
特徴量自動選択による顧客リスクの見積もり
- ブログ
金融サービス、住宅、保険といった業界では、リスクの自動スコアリングが顧客に大きな利益をもたらすことがあります。これはスコアリングによって組織の潜在的な危険性を定量化することができるためで、このようなリスクのプロファイリングは組織が持続可能な長期的成長を築き、景気後退時の損失を最小化するのに役立ちます。しかしながら、従来のリスクスコアリング手法は十分な効果を上げられないことが多いのが問題です。これに対し、新しい機械学習(Machine Learning, ML)ベースの手法を利用することでスコアリングを補強できます。
さまざまな業界でよく使われるユースケースには以下のようなものがあります:
従来、企業はこのようなユースケースを「ルールベース」のアプローチで解決してきました。たとえば銀行員が融資をおこなうか判断するには、クレジットスコアや世帯収入を利用していたかもしれません。
シンプルなルールベースのロジックは実装が簡単ですが、利用するデータ量が増えるに従い十分な拡張性と信頼性を提供できなくなります。また、ルールベースのロジックは、扱う変数の数が増えると複雑になり管理が難しくなる傾向があるのも問題です。
調査会社のIDCは2021年に、世界で新規生成や複製によって増加するデータ量が2025年までに23%増加し、181ゼタバイトという驚異的な量になると推定しました。181ゼタバイトはDVDディスクに換算すると約250,000,000,000枚に匹敵する容量です。シンプルなルールベースのモデルは、このような構造化データと非構造化データの両方の増加によってより扱いにくく、時代遅れになっていくでしょう。これに対して優れた機械学習ベースのアルゴリズムは、より質の高いデータによりルールベースのアプローチよりも優れたリスクプロファイリング結果を生成することが可能です。
リスクプロファイリングのための機械学習ベースのソリューションは、一般にルールベースのアプローチよりも優れていますが、機械学習ソリューションの構築には課題があります。たとえば問題の定式化、モデルの開発、利用可能なリソース、対象分野のドメイン知識、モデルメトリクスの検証、そして顧客の採用状況が機械学習プロジェクトの成功を妨げるかもしれません。
機械学習ベースのアルゴリズム開発における課題をより理解するため、あるチェコの銀行から広く入手可能なデータセットに基づくユースケースを考えてみましょう。ここで見積もりたいリスクは、顧客がローンの支払いを不履行にする可能性があるかどうかで、ローンが承認される前にリスクを予測するのが目的です。
このチェコの銀行から入手したデータセットには、ローン設定前後の取引に関する履歴が含まれています。さらに、取引に関する詳細や、顧客が保有する口座の数、顧客の主な口座に紐付けられた顧客の数なども含まれています。
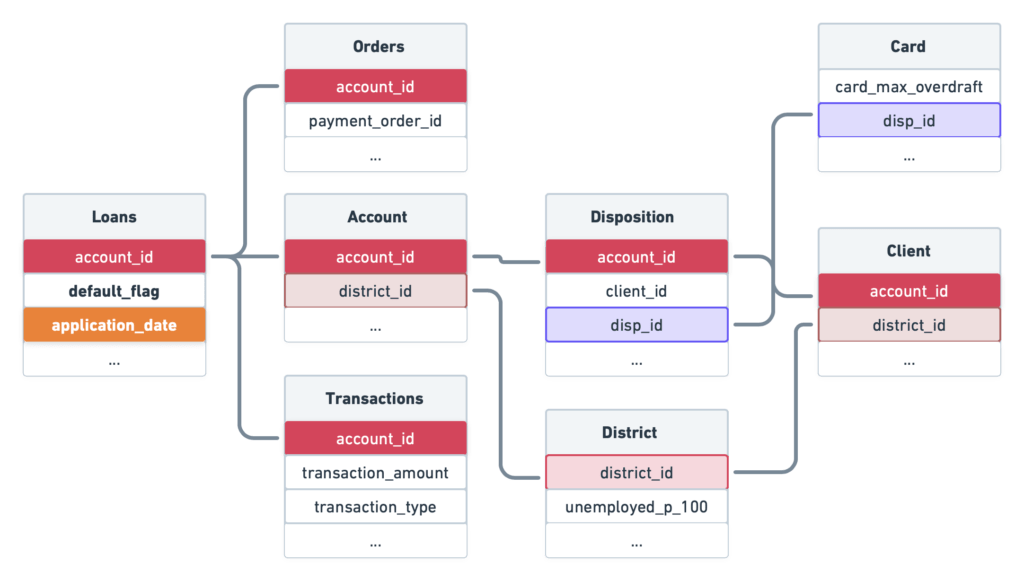
過去のデータにある682件のローンのうち、76件が貸し倒れ、606件が支払いを期限内におこなわれました。
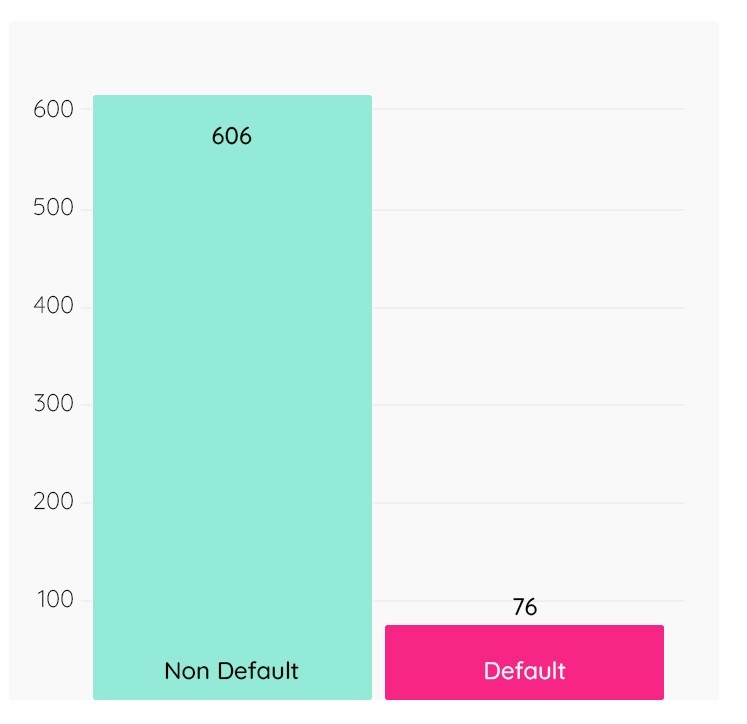
サンプルデータに含まれるデータは以下のようなものです:
| テーブル | レコード数 |
|---|---|
| ローン | 682 |
| オーダー | 6,471 |
| 口座 | 4,500 |
| 決済 | 5,369 |
| 地域 | 77 |
| 取引 | 1,050,000 |
| 顧客 | 5,369 |
| カード | 892 |
さまざまなリスク調査をおこなったにもかかわらず、この銀行では承認されたローンの11%以上が貸し倒れとなりました。銀行の目的は、11%をより許容できる数字に減らすために、それぞれの借り手が貸し倒れになる可能性を特定できるようになることです。
我々の機械学習モデルの目標は、顧客のアカウントIDに対し、提供されたローンを不履行に至るかどうかを予測することです。データセットには682件の個別のローンに対し、105万件の取引記録が存在します。以下は、利用可能な取引データのスナップショットです:
| アカウント | 日付 | タイプ | 決済方法 | 金額 | 残高 |
|---|---|---|---|---|---|
| 1695 | 1/3/1993 | クレジット | キャッシュ・クレジット | 200 | 200 |
| 1695 | 1/8/1993 | クレジット | キャッシュ・クレジット | 11832 | 12032 |
| 1695 | 1/31/1993 | クレジット | 38.8 | 12070.8 | |
| 1695 | 2/2/1993 | クレジット | キャッシュ・クレジット | 7500 | 19570.8 |
| 1695 | 2/28/1993 | クレジット | 50.1 | 19620.9 | |
| 1695 | 3/4/1993 | クレジット | キャッシュ・クレジット | 5200 | 24820.9 |
データサイエンティストはモデル構築のために特徴量を抽出する必要があります。たとえば以下のようなものです:
このリストは完全なものではありません。生成される特徴量はデータサイエンティストの知識、およびリスクプロファイリングや類似のユースケースを解決した経験によって変わります。典型的な機械学習開発サイクルでは、データサイエンティストはデータエンジニアのようなほかの開発者の支援を受け、下図のような一連のステップを実行することが多いです:
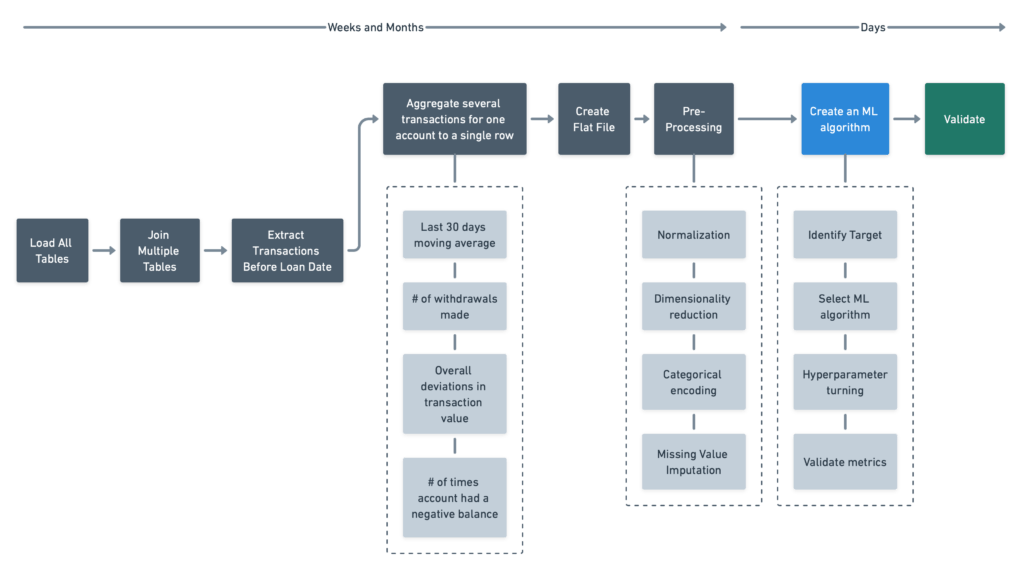
手作業によるアプローチの1番の限界は、複数のテーブルから一枚のテーブルにデータを集約する際、時間と人的資源の制約によりテーブル間の関係を探索する機会が限られ、貴重なデータを無視する可能性がある点です。また、特徴量の考慮すべき時間幅を決めるのも容易ではありません。
従来の機械学習開発プロセスにおいて、データサイエンティストはこれらの課題のいくつかに対処し、関連するデータがモデルで使用される可能性を高めるため、対象のビジネス分野の専門家に頼ることもあります。しかしながら、このアプローチには限界があります。ビジネス分野の専門家は経験に基づいた助言しかできず、価値のある洞察を見逃してしまうかもしれません。時間の制約、利用可能なリソース、問題の影響度などによりますが、経験豊富な実務者であっても、リスクプロファイリングのユースケース解決に数週間から数カ月を費やすことになるでしょう。
さらに、正しいモデルタイプや適切なハイパーパラメーターが使われているか、などの不確定要素も常に多く存在します。
dotDataは問題の定式化やモデルの構築、およびその展開を加速するためのプラットフォームです。dotDataの特許取得済み技術は、データを扱う実務者が問題解決により集中できるよう、ほかの時間がかかる重い作業を代行します。
dotDataの技術の中核をなすのはAIベースのシステムで、データウェアハウスやデータレイクにあるリレーショナルエンタープライズデータに直接接続し、数百テーブルにまたがる何千もの列および数百万行のデータから洞察を自動的に発見して分析可能です。
dotDataの技術を使えば、特徴量エンジニアリングは既存の特徴量をもとにした単純な修正を超え、モデルにとって価値のある関連するパターンを自動的に発見する方法をユーザーに提供します。
dotDataの特徴量自動設計は、データサイエンティストの特徴量発見・評価プロセスを支援するための3つの効果的な方法を提供します。まず、複数のデータテーブルをインポートし、エンティティリレーションを定義することが可能です。
2つ目として、dotDataは既存の特徴量を組み合わせることにより新しい特徴量を生成するという、より伝統的な特徴量エンジニアリングの手段も提供しています。
最後に、dotDataのプラットフォームは、インテリジェントな集計機能を備えており、ユーザーからのシンプルな入力に基づいて日、週、月などによる集約を自動的に作成できるため、時系列ベースの問題解決に理想的です。
この強力な特徴量エンジニアリングの三位一体により、データサイエンティストは特徴量開発よりもアルゴリズムの選択と最適化に作業を集中させることができます。また、対象分野の専門家は自らが知らない可能性のあるデータパターンに対する洞察を得ることができ、価値の高い特徴量の構築を迅速かつ正確におこない、価値創造までの時間が短縮されるでしょう。
dotDataプラットフォームの機械学習自動化機能は、ユーザーによって定義された特徴量と、特徴量自動設計によって生成された特徴量を組み合わせます。それらの特徴量を効率的にモデル構築に適用し、線形(線形回帰、ロジスティック回帰、SVM)、ツリーベース(Light GBM、XGBoost、決定木)、ニューラルネットワークベース(Tensorflow、PyTorch)など異なるモデルを実行し、評価指標等をレポートできます。ユーザーはそれぞれのビジネスニーズに合わせ、最適なモデルを選択し、運用することが可能です。
自動化を活用することで、ワークフローは以下のように簡素化できます:

ユーザーがローン、取引、注文、テーブルをインポートすると、それらの間の結合を定義することができます。たとえば、ローンに関するテーブルとアカウントに関するテーブルをアカウントIDで、カードや整理に関するテーブルを「DispId」の値によってといった具合です。
結合テーブルを利用することで、一枚表を作成する必要がなくなり、ユーザーは問題の性質に応じてテーブルの関係を構築および再構築できるようになります。
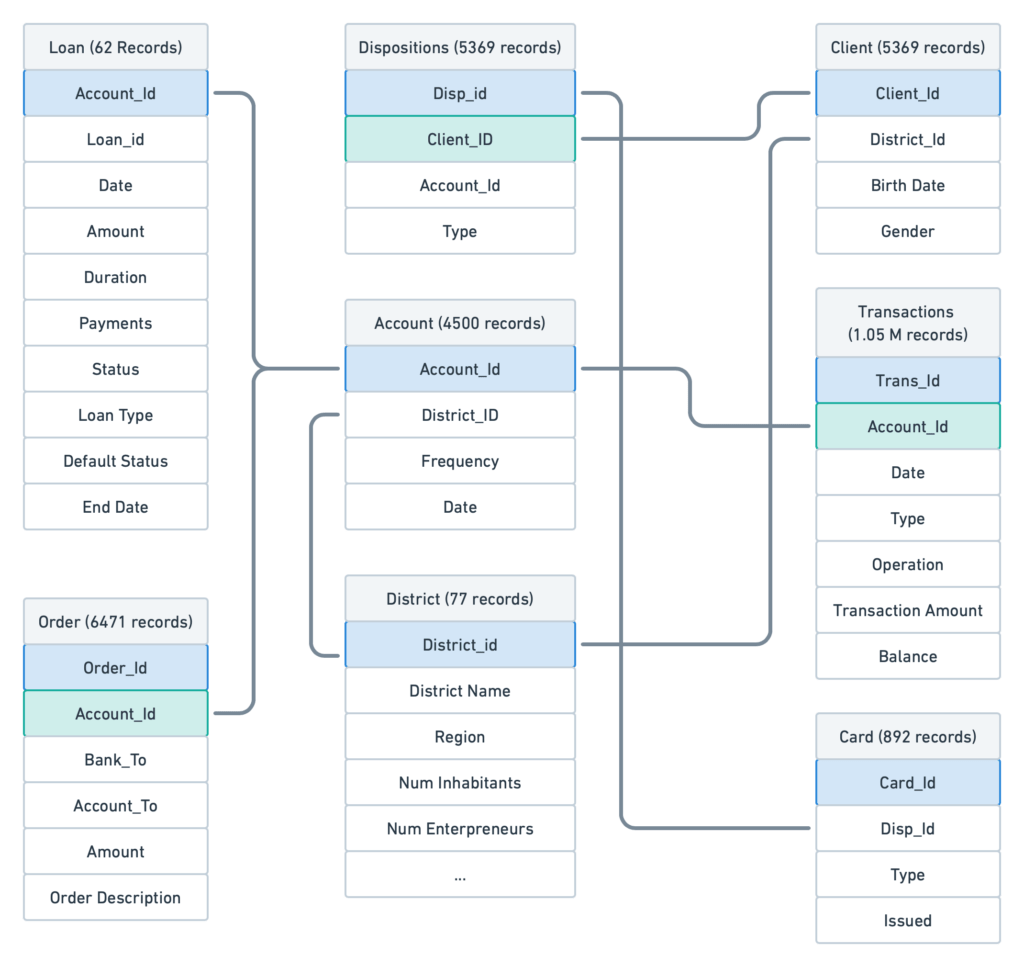
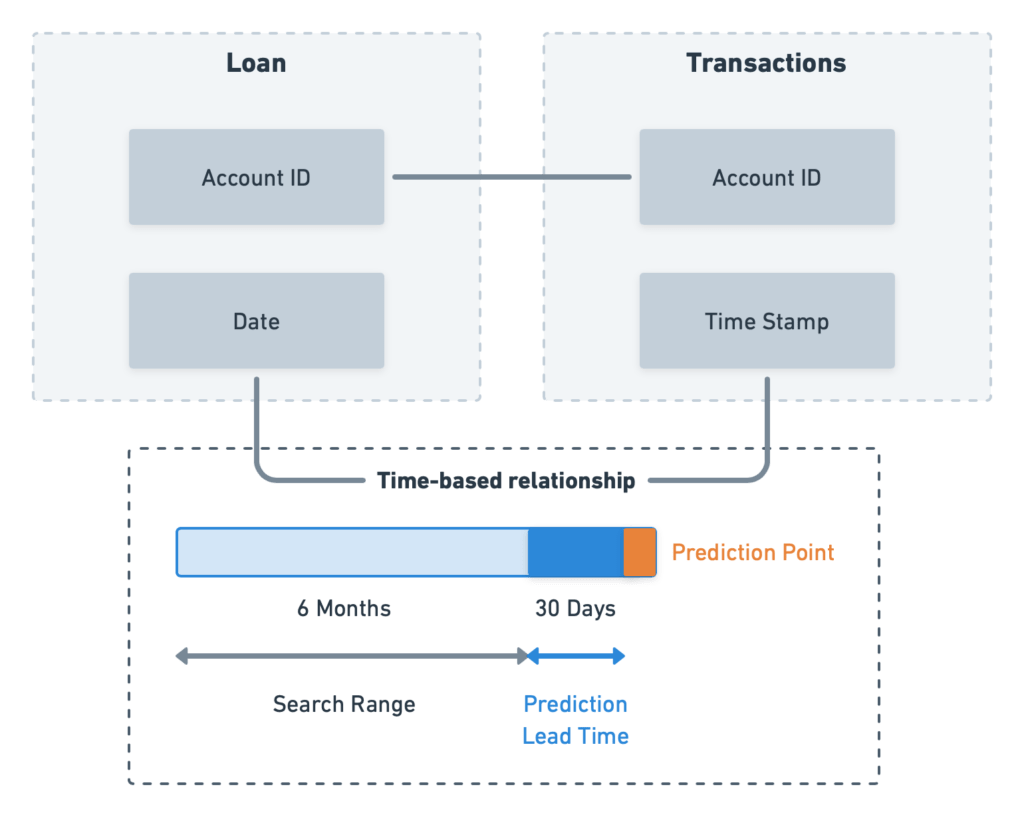
テーブル中のキーに基づいたテーブル間の関係(または結合)を定義したのと同様に、dotDataには時間範囲に基づいたテーブルを関連付ける機能もあります。このユースケースでは、ローンの貸し倒れを承認の30日前に予測する必要があると仮定しましょう。時間範囲の活用は2つのステップでおこなうことができます。
ユーザーは予測までのリードタイムを30日と指定します。すると、テーブル間の時間ベースの「結合」により、dotDataは自動的にローン承認30日前のトランザクションのみ抽出します。「30日間」というリードタイムを定義することでデータリーケージを減らすことができ、融資後の取引は一切含まれまれなくなります。
融資開始日の6カ月前の取引に、貸し倒れ予測に関する有益な情報が含まれていると仮定します。集計のために考慮すべきタイムウィンドウが不明でも、6カ月という検索範囲内で複数の時間ベース特徴量をdotDataに抽出させることが可能です。dotDataの自動化オプションは自動的に検索範囲を定義し、かつ検索範囲を定義するのに有用な特徴量を特定します。
ユースケース、データベーススキーマ、関係を定義したらクリック1つでモデルを実行できます。
90分で、dotDataはローン不履行のリスクがある個人を予測するために、何千もの特徴量候補や何百もの機械学習モデルを探索しました。
その結果、dotDataはXGBoostアルゴリズムがこの目的に対応する最適な方法だと判断し、dotDataが作成した自動分類および時間ベースの特徴量を使用しました。
以下のグラフは、モデルの性能への貢献が高い特徴量を上位から順に並べたものです:
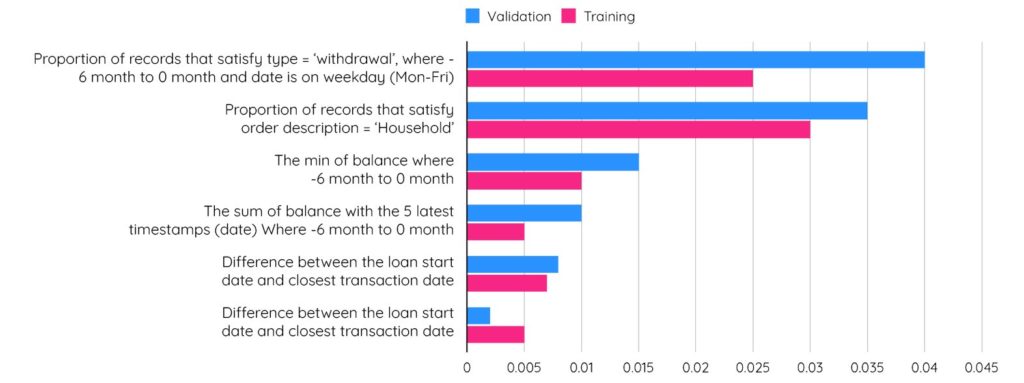
これらのdotDataによって発見された特徴量により、貸し倒れのリスクが高い顧客が持つ重要な傾向が特定されました:
モデルの評価指標:
混同行列は、分類モデルのパフォーマンスをモニターするのに役立ちます。正しく識別された予測、見逃された予測、および不正確な予測の数を把握可能です。
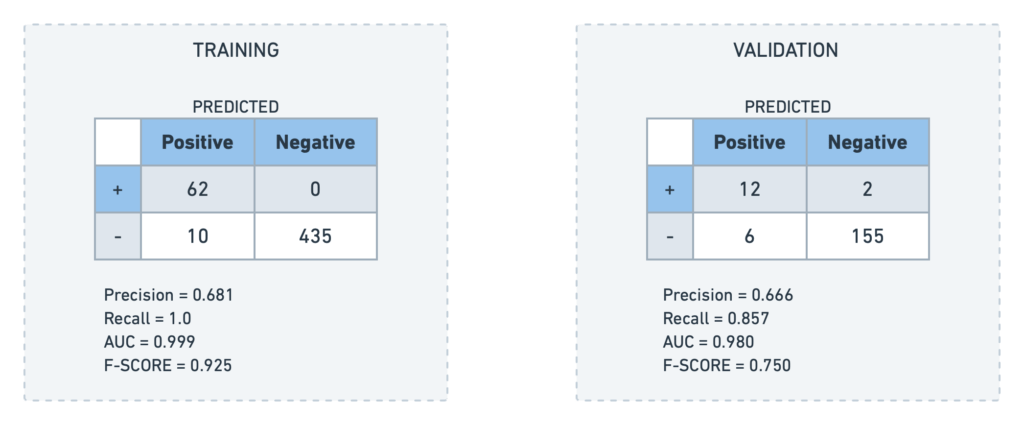
混同行列により、dotDataが検証データセット内に存在する14の実際に貸し倒れになったローンに対し、承認前に12のローンを貸し倒れの可能性が高いと特定することができたと示されました。検証データセットの175レコードのうち、53レコードがローン期間を終了しています。残りのローンは現在継続中のものです。我々は、損失が防止できたことによるコスト削減額を推定するため、支払期間を完了したローンを考慮に入れました。
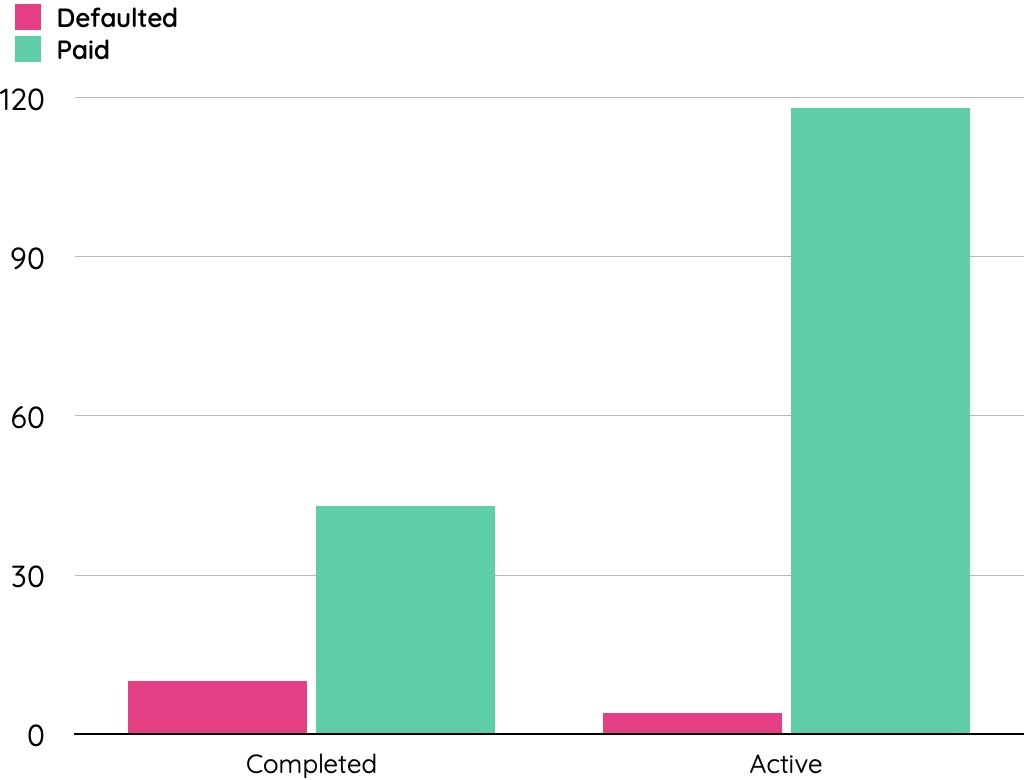
dotDataの機械学習モデルは、ローン承認前に10件中8件の債務不履行を特定することに成功しました。貸し倒れが予測された8つの口座IDを持つ顧客へのローン承認を防ぐことで、銀行は388,000コルナ(チェコの通貨、約200万円)以上を削減できたと推定されます。一方、このモデルが見落とした2つの貸し倒れ口座IDが引き起こした損失は約20,000コルナ(約11万円)です。
.
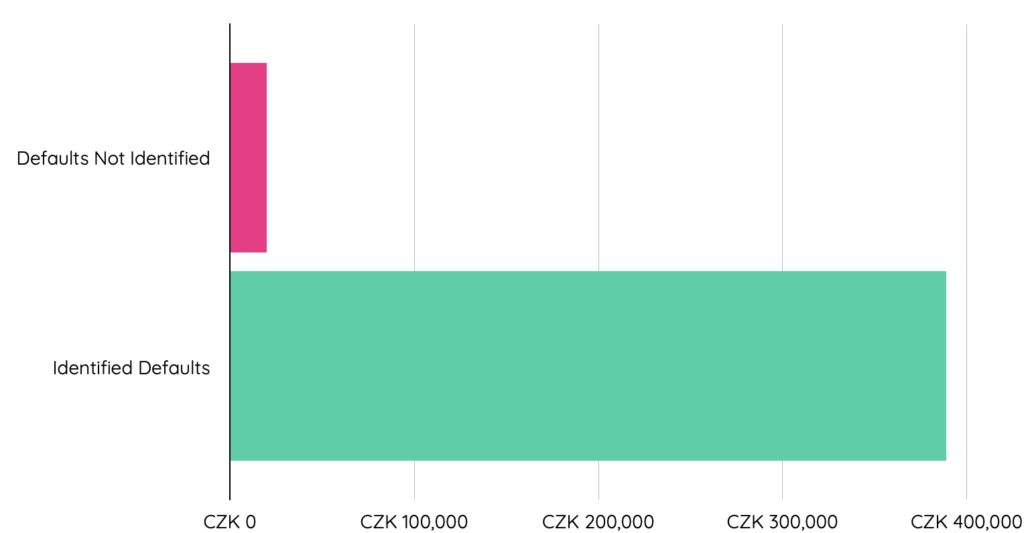
このユースケースに機械学習を適用することで、貸し倒れの可能性がある顧客の80%を特定することができ、大きな財務的に利益をもたらしたといえます。
我々は、dotDataがモデル開発のプロセスを加速させることを示しました。特徴量エンジニアリングやモデル開発に伴う煩雑な作業を代行することで、dotDataはデータのプロが「価値を提供すること」を支援する製品であるといえるでしょう。
最後に、テーブル間のキーベースおよび時間ベースの関係、時間ベースの特徴量自動抽出、モデル開発の自動化など、当社の受賞歴のある機能により、わずか数クリックでチェコのある銀行を巨額の損失から救うことができることを示しました。
dotDataの強力な機能をお客様の組織にどのように活用できるのか知っていただくため、デモのお申し込みをお待ちしております。