ストアへとエクスポート
- 特徴量パイプラインを自動生成し、手動の特徴量クエリの実装が不要
- 特徴量パイプラインをワンコマンドでdotData Opsに展開し、最新のデータで特徴量を再計算し、特徴量の品質とドリフトを監視することで、特徴量の品質を確保
デプロイメントオプション
Jupyter Notebook
dotData Feature Factoryを、データサイエンティストの最も標準的なPython環境であるJupyter Notebook上にインストールして利用
Databricks
dotData Feature Factoryを、Databricksの機械学習ワークベンチへ統合
Azure Synapse Analytics / Azure Machine Learning
dotData Feature FactoryをAzure Synapse AnalyticsやAzure Machine Learning上のPython Notebookに展開して特徴量を探索
Amazon EMR
dotData Feature FactoryをAmazon EMRをバックエンドとしてスケーラブルに実行
Pip Install
dotData Feature Factoryをpipインストール。ノートパソコンやローカルサーバー上でも動作
お客様の声
Sticky.io
全体の95%の時間がデータラングリング(前処理)に費やされ、プロセスの最後のわずか5%のみを自動化することに価値を見出せませんでした。今ではその作業のほとんどがdotDataによって自動化されたので、素早く試行を繰り返し有用なモデルを見つけることに注力できるようになりました。
株式会社JALエンジニアリング
dotDataによって、整備士・エンジニアの知見に基づく仮説検証型分析では見い出すことができなかった不具合の予兆につながる新たな特徴量を作成することが可能になりました。
株式会社ローソン
特徴量から炙り出される消費者の価値観によって、商品の魅力を最大限に伝えることができるようになり、店舗の売上向上につながっています。
ユースケース


ニュース
プレスリリース
dotData、AIによる特徴量設計を強化し、LLM対応を拡充したdotData Feature Factory 1.3を発表
プレスリリース
dotData Feature Factory 1.2を発表 – Snowpark上の特徴量自動設計がSnowflakeのデータの価値を最大化を実現
プレスリリース
dotData、生成AI搭載のdotData Feature Factory 1.1を発表
プレスリリース
dotDataが「dotData ビジネスアナリティクス人材育成サービス」を発表
プレスリリース
dotData Feature Factoryにより隠れた特徴量を探索し、Azure Machine Learning上での機械学習を強化
プレスリリース
dotData、企業データを革新する「dotData Feature Factory」を発表
dotDataのAIプラットフォーム 特徴量がデータ活用の成否を決める
dotDataは、独自の特徴量自動設計技術をコアとして、機械学習でAIモデルを構築する、特徴量をアセットとして蓄積しデータを強化する、データインサイト(洞察)を抽出して業務をデータドリブンに変革するといった、様々なシーン毎に最適なAIプラットフォームを提供し、データ活用、AIによるビジネスのDXを支援します。
お問い合わせ・
資料ダウンロード
気軽に話を聞いてみたい、ユースケースを知りたいなど、お客様のニーズに合わせてサポート致しますので、まずはお気軽にお問い合わせください。また、資料ダウンロードもご利用ください。
よくある質問
dotDataの考える特徴量エンジニアリングとは、「業務データから目的にあったパターンを発見し、データ加工、変換するプロセス」です。例えば、解約分析において、「お客様の解約のトリガーとなる行動」が特徴量に対応します。特徴量は、可視化分析と組み合わせたデータ駆動の戦略立案、ビジネスシステムと組み合わせた施策実行、機械学習モデルやAI開発のための入力データ作成など、全てのデータアプリケーションは特徴量が基点になるといっても過言ではなく、企業のデータ活用の根幹となる概念です。
dotDataの特徴量自動設計は、ディープラーニング(深層学習)のような高次元のブラックボックス化された特徴量とは異なり、説明性の高い特徴量に絞って探索を行います。これによって、業務部門が特徴量を通じた予測結果を理解し、またデータを活用してビジネスインサイト(洞察)を発見することを支援します。また、dotDataは、ディープラーニングが扱うことができない、複数表を直接入力として、業務データを直接探索することで、よりよい特徴量を探索することができる点も、大きな利点です。
dotData Feature Factoryは、入力されたテーブルに対して分析観点でのデータ品質のチェック機能があり、データ品質が低い場合には、ユーザーにその理由を通知し、欠損値、外れ値などの、一般的なデータクレンジングは自動的に実行されます。また、分析データベースに対して、カステむのデータ前処理を記録することで、同じデータに対して、誰が実行しても、いつでも同じ前処理を適用することができます。
dotDataは、主に企業の業務データ(ファーストパーティーデータ)から特定にビジネスの目的に対応する特徴量を通じて、数値やカテゴリ、テキストなど様々なデータからの知識や知見を発見します。一方で、生成AIは、世の中に存在する大量のデータを目的を限定せずに大規模言語モデルとして学習し、いわゆる「世界知識」によって、非常に汎用的な質疑応答を実現したり、業務知識を読み込ませることで、特定目的に特化した要約や質疑を得意とします。dotDataと生成AIは、得意なデータや知識に違いはありますが、どちらも特化型AIであり、dotDataと生成AIを組み合わせることで、より高次のデータインサイト(洞察)を導き出すことが可能です。





