
Databricksの特徴量ストア(Feature Store)とAutoMLの力を最大限に活用
- 特徴量
- AutoML
- 時系列データ
- 機械学習
- データ分析
- AI開発
DatabricksのAutoMLと特徴量ストアとは、Databricksのエコシステムにおいて重要な組み合わせで、データサイエンスと機械学習の分野に革新をもたらします。このブログでは、これらのツールの基本を解説し、これらが機械学習モデルのトレーニングと管理を簡単にするだけでなく、効率的でスケーラブルにする方法を見ていきます。また、DatabricksとdotData Feature Factoryの統合について深く掘り下げ、そのメリットを理解し、データサイエンスプロジェクトで効果的に活用するための実践的なヒントとステップを紹介します。
Feature Store(特徴量ストア)は、複数のモデルにまたがる機械学習の特徴量の検出し、一元的に管理、共有するためのリポジトリを提供します。特徴量を簡単に保存、検索できる統一的なインタフェースを提供することで、データサイエンティストの特徴量エンジニアリングを効率化します。Databricks Feature Storeは、統合されたDatabricksのエコシステムの一部であり、DatabricksおよびdotDataを使用する際に、さまざまな利点をもたらします。Feature StoreはDatabricksの他のコンポーネントと完全に統合されているため、ツール間の連携がスムーズです。例えば、DatabricksのワークスペースからアクセスできるFeature StoreのUI(特徴量を管理するためのインターフェース)は直感的で、既存の特徴量をブラウズまたは検索できます。これにより、データサイエンティストは既存の特徴量を迅速に見つけて再利用でき、新たな特徴量の開発を効率化することができます。
また、モデルのスコアリングとサービングとも統合されていることもメリットの1つです。モデルのトレーニングに使用される特徴量がFeature Storeから選択されると、そのモデルは特徴量メタデータと関連付けられます。バッチスコアリングやオンライン推論の操作中に、Feature Storeから必要な特徴量を自動的に取得します。これにより、運用する側は特徴量について気にする必要はなく、簡単にモデルのデプロイや更新ができます。
さらに、Databricksは各特徴量の正確なリネージを保証します。このリネージ機能により、特徴量の元となるデータソースだけでなく、特徴量を使用する全てのモデル、ノートブック、ジョブ、エンドポイントにアクセスできるようになります。ユーザーが特徴量の依存関係やプロジェクトでの使用状況を確実に把握できるように、リネージによってデータの透明性を高めることができます。
Databricks AutoMLは、モデル学習に直感的なアプローチを採用し、回帰、分類、予測など、それぞれの問題に合わせて多様な機械学習アルゴリズムに基づいてモデルを学習、評価します。これには決定木 、ロジスティック回帰 、アンサンブル学習などが含まれます。そして、モデルの評価では、再現率や平均二乗誤差(MSE)といったさまざまな評価指標が表示され、各モデルのパフォーマンスを比較できます。各モデルにはPythonノートブックが添付されています。そのため、どのようにモデルが学習され評価されたのかソースコードを確認することができ、機械学習プロセスを確認、再現、修正できることで、機械学習プロジェクトの透明性が高まります。さらに、データセットの全ての統計量サマリ は、後の詳細な分析のために保存されます。このように、複数のアルゴリズムでモデルを生成し、それぞれのパフォーマンスを比較でき、さらにモデル学習に利用したデータの特徴を視覚的に理解できるため、より信頼性の高い意思決定が可能となります。
Databricks AutoMLでは、データセット内の数値、二値、カテゴリ値の変数を処理することができます。Databricks AutoMLは柔軟なデータ分割オプション、たとえばランダム分割、時系列分割、手動分割などを提供し、分析の性質に応じて、データを学習用、評価用、テスト用に分割し適用することができます。また、大規模なデータセットに対しては、学習に必要なメモリを自動推定し、必要に応じてデータの整合性を損なうことなくサンプリングを行い、メモリ不足によるエラーを防止することができます。さらに、Databricks AutoMLは不均衡なデータセット(たとえば正例と負例の比率が1対99のようなデータ)に対して、主要クラスをダウンサンプルし重みを追加することで、不均衡なデータセットの問題を解決し、バランスの取れた学習とロバストなモデルを実現します。
特徴量エンジニアリングは機械学習パイプラインの重要なステップであり、モデルを構築するために、生データを前処理し学習に適した形式に変換するプロセスです。Databricksでは、Spark SQLとSpark DataFramesを使用することで、このプロセスを大幅に強化することができます。
Spark DataFramesはpandas DataFramesに似ていますが、分散処理を前提として設計されており、大規模データに対してより高いパフォーマンスを発揮します。また、データ操作、集約、変換のための関数を豊富に提供します。Spark DataFramesは、名前付きのカラムでまとめられるデータの分散型コレクション(データを分散して格納し、並行処理を行うことで大規模データセットを効率的に処理する仕組み)です。概念的にはリレーショナルデータベースにおけるテーブルや、RやPythonにおけるデータフレームと同じものですが、内部ではさまざまな最適化が行われています。Spark DataFramesは幅広いデータフォーマット(CSV、JSON、Parquetなど)やデータソース(構造化データファイル、Hiveテーブル、外部データベース、既存のRDDなど)をサポートしており、多様なデータセットに対応できます。このSpark DataFramesをDatabricks Feature Storeと組み合わせて利用することで、スケーラブルで効率的なデータ処理を可能にし、特徴量エンジニアリングのプロセスを迅速に進めることができます。
Spark SQLは、データを使用しSQLとして操作するための機能を提供し、Dataframeに展開されたデータに対して、データの操作や分析が直感的かつ効率的に行えます。Spark SQLは分散処理を利用して大規模なデータセットに対して高速にクエリを実行でき、データ分析や処理の効率を大幅に向上させます。Spark SQLをDatabricksに統合することで、使い慣れたSQL構文を使用して簡単に特徴量を作成できるようになり、生産性が向上します。また、さまざまなデータソースに簡単にアクセスでき、Spark SQLを使って一貫した方法でデータ操作ができるため、データ統合と管理が容易になります。
特徴量の発見はデータサイエンスの重要な要素ですが、従来、ドメインの専門家の知識と、職人芸とも言える経験と勘による手作業と反復作業を必要としてきました。しかし、dotData Feature Factoryは、このプロセスを簡易化する新しいパラダイムを提供します。
dotData Feature Factoryは、異なるデータソース間に対するデータセットの管理を簡素化し、アナリスト、データサイエンティスト、データエンジニアなど、さまざまな背景を持つユーザーの実施するデータ加工に関するワークフローを簡略化します。このように、チーム間の連携を強化し、データを統合することで、大規模なデータもつ企業に対して、オープンでスケーラブルなデータソリューション開発を実現します。
dotData Feature Factoryは、結合、フィルタ、集約など、複数表の組み合わせ通じて特徴量発見プロセスを自動化し、大規模かつ複雑なデータに適用可能です。また、時間的結合を自動的に処理することでデータリーケージを防止し、広大な特徴量空間を効率的に管理します。このように、dotData Feature Factoryは、最適な特徴量を体系的に探索および選択するツールを提供し、ユーザーは特徴量を重要性と関連性に基づいて評価し、モデルを正確かつ容易に調整できます。
dotData Feature Factoryは、Widgetまたはプログラム上から、ユーザーが自身のニーズに合わせて柔軟に特徴量空間をカスタマイズできるように設計されています。これによって、ドメインに特有の要件にしたがう新しい特徴量を探索に含めることができます。dotData Feature Factoryで定義された、データ前処理から特徴量エンジニアリングまでの全ての処理は、「特徴量パイプライン」に変換されます。特徴量パイプラインは、効率と一貫性を重視して設計されており、機械学習モデルやその他のアプリケーションに直接統合することができます。
dotData Feature Factoryは、特徴量エンジニアリングの試行錯誤を再利用能なアセットへと変換し、従来の手作業かつ属人性の高いプロセスから脱却します。これによって、特徴量エンジニアリングは、アドホックな使い捨ての作業ではなく、データドリブンな意思決定を強化するためのアセットを蓄積する重要なプロセスとなります。dotData Feature Factoryは、Databricksを含むさまざまなプラットフォームと簡単に統合できるため、既存のワークフローにシームレスに適合し、データサイエンスチームが企業データを効果的に活用できるようにします。
dotData Feature Factoryは、Databricks内のデータワークフローを自動化および最適化し、スケーラブルな機械学習モデルの構築とデプロイを簡素化します。dotData Feature FactoryをDatabricks Feature StoreとAutoMLと組み合わせてワークフローに組み込むことで、機械学習プロセスの自動化を強化し、高いスケーラビリティと効率性を実現します。
Databricks Feature StoreとdotData Feature Factoryを組み合わせることで、機械学習における特徴量の管理を目的とした、便利で効率的な特徴量ストアが実現します。dotData Feature Factoryで作成した特徴量テーブルは、Delta Lake上に構築されたDatabricks Feature Storeに格納できるので、高い信頼性とパフォーマンスの元、データを管理できます。これらのテーブルの作成はSpark DataFramesから行われ、Feature Storeに登録すると、ソース情報、変換用ノートブック、計算ジョブに関する情報を含むメタデータも更新されます。これにより、学習や推論ワークフロー全体での特徴量データの管理が非常に容易になります。
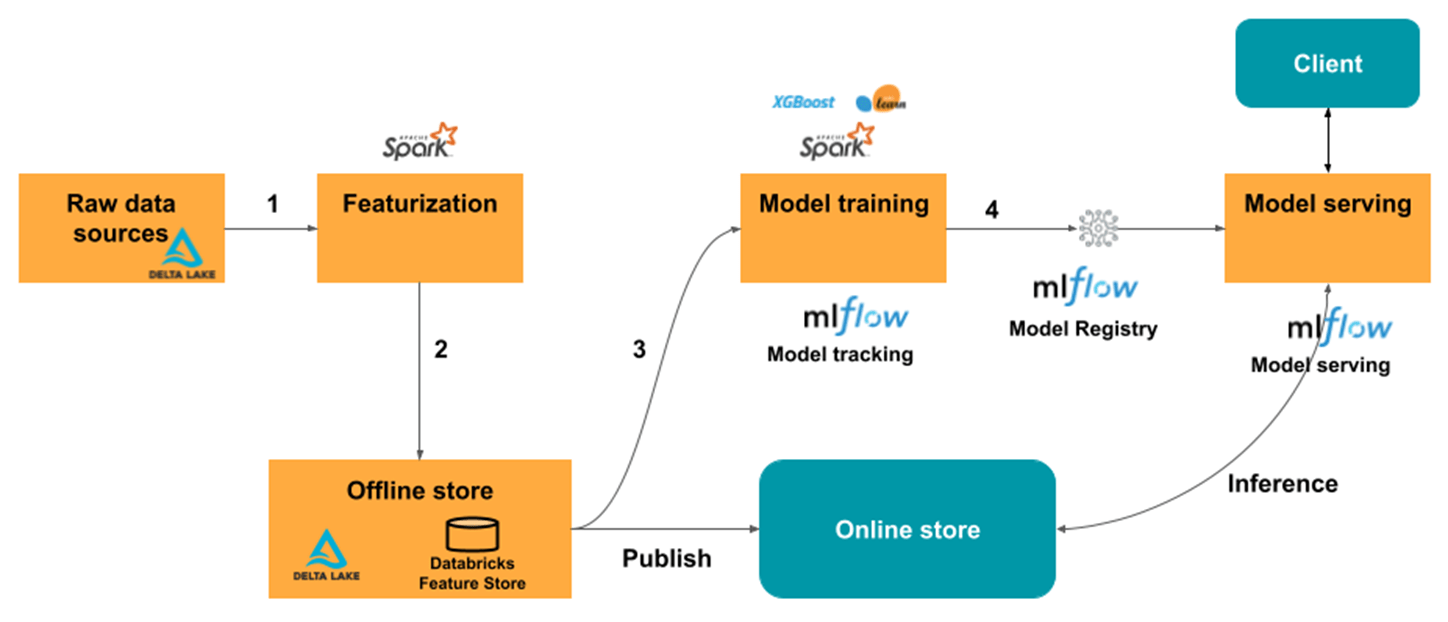
Databricks Feature StoreにはFeatureLookupという、機械学習モデルに必要な特徴量を特定のキーに基づき検索し、結合する機能があります。 この機能を利用することで、複数のdotDataの特徴量テーブルから必要な特徴量を検索し、データセットに結合できます。また、時系列データにも対応可能で、過去の取引履歴やセンサーデータなど、時間軸に沿ったデータを適切に結合し、時系列特徴量を生成することで、データリーケージを防止しながら学習用のデータセットやリアルタイム予測に必要なデータを効率的に取得できます。
このように、Databricks Feature Storeは、再利用可能な特徴量のデータセットを迅速に構築でき、データの一貫性が保たれるため、特徴量エンジニアリングを通じて発見されたデータを使用してモデルの学習、デプロイまで、機械学習のライフサイクルが効率化されます。詳しくは、「Feature Storeとは」を参照ください。
以下に、Databricks Feature Storeを使用して、特徴量テーブルを作成し、FeatureLookupを設定する例を示します。

複数の自動化ツールを統合することで、機械学習モデルの開発とデプロイプロセス全体を自動化することができます。この目的のため、dotData Feature FactoryをDatabricks AutoMLを組み合わせることで、特徴量エンジニアリング、特徴量選択、それに続くモデル選択、ハイパーパラメータ調整のプロセスを自動化します。
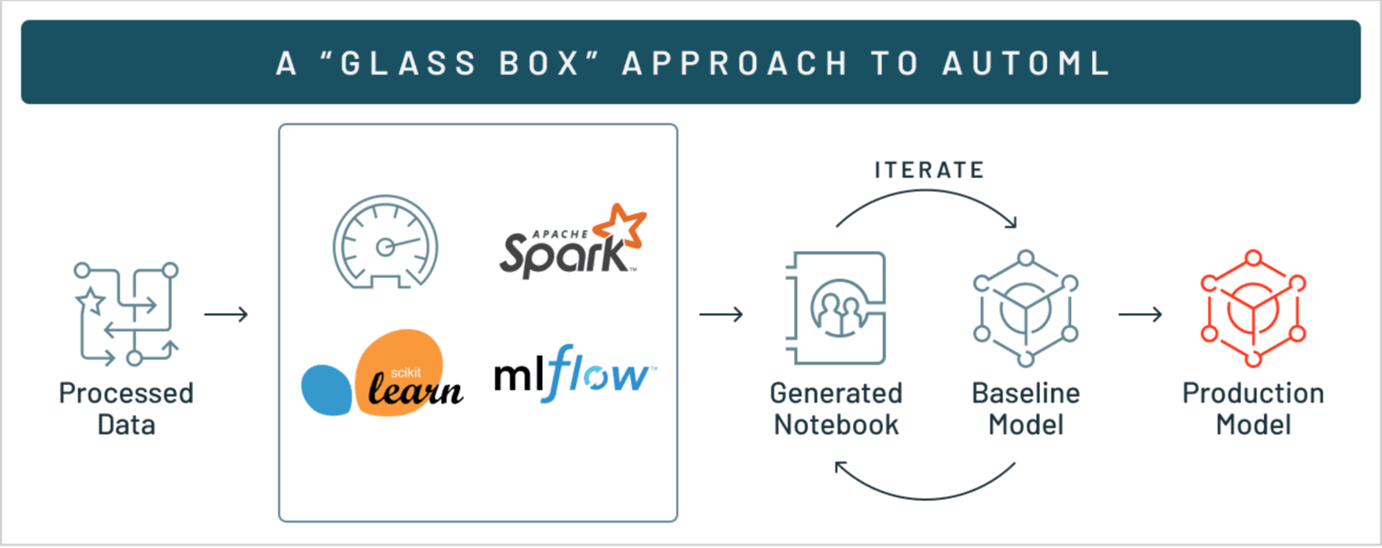
dotData Feature Factoryを活用することで、データサイエンティストは特徴量エンジニアリングを素早く正確に行うことができます。特徴量の抽出と検証を対話的に繰り返せることで、高次の特徴量を導き出すことができます。
dotDataが生成した特徴量テーブルをDatabricks内で利用することで、データの一貫性と再利用性が確保されます。これにより、特徴量エンジニアリングが効率化され、学習データの準備を迅速に行え、モデル開発のスピードが改善されます。
Databricks AutoMLは、モデルの学習と評価を自動化し、dotDataの特徴量を活用することで、より高品質なモデルを構築し、最も効果的なモデルを簡単かつ迅速に選択します。
Databricks AutoMLで生成されたモデルをMLflowにログ(記録)することで、モデルのトラッキングと管理が容易になります。これにより、モデルのバージョン管理や再現性が確保され、実験結果の共有と比較が効率的に行えます。
このように、dotData Feature FactoryとDatabricks AutoMLを統合することで、効率性、モデル精度、ロバスト性、スケーラビリティ、ガバナンスにおいて大きなメリットが得られます。
以下に、Databricks AutoMLを使用して、特徴量テーブルから分類モデルを学習し、予測を実施する例を示します。

dotData Feature FactoryをDatabricks AutoMLとFeature Storeに組み込むことで、機械学習パイプラインの効率が向上するだけでなく、複雑なモデル学習と特徴量エンジニアリングに簡単に対応できるようになります。このワークフローにより、プロセス全体にかかる時間を大幅に短縮できるだけなく、機械学習モデルの精度と信頼性が高まります。
DatabricksのAutoMLの詳細については、Databricks AutoMLの公式ドキュメントを参照ください 。公式ドキュメントでは、Databricks AutoMLが、特徴量の前処理からハイパーパラメータ調整まで、機械学習のライフサイクルのさまざまな段階をどのように簡素化し、自動化するかについて説明しています。
Databricks Feature StoreとAutoMLをdotData Feature Factoryに統合することで、ワークフローの合理化が促進され、機械学習モデルのパフォーマンスが向上します。これらのツールを活用することで、これまでデータサイエンティストが手作業で行ってきた作業を最小限に抑え、モデルの精度を高め、最終的にデータソリューションを市場へ素早くリリースすることができます。
次回のブログでは、Databricks Delta Lake、Unity Catalog、そしてdotData Feature Factoryに重点を置き、企業におけるデータ活用を飛躍させる最新のアーキテクチャを紹介します。詳細につきましては、こちらを参照してください。


