機械学習による時系列予測:AutoMLによる多次元時系列予測への挑戦
- ブログ
世界最大のデータサイエンスコミュニティであるKaggleとニコシア大学は、世界最大の小売業者であるウォルマートが販売する何千もの商品の売り上げを予測する国際コンペを主催し、4カ月間にわたるコンペには世界中から5,500以上のチームが参加しました。課題は米国3州にあるウォルマート10店舗における3000種類の商品の日次売り上げを予測するというもので、利用可能なデータは、商品レベル、部門、商品カテゴリー、カレンダー、販売価格と店舗詳細です。
今回、「M5 Forecasting – Accuracy」で公開されているデータにdotDataのAI自動化を適用したところ、上位1.8%(5,500以上の参加チーム中102位)相当のスコアを得ることができました(注:dotDataがチームとしてコンペに参加したわけではなく、コンペ終了後に公開されたデータによる検証となります)。できる限り自動的に実施するために、データの前処理はほとんど実施せず、作業そのものは、dotData社員が一人で1時間程度でした。このブログでは、dotDataプラットフォームによって、ビジネスアナリストや業務部門のメンバーのような市民データサイエンティストであっても、最小限の作業によって世界レベルのデータサイエンティストとも競い合えるレベルの結果を出せるということをお伝えします。
需要予測、収益予測、売上予測といった時系列予測は多くのビジネスに共通する最も基本的な問題です。予測手法は多数ありますが(例:自己回帰モデルやARIMAモデル、長短期記憶ニューラルネットワーク(LSTM)など)、実世界の時系列予測問題は簡単なものではありません。
このコンペの課題はSKU(Stock Keeping Unit、最小在庫管理単位)レベルの商品需要を予測することで、これは小売業者が在庫管理を最適化するために非常に重要となります。データを扱う際に直面するいくつかの課題は次のとおりです。
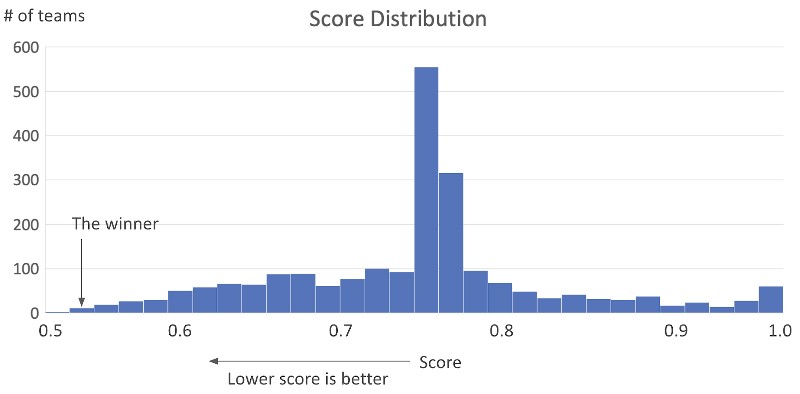
コンペの期間は4カ月で、参加者はさまざまな前処理法やモデル化アルゴリズムを用いてモデルを最適化しました。図1は上位40%の参加者のスコア分布を示しています(スコアが1.0未満の場合)。
経験豊富なデータサイエンスチームであっても、高い精度を出すことは難しく、参加者の技量によってスコアが大きくばらついていることが分かります。
dotDataを使用した試行1回目では各店舗用に合計10のモデルを構築しました。実施したステップは次のとおりです。
ステップ0(dotData Platform外の前処理):
ステップ1(GUIで学習タスクを設定):
ステップ2(店舗ごとに学習タスクを実行):
ステップ3(予測タスクを実行しテストスコアを計算):
dotDataで全10モデルの訓練と予測を完了するための計算に要した時間は約48時間でした。この初回実行の予測によって、コンペのトップ3%相当のスコアを得ることができました(5,500以上の参加チーム中170位)。与えられた課題の複雑さと、ドメインからの入力や試行錯誤なしで得られた結果であることを考えると、十分すぎる結果であると言えます。
dotDataは標準的な設定を利用して、各店舗に対して、自動で100,000以上の特徴量を探索し、その統計的な有意性を検証して特徴量テーブルを生成しました。dotDataはそれらの特徴量を利用して、L1/L2 正則化回帰、回帰木、LightGBM、XGBoost、PyTorch、TensorFlowなどの、線形および非線形の機械学習アルゴリズムに対して、異なる組み合わせのハイパーパラメータを持つ500以上のモデルを生成しました。dotDataは時間的情報を時間特徴量にエンコードする様々な高度な手法に対応していて、MLアルゴリズムでそれらの時間特徴量の組み合わせを最適化して、最も高い予測精度を実現します。
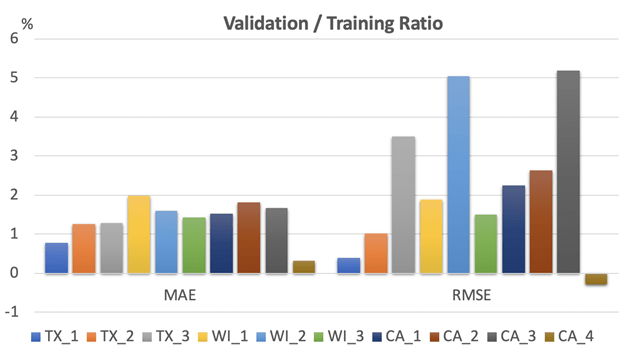
あまり驚くことではありませんが、最も精度の高いモデルは、9モデル(9店舗)が XGBoost、1モデルがLightGBMでした(最終的にはすべてのモデルが勾配ブースティングアルゴリズムを選択したことになります)。図2は各モデルの訓練と検証スコアの比率を示しています。検証のMAEは訓練のMAEより1~2%劣るだけであることが分かります。RMSEに関する検証/訓練の比率はいくつかの店舗で高くなりましたが(3~5%)、これは売上の絶対値が大きかったためです。全体としてみると、dotDataで自動的に構築されたモデルの過学習はほとんどなく、よく一般化されています。
ご想像のとおり、ほとんどのKaggle参加者はXGBoost、LightGBMやNeural Networksを使用し、私たちも同じMLアルゴリズムを使用しました。では、なぜ、dotDataは初期段階からトップ3%相当のスコアを達成できたのでしょうか。それは、dotDataが多数の、高度な時間特徴量を設計したためです。
表1はdotDataが自動的に設計した時間特徴量の例を示しています。ご覧の通り、時間特徴量には異なる種類があります。面白いことに、これらの特徴量は、階層的パターンや周期パターンのような、データサイエンティストが作成する特徴量や、ARIMAモデル(自己回帰和分移動平均モデル)のような時系列分析手法が内部的に生成する特徴量に対応づけることができます。これらの特徴量を発見した裏側には、dotDataが各モデルに対して100,000以上の特徴量を探索したこともぜひ強調しておきたい点です。手動で行うとしたら、複雑なクエリや何百・何千行ものクエリやコードを書く必要があるます。さらに、意味のある特徴量を生成するには、そのドメインへの理解が必要です。

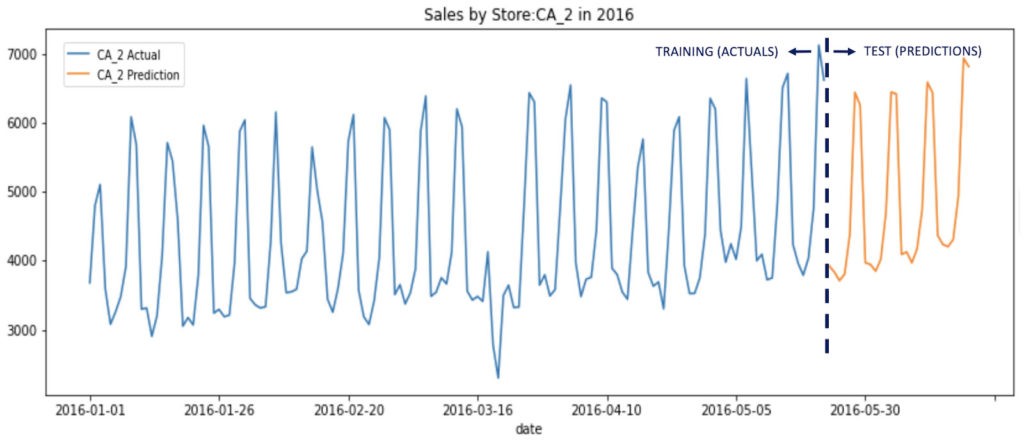
コンペの結果は2016年の28日間に対する予測で評価されました(テスト期間のデータは開示されないブラインドテスト)。図3は2016年のカルフォルニア州のある店舗(CA_2)における訓練期間の「実際の売り上げ」と、テスト期間(直近28日間)の「予測」の時系列プロットです。テスト期間の「実際の売り上げ」がないため、定量的な結果は議論できませんが時間経過に対するプロットが示すように、売り上げの傾向は予測によりかなり良く捉えられているといって差し支えないと思います。
トップ3%のスコアはそれだけでも満足のいく結果でしたが、私たちはこのトライアルをもう一歩進めてみました。対象データの階層的な性質(州レベル―店舗レベル―商品分類レベル―商品レベル)をモデルに入れることで、精度を改善できると考えました。階層の特定のレベルでモデルを構築すると、他のレベルよりもパフォーマンスが良い場合があるためです。
試行2回目の目標は、このような「階層的情報」を取り入れ、よりロバストで精度のよいモデルを作成することです。手順は非常に単純です。試行1回目と同じステップを使って、異なるレベルのモデルを構築します。
最終予測値は全4レベルの予測値の単純平均で、特別な後処理や最適化は実施していません。
図4はカルフォルニア州の1店舗(CA_2)における2016年の食品と家庭用品カテゴリーにおける訓練期間の「実際の売り上げ」とテスト期間(直近28日間)の「予測」を時系列でプロットしたものです。
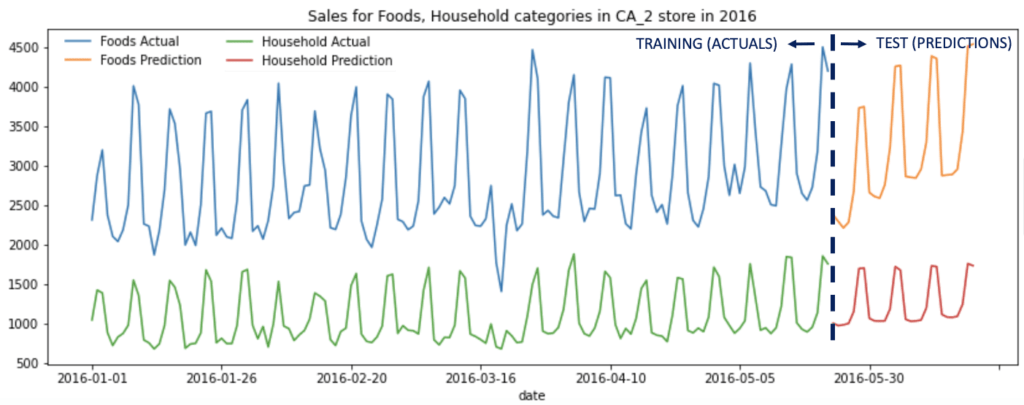
これによって、スコアは試行1回目の第170位から第102位(トップ1.8%)相当へと改善しました。また、試行2回目についても、前処理はカテゴリーごとのデータ分割(それもdotDataのGUI上で可能です)、後処理はスコアの単純平均のみで、ほぼ自動で実施できている点も重要なポイントです。ウォルマートの製品需要予測という非常に実用的な企業での使用例において、私たちの自動化手法が世界レベルのデータサイエンスチームと比較しても引けを取らない結果を出したことをとても嬉しく思っています。
小売業者が予測を行うには、何カ月もかけて特徴量を構築し、モデル生成しながら予測を出す必要があります。今回の結果は、dotDataのデータサイエンスの自動化によって、多次元時系列予測を非常に効率的かつ高精度に解決する大きな可能性を示しています(トップ1.8%相当の予測結果を得るのにかかった時間は、約1時間の作業時間と約150時間の計算時間時間でした)。また、dotData外の作業も、Excelで可能な作業しかなく、dotDataの自動化によってデータサイエンスの専門知識がない「市民データサイエンティスト」も時系列予測に取り組むことができるようになり、企業における分析の民主化の起爆剤になれば幸いです。





