Databricks上にdotDataをデプロイすることで、データレイクハウスとして統合的に蓄積・管理されたデータから、dotDataのAIが経営や業務を改善するためのパターン(特徴量)を発見します。BIツールのような直感的で使いやすいインターフェースを通じて、業務部門が自らデータからインサイトを導き出し、営業、マーケティング、サプライチェーン、リスク、製造、人事など、企業のあらゆる業務におけるAIとデータ分析のユースケースの開発を加速し、Databricksに蓄積されたデータの価値を最大化します。
dotData x Databricks
dotDataのAIがDatabricksの
データレイクハウスを革新
Databricks上のdotDataが、
企業のAI・データ分析を加速します。
AIによる深い洞察がDatabricksに蓄積された
データの価値を最大化

dotDataのAIが
AI Ready Dataを生成
Databricksのレイクハウスには、品質と準備の段階に応じて、ブロンズ(生データ)、シルバー(汎用的に整理)、ゴールド(利用目的に応じて集約)の段階に応じてデータが蓄積されます(メダリオン・アーキテクチャ)。dotDataのAIは、汎用的に整理されたシルバーデータから、ゴールドデータを自動生成し、生成AI、機械学習、ビジネスインテリジェンス(BI)へ供給します。dotDataが生成する目的別に最適化されたゴールドデータによって、分析精度の向上や工数の削減と短期化に加えて、常に最新のデータ断面からビジネスインサイトを提供し、データドリブンな意思決定を加速します。
Databricksのデータガバナンスとの完全な統合
dotDataをDatabricks上にデプロイすることで、Unity Catalogによるデータガバナンスとの統合を実現します。Databricksからデータを移動することなく、厳格なガバナンスとコンプライアンスを維持したまま品質の高い目的別のデータマートをAIによって自動生成し、dotDataによるビジネスアナリティクスはもちろん、新規顧客獲得、商品需要予測、顧客LTV向上、経営KPI要因分析、不正検出、離職防止といったアプリケーションを強化し、ビジネスユースケースの開発を加速します。これによって、業務部門におけるAIとデータ分析をスケールさせながら、確実なデータガバナンス下で共通のデータ資産を安心して活用し、データ民主化を実現します。
dotData x Databricksの特長
dotData Feature FactoryとdotData InsightをDatabricks上に直接デプロイし、Databricks上で統合された蓄積(ストレージ)、処理(コンピュート)、管理(ガバナンス)で、dotDataのAIが業務部門が主役のデータ分析を実現します。
Unity Catalogとの統合
Databricks上のdotData Feature FactoryとdotData Insightのデータ管理はUnity Catalogと統合されます。これによって、データを複数環境にコピーすることなく、統合されたデータガバナンスの元でdotDataのAIを最大限活用することができます。
AI Readyデータを
dotDataのAIが生成
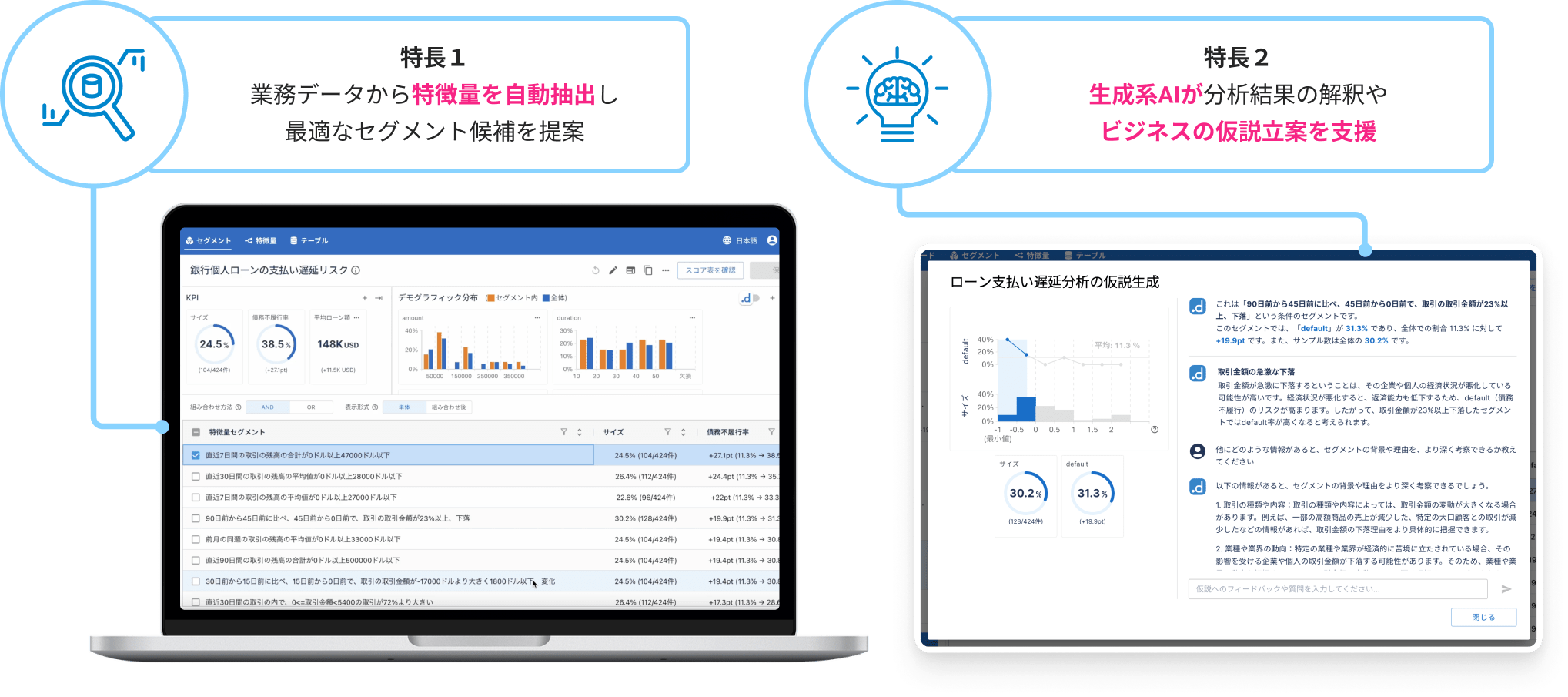
dotDataのAIが、目的変数に応じて、多種多様な業務データから、自動で数十万から数百万ものパターンを探索し、生成AIにコンテキストを提供し、機械学習モデルの予測力を高め、ビジネスインサイト(洞察)をもたらす特徴量(AI Readyデータ)を生成します。
構造・非構造データから
インサイトを抽出
基本的な数値データやカテゴリデータだけではなく、時系列データ、トランザクションデータ、さらにはテキストのような非構造データも統合して分析します。この多様な構造化・非構造化データソースから、マルチモーダルなパターンを発見し、新たなインサイトを提供します。
特徴量ストアとの連携
dotData Feature Factoryが生成する特徴量はDatabricksの特徴量ストアと連携可能です。目的別の特徴量をストア化し、肥大化・レガシー化した特徴量ストアから脱却。機械学習モデルの精度改善、分析チームのトライアルアンドエラーの高速化、最新データからのビジネスインサイトの発見を実現します。
業務部門が主体の
ビジネスアナリティクス
dotData Insightは、BIツールのような直感的で使いやすいノーコードのGUIに基づいて、要因や特徴を分析することができます。これによって、業務部門は、Databricks上のデータから自らインサイトを導き出し、新しいビジネス仮説を立て、データドリブンな戦略立案や施策実行を強化することができます。
ユーザー環境に
直接デプロイ可能
dotData on Databricksは、顧客環境のDatabricks上に直接dotData Feature FactoryとdotData Insightをインストールし、利用できます。これによって、データを自社環境から動かすことなく、自社のセキュリティ環境下で、dotDataの最先端のAIを利用することができます。
様々な業界でのユースケース
dotDataの製品は、顧客のペルソナ分析やLTVの向上、商品の需要予測、解約防止、製造工程の効率化、製品の品質向上、サプライチェーンの最適化、リスク管理、従業員採用や定着率の向上、パフォーマンス評価など、さまざまな業務目的に対してビジネスインサイトをAIが抽出し、企業におけるAIとデータの活用を民主化します。

営業の商談成功要因分析
株式会社大塚商会
大塚商会は、dotDataを活用したAI(人工知能)を導入して、営業活動の効率化を推進しています。20年以上にわたる販売やサポートなどのビッグデータを基に、商談につながる特徴を自動的に抽出。市場や顧客のニーズを的確につかみ取り、営業担当者のスケジュールに落とし込んで商談先を提案する「AI行き先案内」で活用しています。営業担当者に最適な商談先を提案できることからAIの活用により、半年で7万件以上の商談を提案。商談数が3倍増と生産性も上がりました。

消費者のペルソナ分析とターゲティング
株式会社ローソン
約1万5000店舗のコンビニエンスストアを展開するローソンは、購買者に合わせた商品の販促システムを構築するためにdotDataを導入。Cookieレス時代に向け、ID-POS(購買者IDに紐づくPoint-of-Sales)データおよび購買者の価値観分類から特徴量を抽出。広告デザインを購買者の価値観に合わせて最適化することで、購入率が12倍も向上しました。dotDataにより抽出された特徴量は、購買会員のLTV向上による店舗の売上改善などの自社利用に加えて、取引先メーカー向けのマーケティング活動や商品開発などにも活用されており、ローソンだけにとどまらないメリットを生み出しています。

製造プロセス分析・品質改善
横浜ゴム株式会社
世界有数のタイヤメーカーである横浜ゴムは、半世紀以上にわたり革新してきたものづくりの技術をさらに飛躍させるためにdotDataを導入しました。dotDataの特徴量自動設計技術を活用することで、試作評価データから設計因子やプロセス因子を抽出。従来は経験や勘に頼っていたゴム混合工程やスタッドレスタイヤの氷上性能に影響する要因を特定することができました。その結果、物性値や性能の安定性が大幅に向上し、試作前から設計因子を見通せるようになり開発効率も改善。今後は領域を広げ、さまざまな課題解決を目指してdotDataの活用を推進されています。

金融 x リテールデータの融合
株式会社セブン銀行
全国に約27,000台以上ものATMを展開するセブン銀行は、金融行動と購買行動を組み合わせた新たな分析を実施するためにdotDataを導入。セブン&アイグループが保有する購買データを活用し、dotDataの特徴量自動設計技術によって、カードローンのマーケティングや与信審査を高度化しました。高度なデータ分析スキルがなくても、誰でも高精度なデータ分析が行えるdotDataを用いることで、ビジネス部門も分析の背景を直感的に理解でき、施策立案のスピードが向上。その結果、顧客獲得単価(CPA)は従来の2分の1に削減されました。さらにこの分析を推進し、新たな金融ビジネスの創出を目指しています。
dotData Insight
dotData Insight は、業務部門が主役のデータ分析のツールであり、データサイエンティストのような高度な AI の知識やスキルがなくても、業務データからビジネスの目的に応じたインサイトや仮説を導き出すことができます。dotData の AI と生成 AI の融合によって、ビジネスの現場主導のデータドリブンな意思決定を実現しましょう。
ニュース
プレスリリース
dotData、Databricksとネイティブ統合した「dotData Insight 2.0」を発表
プレスリリース
dotData、AIで“意味”を抽出するテキスト特徴量化ツール「dotData TextSense」を発表
プレスリリース
dotData、「dotData Feature Factory 1.4」、「dotData Ops 1.5」を発表
プレスリリース
dotData、AIによる組み合わせ要因探索、Snowflake/Salesforceコネクタ、セキュリティ等を強化した「dotData Insight 1.4」を発表
プレスリリース
dotData、企業の営業やマーケティングをデータ・ドリブンに革新する「dotData Insight for Salesforce」を発表
よくある質問
dotDataとDatabricksを連携する利点は、主に3点あります。1点目は、Databricksに蓄積されたデータから特徴量を抽出。AIや機械学習といったアプリケーションに品質の高い入力データを提供し、推論や予測の精度を高める点です。2点目は、dotData Insightによって、顧客のペルソナ分析やLTVの向上、商品の需要予測、解約防止、製造工程の効率化、製品の品質向上、サプライチェーンの最適化、リスク管理などの様々なユースケースを業務部門が主体となって実施可能となる点です。そして、3点目かつ最大の利点は、このようなdotDataのAIをDatabricks上のデータガバナンスの管理下で、データサイロを解消し、統合データ分析プラットフォームとして利用できる点です。
DatabricksのAI BI DashboardやGenie、機械学習などの機能を利用するには、可視化、視覚化すべきデータマートや、説明変数となる特徴量テーブルを入力として準備する必要があります。従来のプロセスでは、Spark SQLなどを駆使して、スキルの高いデータサイエンティストやデータエンジニアがETLパイプラインやクエリを記述し、これらのテーブルを作成するデータエンジニアリングを実施する必要があります。dotData Feature FactoryやdotData Insightを使用し、これらの入力データをdotDataのAIが生成し、dotDataによって用意された特徴量によって、AI BI DashboardやGenie、機械学習を強化することができます。
データ準備やデータ前処理には、汎用の処理、目的別の処理があります。前者(汎用)は、マスターデータマネージメントと呼ばれ、業務データを企業として整理、管理、蓄積するプロセスとなり、dotDataのAIプラットフォームは、前処理やクレンジングなどの一般的なデータ処理には対応していません。一方で、汎用のデータ準備や前処理が完了した業務データに対して、例えば、ある製品を購入するお客様の特徴を知りたい、あるサービスを解約するお客様を予測したいなどの目的ごとにデータの前処理、加工、クレンジングが必要となり、dotDataはこの工程を自動化し、目的に対応したデータのパターンを発見します。
dotData Feature Factoryは、Databricks Notebook上で動作するPythonのライブラリとしてインストール可能です。そのため、既存のDatabricks Notebook環境と分析のワークフロー上で利用することができます。dotData Insightは、Webアプリケーションとして、データの蓄積(ストレージ)、処理(コンピュート)、管理(ガバナンス)がDatabricksと統合されます。ノーコードのGUIから簡単なクリック操作のみで分析を実行可能で、業務企画部門や戦略部門のような、データドリブンな戦略や施策の立案と意思決定を担うユーザーを想定しています。
dotDataの特徴量自動設計は、Apache Sparkによる分散計算によるバッチ処理を使用して、データレイクやデータウェアハウスに蓄積された大量データを処理し、データサイエンスによる機械学習ワークフロー、大規模言語モデルによる生成AIアプリケーション、要因探索に基づくビジネスアナリティクスを実現します。大規模なデータを参照し、網羅的に特徴量のパターン探索し、最先端の生成AIと連携することで、エンタープライズにおけるデータインテリジェンスプラットフォームとしての機能を提供します。
Databricksとは?
Databricksについて学ぶ

Databricks AI + Data Summit 2025レポート – AIエージェントからLakehouseまで、未来のデータ活用とは
Yukitaka Kusumura, Ph.D.

