
Databricks DeltaとUnity Catalogを超えて:dotDataのFeature Factoryによるメダリオンアーキテクチャの革新
- 特徴量
- AutoML
- 時系列データ
- データ加工
- 機械学習
- データ分析
データ分析を前提としたデータ管理のアーキテクチャは、メダリオンアーキテクチャのような革新的なフレームワークへ進化しています。このアプローチは、データパイプラインの管理とデータガバナンスの強化に対する体系的な方法を提供します。このブログでは、メダリオンアーキテクチャのコンポーネントとして、特に、Databricks Delta Lake、Unity Catalog、およびdotData Feature Factoryに焦点を当て、企業におけるデータ利活用を圧倒的に加速する、最新のアーキテクチャを紹介します。
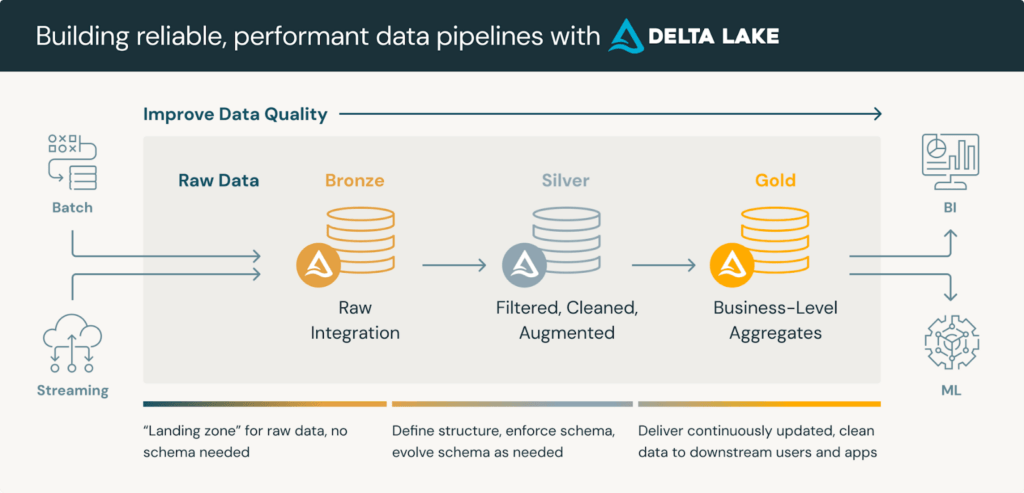
メダリオンアーキテクチャは、データを論理的に整理するためのデータ設計パターンで、アーキテクチャの各層を通じてデータの構造と品質を段階的に向上させることを目的としています。レイクハウスに蓄積された未加工データを、それぞれ特定の機能を持つ3つの異なる層に分割する多層アプローチです:
Delta Lakeは、ACID(原子性、一貫性、独立性、永続性)トランザクションを備えたストレージ層を提供することでメダリオンアーキテクチャをサポートします。また、スキーマの適用とタイムトラベルも提供するため、ユーザーは以前のバージョンのデータにアクセスして戻すことができます。これらの機能により、Delta Lakeは信頼性が高く効率的なメダリオンアーキテクチャの構築に不可欠な要素となります。
Unity Catalogは、一元化されたデータガバナンスとセキュリティを提供し、Delta Lakeを補完します。Unity Catalogは中央集権のガバナンスを提供し、データポリシーを管理および適用するための単一のコントロールプレーンとして機能します。また、きめ細かいアクセス制御も備えており、テーブル、行、および列レベルで詳細なアクセス制御を提供し、データの系統を追跡します。
Delta LakeとUnity Catalogを統合することで、組織はシームレスで安全かつガバナンスされたデータパイプラインを構築し、データのライフサイクル全体を通じてデータの品質と整合性を維持できます。一方で、DeltaとUnity Catalogは、メダリオンアーキテクチャのためのフレームワークであり、シルバーレイヤーのデータから、目的ごとにゴールドレイヤーのデータを作成するには「特徴量エンジニアリング」を実施する必要があります。
メダリオンアーキテクチャからみた特徴量エンジニアリングは、シルバーレイヤーからゴールドレイヤーへのデータ変換に相当します。シルバーデータから、分析やデータ活用の目的に応じた新しい特徴量を作成するプロセスです。このプロセスは複雑で時間がかかることが多く、高品質ですぐに分析できるゴールドレイヤーのデータを作成するための重要なステップです。
特徴量はモデル分析に使用される入力変数であり、特徴量エンジニアリングは、ドメイン知識を使用してデータから特徴量を作成するプロセスです。これらの特徴量には、機械学習による予測モデリングや、ビジネスインテリジェンスによるデータインサイトの発見などに役立つあらゆる属性やプロパティが含まれます。
特徴量エンジニアリングには、次のようなさまざまな課題があります。
特徴量エンジニアリングの例として、scikit-learnのBike Sharing Demandデータセットを使用して、その重要性と影響を説明します。
Bike Sharing Demandデータセットには、気象条件やタイムスタンプに関する情報など、自転車レンタルに関するタイムスタンプ付きデータが含まれています。各時間帯にレンタルされる自転車の総数を予測すると仮定します。この例では、特徴量エンジニアリングを、特徴量抽出、特徴量変換、および特徴量選択に分けて説明します。以下の例は、データをより意味のある特徴量に変換し、機械学習モデルの予測力を向上させるプロセスで、メダリオンアーキテクチャにおけるシルバーレイヤーとゴールドレイヤーを繋ぐステップとなっています。
特徴量抽出のステップでは、モデルの入力となる特徴量をデータから作成ます。時系列データの文脈では、タイムスタンプからデータの時間要素を抽出することを意味します。

この例では、datetime列から時間、曜日、月を抽出し、時間に関連するパターンを捉えるための新しい特徴量を作成しています。
特徴量変換は、既存の特徴量をさらに変換したり、または複数の特徴量を組み合わせたりして新しい特徴量を作成します。特徴量変換では、ドメイン知識に基づいて、データの挙動をうまく表現できる特徴量の変換規則を見つけ出すことがよく行わなれます。

この例では、時間データの周期性をよりよく捉えるために、「時間」のカラムから周期的な特徴量を作成しています。
特徴量選択は、目的と関連性の高い特徴量を選び、モデルをシンプルにし、かつ過学習を防止してパフォーマンスを向上させます。

この例では、目的変数「count」との相関が最も高い上位3つの特徴量を選択しています。
この例は、生データをより意味のある特徴量に変換し、機械学習モデルの予測力を向上させる方法を示しており、メダリオンアーキテクチャにおけるシルバーレイヤーとゴールドレイヤーの橋渡しを実現します。
上記で述べた特徴量を作成における特徴量の加工に加えて、どのような特徴量を作成すべきかを知ること、つまり特徴量の発見や発想が課題として挙げられます。特徴量の発見は、ドメインに対する深い、或いは広い理解を必要とし、多くのケースでは、手作業による反復作業が必要となります。dotDataのFeature Factoryは、このプロセスを簡易化する新しいパラダイムを提供します。
dotData Feature Factoryは、異なるデータソースに対するデータセットの管理を簡素化し、アナリスト、データサイエンティスト、データエンジニアなど、さまざまな背景を持つユーザーの実施する、データ加工に関するワークフローを簡略化します。
dotData Feature Factoryは、結合、フィルタ、集約など、複数表の組み合わせを通じて特徴量発見プロセスを自動化し、大規模かつ複雑なデータに適用可能です。また、時間的結合を自動的に処理することでデータリーケージを防止し、広大な特徴量空間を効率的に管理します。このように、dotData Feature Factoryは、最適な特徴量を体系的に探索および選択するツールを提供し、ユーザーは特徴量の重要性と関連性に基づいて評価し、モデルを正確かつ容易に調整できます。
dotData Feature Factoryは、Widgetまたはプログラム上から、ユーザーが自身のニーズに合わせて柔軟に特徴量空間をカスタマイズできるように設計されています。これによって、ドメインに特有の要件にしたがう新しい特徴量を探索に含めることができます。dotData Feature Factoryで定義された、データ前処理から特徴量エンジニアリングまでの全ての処理は、「特徴量パイプライン」に変換されます。特徴量パイプラインは、効率と一貫性を重視して設計されており、機械学習モデルやその他のアプリケーションに直接統合することができます。
dotData Feature Factoryは、特徴量エンジニアリングの試行錯誤を再利用可能なアセットへと変換し、従来の手作業かつ属人性の高いプロセスから脱却します。これによって、特徴量エンジニアリングは、アドホックな使い捨ての作業ではなく、データドリブンな意思決定を強化するためのアセットを蓄積する重要なプロセスとなります。
要するに、Feature Factoryは特徴量発見と特徴量エンジニアリングのすべての課題を一挙に処理します。これは、入力されたデータから新しい特徴量を発見し、これらの特徴量を機械学習対応の特徴量テーブルに生成するアイデアエンジンです。独自のアルゴリズムにより、膨大な特徴空間から最適な特徴量を見つけ出し、ユーザーが数十万もの新しい特徴量を精査できるようにします。Feature Factoryは、Databricksを含むさまざまなプラットフォームと容易に統合できます。
Unity Catalogのリネージ追跡機能は、Databricks環境内でのデータのライフサイクル全体を可視化します。この機能は、データの透明性を高め、データの問題を発見、修正し、データ使用状況を監査し、データパイプラインでエラーが生じた際に根本的な原因を分析することができます。
以下に、Unity Catalogのリネージ追跡機能の活用方法を説明します。
ロバストで透明性の高いデータ管理システムを維持するために、Unity Catalogのリネージ追跡が実際にどのように適用されるのか、具体的な操作をご紹介します。

これらの手順に従うことで、Unity Catalogのリネージ追跡を利用して、ロバストで透明性の高いデータ管理システムを維持できます。データの読み取りから変換、そして書き込みまでの各操作が追跡されるため、データの流れが明確になり、データの整合性とコンプライアンスが確保されます。
詳細については、Unity Catalog とそのリネージ追跡機能に関するこちらのDatabricksの公式ドキュメントを参照してください。
Databricks Delta LakeとUnity CatalogにdotData Feature Factoryを組み合わせることで、強力なシナジーが生まれます。
Delta Lakeは、ACIDトランザクション、スキーマの適用、およびタイムトラベルなどの機能を通じて、信頼性の高いデータストレージと一貫性のあるデータ処理を実現します。これらの機能は、データの整合性を維持し、バッチ処理とストリーミング処理をシームレスに行うことができます。
Unity Catalogは、詳細なアクセス制御でセキュリティとコンプライアンスを確保し、データリネージ追跡でデータの出所と変換過程を追跡します。また、データディスカバリー機能によりデータを簡単に検索・共有し、効率的なコラボレーションを促進します。
dotData Feature Factoryは、複雑で時間のかかる特徴量エンジニアリングのプロセスを自動化します。特徴量の作成、発見、管理を簡素化することで、データからすぐに分析できるデータセットへの移行を加速させます。
これらの技術を組み合わせることで、データライフサイクル全体を強化し、メダリオンアーキテクチャのシルバーレイヤーからゴールドレイヤーへの移行が飛躍的に効率化され、高品質で豊かなレイヤーを実装できます。


