
講師プロフィール
日比野 恒氏 ログスペクト株式会社 / セキュリティアーキテクト
CISSP, CCSP, CISA, PMP, 情報処理安全確保支援士(000999)
[著書]
Elastic Stack 実践ガイド [Logstash/Beats 編](インプレス刊)
AWS 継続的セキュリティ実践ガイド(翔泳社刊)
坂本 卓巳 dotData, inc Director of Engineering
Webinarのスクリプトはこちらからご覧ください。↓
坂本:こんにちは。dotDataの坂本です。本日はdotDataのウェビナーをご覧いただき、ありがとうございます。今日は「生成AIのセキュリティ」について、日比野さんと一緒に色々なお話が出来ればと思います。
日比野さんも一言、自己紹介をお願いします。
日比野:はい。はじめましての方多いと思いますけど、ログスペクト株式会社の日比野と申します。ざっくばらんに、生成AIのセキュリティについて、坂本さんとお話しできたらなと思っておりますので、よろしくお願いします。
坂本:では、dotDataのウェビナーということで、「生成AIのセキュリティ」というタイトルで始めていこうと思います。
まず登壇者2人の自己紹介を簡単にさせていただければと思います。私は坂本と申しまして、dotDataでは、Director of Engineeringというポジションで製品や組織のマネジメントなど、多くのことに従事しています。以前はインフラだったりとか、データ基盤だったりとか、そういう仕事などを日本のスタートアップでやった後、dotDataに入社し、現在はUS本社のオフィスで働いています。
dotDataでは、セキュリティに関しての多くの取り組みを主導しています。例えば、昨年SOC2 Type IIというセキュリティ認証規格を取得しましたが、そこのプロジェクトを主導したり、現在はプロダクトセキュリティを統括して、当社の製品やサービスがセキュリティ面で問題ない状態にできるように、色々な開発チームとコミュニケーションしながら、プロダクトセキュリティをやっています。
日比野:次は自分も簡単に自己紹介をさせていただきます。自分で作ったログスペクト株式会社という会社でITアーキテクトとして活動している日比野と申します。
セキュリティ以外の仕事もしてますが、主な肩書きとしてはセキュリティアーキテクトという形で活動しております。略歴ですが、10年間ほど日本国内のITコンサルティング会社に所属し、インフラアーキテクトだったり、セキュリティのアセスメントみたいなことを、2018年までやっておりました。
その後、入社時はテクノロジーズでしたが、会社が統合して株式会社リクルートのセキュリティ組織で直近まで業務をしておりました。ここではセキュリティの業務に従事しておりましたので、ログ基盤であったり、あとはクラウドのセキュリティということでAWSであったり、Google Cloudであったり、様々な案件に従事しておりました。
書籍もいくつか執筆もさせていただいておりまして、インプレスさんからは、Elastic Stack実践ガイドという、主にログ基盤にまつわるElasticの実装に関するナレッジをまとめた書籍であったり。
あとは昨年度翔詠社さんから、AWS継続的セキュリティ実践ガイドということで、ログやFindingsと呼ばれるイベントを扱うにはどのようにすればいいのかというナレッジについて、まとめさせていただいています。
こういったような活動を通して、色々なお客様やエンジニアの方に有益な情報を提供するというようなことをしております。今日はよろしくお願いします。
生成AIとは何か?そのセキュリティリスク
生成AIの定義と主要な用途
坂本:本編に進む前に用語の定義について、少しお話させてください。タイトルの生成AIのセキュリティについて、この分野でよく聞く単語として、生成AI(生成系AI)、Generative AIだったり、LLMだったり、GPTというものを耳にすることがあります。みなさんも、よくご存知かもしれませんが、LLMや大規模言語モデル、GPTという用語について、このような定義で今回の話をさせていただければと思います。

日比野:今回の取り組みで検討している中で生成AIのセキュリティという表現もあれば、LLMのセキュリティという表現のドキュメントもあったので、改めて用語の定義を理解する良い機会だったなと思います。
生成AIのセキュリティリスク
坂本:今回、dotDataがなぜ生成AIのセキュリティについてお話するのかですが、このdotData Insightという製品は、我々が開発しておりまして、従来のデータ分析と少し違う点としては、「データ分析に詳しくないが、データを活用してビジネスを改善していきたい」というモチベーションをもっている業務部門の方に、より簡単にデータ分析をし、そこから洞察を導き出してビジネスを改善していけるようにするための製品として、このdotData Insightを開発しています。
その中でこの生成AIを利用している機能がデータ分析した結果を解釈して説明してくれたり、分析した結果を踏まえてビジネスの仮説みたいなのを作ってくれたりします。お客様が我々の製品の中のこの生成AIの機能を利用するにあたって、データ分析をする上でお客様のデータを入れて頂くため、セキュリティが非常に大事と考えています。
もちろん新しい技術を使ったら便利になるという部分はあるのですが、一方で新しいテクノロジーというものを正しく理解して使うには、セキュリティの問題など、気にしなければいけないことがあります。そういった観点で日比野さんと協力して、どういった形で生成AIのセキュリティを考えなきゃいけないんだっけとか、どういった点を気にしなきゃいけないんだっけとか、そういったことを考えてきましたので、そのあたりの話ができればと思っています。
dotData Insightとは?
このdotData Insightは非常に面白い製品になっていまして、この特徴1と特徴2に書いてあるような特徴を持っています。こちらは銀行の個人ローンの支払い遅延リスクの高い人がどういう属性を持っているかということを分析するようなユースケースになっていますが、業務データである個人のプロフィールのようなデータやその個人のローンの支払いデータなどをこのdotData Insightにインポートしてもらうと、左側のスクリーンショットにあるようなセグメントを自動で抽出してきて、「こういう特徴と、こういう特徴と、こういう特徴を持った人が、このローンの支払い遅延リスクが高い」というようなことを示してくれたります。
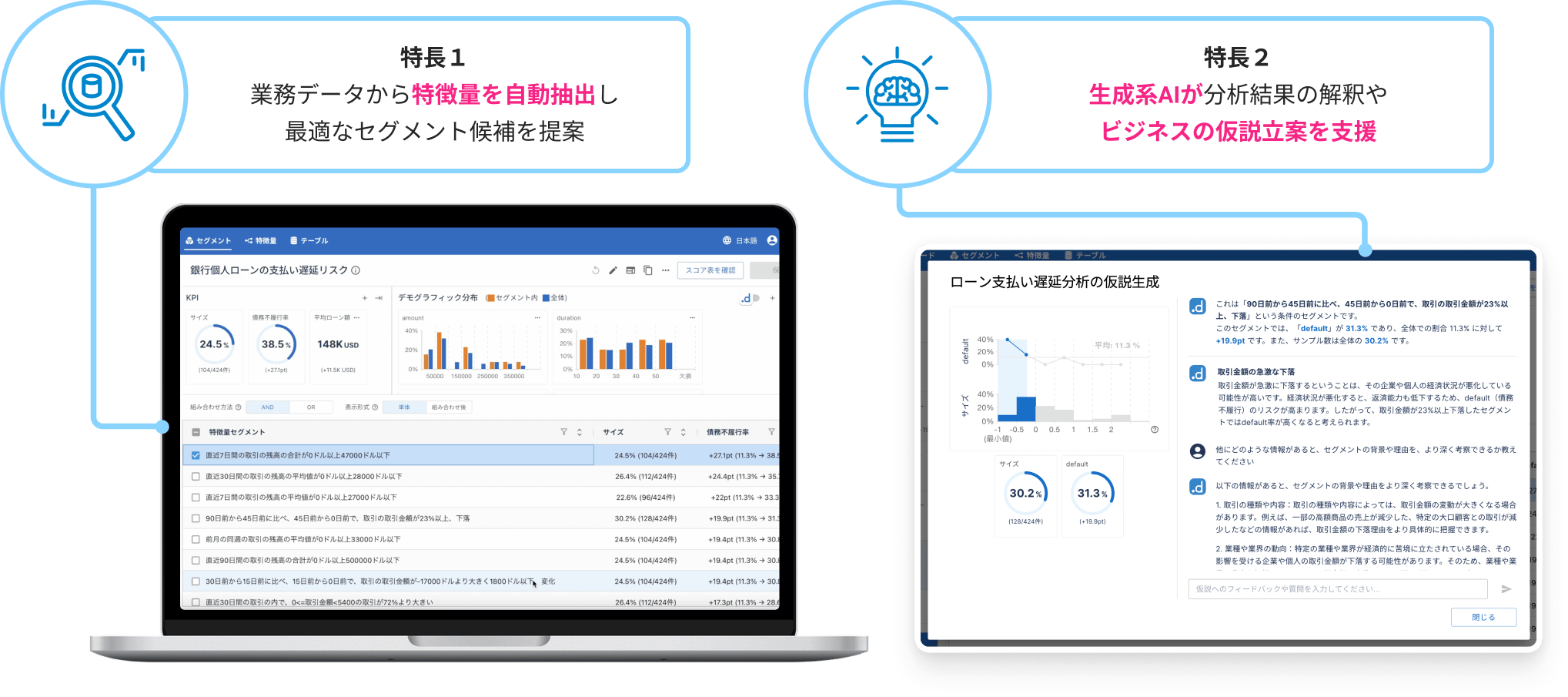
この例ですと、この支払い遅延リスクが高くなるようなセグメントを特定して、セグメントを避けたりするようなことが考えられますが、特徴2に書いてあることは、データ分析した結果を生成AIが解釈し、わかりやすい形で説明してくれたり、またはこのようなデータ分析の結果がある場合に、そこからどういうことが言えるのか、どういうことを考えられるのか、そういったことを生成AIが支援してくれます。
生成AIのセキュリティ対策と事例
下にデモの動画があるので、実際の動きは見ていただけるとより理解しやすいと思います。ぜひご覧ください。
これは先程のスクリーンショットのところと同じような形でデータを入れていただくと、このような形でいくつかのセグメントが出てきますので、ある特定のセグメントが気になりますということで、この中ではこの指定したセグメントの分析結果に関して、仮説を生成してくださいという指示で生成AIに仮説を出してもらっています。
さらに、1回この収入の減少ということが仮説として出てきますけど、さらに追加で長期金利が上がったっていうようなことを仮定すると、どういうことが言えるでしょうか?ということを、さらに深掘りすると、生成AIが持っている世界の知識というものを元に、どのようなことが言えそうか答えてくれます。他にも分析していく中で、アイデアが欲しいという場合では、他にこのような形で、どういう情報があると、このセグメントに対して深い考察ができますか?と投げかけると、それに対しても生成AIは、このような観点で、このようなことを考えると、もう少し色々な考察ができるんじゃないですか?とか答えてくれます。そのようなことができるアプリケーションになっています。
ということで、これは一つの生成AIの活用方法ですけど、他にもこの製品の他の部分にも生成AIを使っているので、セキュリティ面でも万全な状態で便利な機能をお客さまに提供したいと考えて製品を扱っています。そのような紹介になっています。
重ね重ねになってしまいますけど、業務部門が主役になるようなビジネスアナリティクスのプラットフォームを作っていまして、そこで我々の製品の中で、特にユニークであるセグメントの特徴量について、データをインポートするだけで自動で生成してくれる部分と、出力されたデータ分析の結果を生成AIが解釈して、さまざまな仮説を立ててくれる部分で、業務部門が自分で考えて使っていけるようなデータ分析のプラットフォームを作っています。その中で生成AIのセキュリティについても多くの検討をしてきたので、そのあたりについてお話したいと思っています。
生成AIのセキュリティについて気を付けるべきポイント
日比野:では、この生成AIを組み込む上で、特に生成AIのセキュリティについて、どういったところが重要なポイントなのか、気をつけなければならないのかみたいなところをお話ししていきましょうかね。
坂本:そうですね。はい。
日比野:ひょっとしたらみなさん、ご興味があると思いますので、耳にしたことがある方もいらっしゃるのかなと思います。ちょうど1年ぐらい前になりますが、生成AIの、特にChatGPTがローンチされ、サービスを利用できるようになってから、多くの方が書籍やWEBで情報を得たり、場合によっては、お勤めの会社でChatGPTが使えるようになったり、有料版のアカウントを申請すれば用意してもらえるような状況になってきている中で、会社のセキュリティ部門の方からガイドラインなど、こういうことに気をつけなさいよというようなお話がされたりしていると思います。ゆえにある程度の基礎知識は多くの方々にもあると思いますが、具体的にどういった事例があったのか、実際のインシデントまでには発展してないものの、USの研究者の方々が、ChatGPTないしは、生成AIに対して、こういったプロンプトを投げ続けたり、もしくはこういうプロンプトを繰り返していくと、なぜか生成AIが想定していないような結果を導き出すようなことがあるというような論文を結構発表していたりはします。
そういった記事が数日遅れで日本で話題になったりしますが、こういったところを検討している人にとっては重要なデータソースになると思います。今日はここで二つほどなるべくバラエティ豊かな形で共有できればなと思っています。
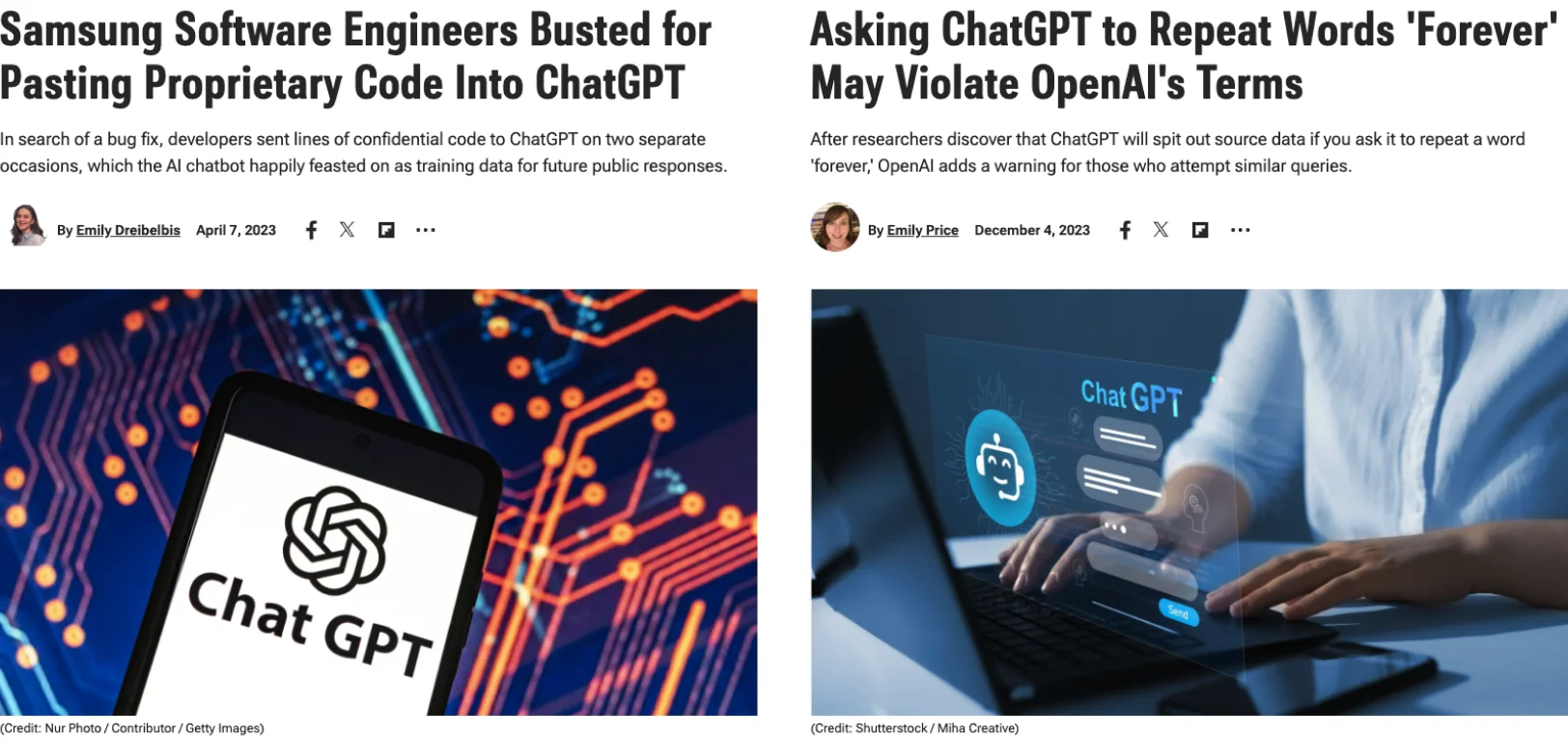
Asking ChatGPT to Repeat Words ‘Forever’ May Violate OpenAI’s Terms
事例1:ChatGPTを用いた情報漏洩
1つ目の左の画像の方はサムスンです。韓国のサムスンのソフトウェアエンジニアの方が、4月7日なのでちょうど1年前ぐらい、ChatGPTが出た頃に、ソースコードを含むプロンプトを投げてしまって、それが情報漏洩という形で公開されてしまいました。ChatGPTが学習データとして取り込んでしまったということで、それが情報漏洩につながったユースケースとなっています。
これはChatGPTが出た当初から想定されるようなインシデントではあったものの、実際すぐ起きてしまったということで、結構注目を浴びた事例の一つかなと思っています。
ChatGPTに限らないですが、今までもGoogle翻訳とか、色々なテキスト入力が結構自由にできるようなものに、重要な会社の情報を入力するなという話はあったかと思います。ここに関していうと、必ずしもChatGPTだからということはないかなと思いますが、こういったような機密情報がChatGPTを介して公開されてしまうようなユースケースも実際発生しております。
事例2:特定の単語を永遠に答え続けるChatGPT
右のケースは実際にインシデントではないんですけど、こういったインサイトに生成AIを実装するために多くの事例を集める中で、タイムリーに出てきた事例になっています。
昨年12月に、GoogleのDeep Mindの研究者の方が書いた論文になっています。
これはChatGPTにある特定の単語を永遠に答え続けてくださいというようなプロンプトを書くと、何百回かその単語を繰り返し出力した後に、急にChatGPTが学習している情報の中から、機密情報をべらべら喋り出すというようなことが、再現性のある事象であるということで、論文が発表された事例になっております。
こういったケースについては、左側とはちょっと毛色が異なりまして、今までみなさんが、携わってきたWEBアプリケーションでは、あまり考えれなかったようなユースケースかなと思っています。特に右側の論文で発表されたようなものは、GPTにおけるセキュリティにおいて非常に特徴的なユースケースと思っています。
こういったことが起きないようにというか、作りとして想定されてないようなことが、実際にアウトプットとして出てしまうということも含めて、生成AIのセキュリティをどう取り組んでいくと、リスク受容できるようなレベルで生成AIを実装できるのかを考えていく必要があると思っています。
ここでは、その生成AIのセキュリティ対策をどのようなアプローチで考えていくと、現状において、システムに生成AIを実装する上でリスクを低減していけるのかというところで、大きくこの2つのアプローチかなと思っています。
生成AIのセキュリティを強化するための実用的なガイドライン
OWASP Top 10 for LLM Applications
実際にこの取り組みの中で、この2つのアプローチを中心に組み立てをしています。1つ目が、OWASP Top 10 for LLM Applicationsというものになります。
この後詳しくご説明しますが、WEBアプリケーションのセキュリティにおいて有名なOWASPがこのChatGPTがローンチされてすぐにLLMに特化したトップ10を出していますので、ここを中心に組み立てていくというのは、非常に良いアプローチかなと考えています。
それだけですと、実装面において、具体性に少し欠ける部分も出てくると思いましたので、2つ目に書いておりますのが、結構色々な生成AI LLMを組み込んだサービスというのは、この1年で出たかなと思っています。
この後具体的なサービス名も踏まえながらご説明していきますが、一番有名なところでいうと、MicrosoftさんのAzure OpenAI Serviceというところがホットかなと思っています。
こういったサービスの中で実際にセキュリティの機能というものが、どのように実装されているかを深掘調査して、どういったリスクが想定されるから、そういったセキュリティ対策が施されているんだというところを、しっかり押さえることによって、それぞれのサービスが想定するリスクシナリオ、ユースケースの中でのセキュリティを実装レベルで評価できるかなというふうに考えました。この2つの組み合わせを中心に広げていったというのが、ベースのアプローチになっています。
セキュリティベストプラクティスの適用
坂本:あれですよね。ここに書いてあるもの以外にも、WEB上の記事だったりとか、先程紹介していたような論文だったりとか、そういうところも、ちょっと見ていった上で、まず初めに考えるべき、標準的なセキュリティだと、このあたりを見ていけば良さそうだよねっていうところを考える中ではやっていたと思っています。
もちろん現時点ではこれかなというところがありつつ、日々いろんな情報がアップデートされていくので、更新されていくとは思いますが、現時点だとこの2つあたりを押さえておくといいかなと、そういう感じですかね。
日比野:そうですね。実際やっている中で新しい論文が出て、「こんなの出たね」っていうことをSlackで共有したら、「これはそもそもなんでこんなことが起きるの?」って言われましたね。
坂本:そうですね。
日比野:気になる方から、当然ツッコミいただきますし、論文を深掘りしていくっていうことも実際にやりました。あとここでは表現していないんですけれど、セキュリティの技術面とは異なる角度で言うと、法律や法令とか、国ごとに定められるガイドライン、あとは業界団体が出すようなガイドラインといったところで、特に法律に関していうと、ヨーロッパ(EU)が先行して法令化、法令案を出していて、EU AI法案を出しています。そういった法律観点で、きちんと気をつけなきゃいけないっていうことも別軸であります。やっている中でも含めながら考えていましたが、今日は大事なところで絞って、この2点にポイントを置いていますという感じです。
タイミング的にすぐにOWASPがTop10 for LLMを出してきたので、こちらを中心に理解を深め、どういう研究の元このようなドキュメントになっていったのかを初期段階では調査しました。詳細が気になる方はOWSP Top 10のURLを見ていただくのがいいのかなと思いますが、この図は1枚絵で、LLMに特化したセキュリティのOWASP Top 10がどんな脅威をTop 10としているのかをまとめた図になっています。

実際にどれぐらいのユースケースがある中で、LLMのセキュリティTop 10を出しているかということもこのOWASP Top 10 for LLMに書かれています。どうやら当時150ぐらいの脅威が彼らの中では想定されていて、その中でも重要度の高い10個というところを、こういった形のアーキテクチャの中にプロットとして書かれています。
これは生成AIを中心とした LLMのアプリケーションの簡単なアーキテクチャ図になっていますが、左側に生成AIを使う利用者がいて、この中身がシステムになっています。
ChatGPTが一番分かりやすい例と思いますが、なんらかの問合せを書くようなフロントの画面があって、そこで聞きたいことを書くとバックエンドの裏側ではLLMのサービスがあって、モデルに問合せつつ、解答を作っていきます。
このLLMのモデルに学習データを食わせたり、はたまたプラグインを介して、外の情報ソースのデータも組み込みながら解答を作っていくというようなアーキテクチャになっています。
10個、1つ1つ細かく今日は説明できないんですけど、僕が注目すべきと考えているところは、LLM01とLLM02あたり、特にプロンプトインジェクションです 。
あとは、2つ目として、安全が確認されていない出力ハンドリングということで、先程の論文の例でもありますけど、なぜこういう問合せをすると、こういった出力がされるのかという、出力のバリエーションが想定できないという中で、それはちょっと出力されると困るなっていったものをどのようにハンドリングしていくかっていうところが、2番目の脅威になっています。この2つが、特に重要というか、LLMのアプリケーションを考えていく上では、特徴的な脅威と個人的に思っています。
それ以外の脅威に関しても当然モデルの盗難とか、あとは過度の信頼については、LLM02に絡む部分ではあると思います。出力されるような結果が、どこまで実際に信頼に足るのかという話は、多くの人がその信頼性といったところを気にしながら、LLMと向き合っているところと思います。ChatGPTの出力することを全部鵜呑みにする方はいらっしゃるような気もしなくはないですけれども、ただそういったところを気をつけなきゃねっていうのは、多くのメディアで取り上げられていますよね。ある程度LLMに関わっている方であれば、その信頼性というものをどう評価するかっていうところに、すごく頭を悩ませていたりするかなと思います。ディープフェイクのようなところでの使われ方もあると逆にそれをどう見破るのかっていうところでも、すごく難しい問題だなと思います。1つの特徴ではありますが、OWASPではこのようなまとめられた方がされています。
多分これ坂本さんも見ても思うと思うんですが、別にLLM関係なく、今までのアプリケーションでも、対策としては同じような対策になるよねっていうようなものって、結構ありますよね?
WEBアプリケーションのセキュリティ対策との共通点
坂本:そうですね。普通にDoS(Denial of Service)とか、例えば。普通にWEBアプリケーションだったら、DoS対策しなきゃいけないというところもあります。
サプライチェーンなんかもやっぱり昨今サードパーティの、最近でもxzの問題とかが話題になっていましたけど、そういったところに脆弱なものを入れられる、且つそれに気づかないで、バックドアを仕込まれる、そういったことも、もちろんありますしとか。そうですよね。
入出力をちゃんとバリエーションしようという話も、一般的なWEBアプリケーションないしは、普通にアプリケーションを作る中では、よくある話かなとは、そういう感じではありますよね。
日比野:そうですよね。その辺りも見てみて改めてLLMだからといって、主にインフラ周りのセキュリティは、そんなにビクビクする必要はないのかなっていうのも一緒に坂本さんとディスカッションしながらセキュリティの対策を検討していく中で、そこまで今までのインフラと変わらないけど、やっぱり違いってここだねってみたいなところはOWASPを見ながらも、特に入出力のところって特徴的だよねっていうところが把握できました。こういうのは俯瞰して捉える意味では、すごく重要なガイドラインだなと多分坂本さんも思われたかなと思います。
まずここから始められたいうのは、時間短縮っていう意味でも非常に良かったと思っています。他にいろいろとネットや書籍などでドキュメントを探っていくと結構これをリファレンスしている方が多く海外のベンダーさんのウェビナーを見てても、このOWASPを中心に製品考えていますとか、あとはこれの説明をされているようなドキュメントが非常に多いので、ここを参照されている方は多かったなと印象的には感じています。
坂本:そうですね。最初に日比野さんが言ってたように、150ぐらいのユースケースとか、脅威をベースに、こういう脅威があるよねっていうことを考えていると思うので、最初に考えるべきところとしては、あんまり外れてないのかなと、そういう印象ですかね。
日比野:そうですね。予防策などの対策についてもLLM ApplicationsのこのOWASPの中にも書かれているんですけれど、そこをキャッチアップしつつも、2つ目の観点ですかね。これらGen AI系のサービスでどのようなセキュリティ対策が実装できているのかについて、自分たちで調査し、これが代表的なセキュリティ対策の項目・評価軸みたいなところを表にまとめていきました。これをさらに細かくブレイクダウンして、もっと細かな比較表というのを作って、比較軸でまとめてたりしますけど、今日は代表的なところをピックアップしています。
生成AIのセキュリティ対策の評価

ちょっと中途半端な数ですけれども、左側に14 項目書いています。この比較軸を作りつつ、よく使われるOpenAI系のところで3つ、ChatGPT Plus、APIでOpenAIをレスポンスするOpenAI API、あとは検討している中で出てきていたChatGPT Enterprise、このあたりはOpenAIのサービスのバリエーションを3つ書き、IaaSベンダーさんの出しているものでMicrosoftのAzure OpenAI Service、AmazonのBedrockの5つのサービスを中心に比較表を作成しました。
どんな対策がどれだけ施されていて、ここでは、◯、△、×という表現になってますけれども、実際の検討していく中では、どういう機能でそれを実装しているのか、コンテンツフィルタリングみたいな機能が実装されていて、どういったところまで制御できるのか、自動でチェックしてくれるのか、認証については、例えばAWSのBedrockであれば、AWSの中にIAM(Identity and Access Management)の機構を持っていますので、そういったIAMでこういった制御ができますよとか、監査ログでいうと、CloudTrail、CloudWatch Logsみたいなところが、こういったBedrockにたいしてのログをこういうふうに出力してくれますよみたいなところですね。細かな実装の部分は、ここでは表現はしていませんが、ここではわかりやすく、○、△、×っていう形でまとめたものの一部をちょっと表現させていただいています。製品の実装を調べていくとこういう機能が実装されているから、ここも評価軸に足して、他のサービスはそれに対して、どこまでできているのかっていうのをサービスを深掘りしつつ、評価軸を作り続けつつ、評価軸をまとめながら、また他のサービスに移って見ていって評価して、そこの中では逆に違う評価軸になりそうなものを持っていたりするので、行ったり来たりする中で、こういったところの評価を実際はやっていきました。
技術面が中心ですけれども、このピンク色で色付けしている部分が、多くの企業様では気にすべきポイントになるのかなと考えています。さっきの入出力という話で言いますと、1番の機密情報を出力させないようなフィルタリングはAzure OpenAI Serviceであったり、Bedrockであったり、既存プラットフォームが出しているようなサービス、特にIaaS周りのベンダーさんのサービスにはこういう機能が実装されています。

あとは入力値のバリエーションの差に対するところは、同じくかなと思っています。
この入出力といったところの機能は、差が出てくるところかなというところと、あとはこの9番、10番、プライベートネットワークの接続だったり、日本リージョンで使えるのかどうかっていったところ、主にネットワークとか、物理的なロケーションみたいな話に関しても差がつくポイントだと思います。特に日本のお客様に関しては、このあたりすごく重要視されていますので、こういったところを比較することによって、自分たちがプロダクトの中で生成AIを組み込んで使っていこうとした時には、特に気にすべき重要ポイントになるのかなといったところも、こうやって比較して俯瞰してみると、なんかグラデーションが出てくるなというのがあります。これは非常に面白かったなと僕は思っているんですけれど、この辺りで坂本さんは気になったこととか、実際やっていく中で、この辺りが面白いなとか、何か気になっているところはありますか?
坂本:そうですね。開発者目線だと、AzureとかAWSとかって、もちろんIAMだったり、そういう認証とか含めて詳しく知っているので、別にそういうのをきちんと考えてできる人もいますけれど、そうじゃなくて普通にアプリケーション書くのに興味があるような人ってOpenAIの方がAPIキーとかを発行して、あとはSDKにOpenAIのAPIキーを入力したら、すぐに開発できるような話になるので、開発者って目線だと、OpenAIで作って、且つモデルとかも一番新しいものができたりするので、そこで作っていきたいというところがありつつ、やっぱり本番環境できちんと運用していくとか、お客さんがきちんと運用するとかで、気にしなきゃいけないこととかを考えるとOpenAIじゃ足りないような機能がいくつかあるよねっていうところで、まさに日比野さんが言ってくださったような、×になっているような部分とかっていうところで、IaaSのベンダーとかが出しているサービスであれば、こういうことができるよっていうところが、この表とかを作ることで、すぐパッとわかるようになったと思っています。
開発者の人に見せても、OpenAIとかAzure OpenAI Serviceとかをやっぱり対応した方が、お客さんとしては、安心して使える要素が多いよねとか、そういう生産的なディスカッションがすぐできるので、そういう面でもこの表を準備していただいて、よかったなと思う点ですかね。
日比野:実際にこれって日本リージョンとか東京リージョンって、データが日本から出ないんですよねみたいな質問とかって、お客様からされますか。
坂本:そうですね。やっぱり我々エンタープライズのお客様が多く、セキュリティチェックシートのような形でこういったセキュリティどうなってますか?とか、聞かれることがよくありますけれど、その中でも日本リージョンに閉じていますか?とか、プライベート接続だけになっていますか?とか、プライベート接続じゃないと、こういうちょっと機密度が高い情報っていうのは扱えませんとか、そういった話ってされるお客様っているので、このあたりは重要なこと。
これは別に日本に限らず、もちろんそれぞれの、例えばEUだったら、EUの中からデータを出しちゃいけないとか、もちろんあります。
アメリカの中でも、もちろんそういったものがあったりしますし、そういったところは気にされるお客様もやっぱり、気にされるポイントなので、そこに対してきちんとこういう形でやっているので大丈夫ですよとか、そういったことをきちんと説明できるようにする必要があるかなと思います。
日比野:たしかにそうですよね。チェックリストに答えていく形になりますもんね。
坂本:そうですね。あるいは、我々からこういう形でやってますよって発信していくっていう形もありますけれど。
日比野:チェックリストの中に、今後これどう考えても生成AIのことを気にしてないとかチェックリストの項目に入ってきたりするんですかね?
坂本:それまでもそうですよね。きっとなんか、ありえますよね。おそらく。
日比野:ありえますよね。
坂本:はい。やっぱり、AWSを意識して書かれているチェックリストとか、AWSだったら、こうだよっていうチェックリストとかが、例えばあったりもするので。より生成AIっていうのが、一般的になってきて、どんどんアプリケーションを使っているとなると、やっぱり企業の中のセキュリティ担当の人は、その辺りを気にしないといけないよねって形で、気にしなきゃいけないことはチェックリストとして追加されて、そこをベンダーとお客様で情報をやりとりしなきゃいけないよねって場面が増えてきて、やっぱりその辺りに課題感を持って、お客様側も、このベンダーにデータを預けて大丈夫なんだっけ?って聞きますし、逆にベンダー側も色々なお客様から色々なセキュリティの質問が飛んできて、全部解答しなきゃいけないっていうのが大変だよっていうこともあって、その辺りをどうにかしようっていうところで、セキュリティ関係のスタートアップとかでもソリューションを考えてやっているところかも、いろいろありますよね。
日比野:ありますよね。そうですよね。チェックリストに学習データは再利用されない形をとってますか?とか、チェックリストが入ってきたら、とうとうきたかみたいな気分になるかもしれませんね。
坂本:はい。でも、その点でいくと、dotDataとしてはAIのアプリケーション、生成AIではないアプリケーションとしても、以前から作っていて、そういう面ではその製品に入れるデータを他の用途に活用しませんよねってことを、もちろん気にされるお客さんも、生成AIに限らず、そういうことはあるかなと捉えてます。
日比野:そのナレッジは大きいですよね。別にChatGPT関係なく、そもそもそこが主戦場だと思われるので、やっぱりその辺りは、なんかいいなっていうと変ですけれど、重要なポイントがきちんと元々ケアされているので、すごくお客さまにとっては安心感あるのかなと聞いていて思いました。
坂本:ありがとうございます。
生成AIのセキュリティを難しくしているところ
日比野:こういったところの2つの軸でまとめて考えていったんですけど、すでに喋っちゃてるところがありますが、改めてということで、何がこの生成AIのセキュリティを難しくしているのかっていうところ、1スライドで表現するとこういうところかなと自分は思っているので、今回こういうような図を用意させていただいています。
やっぱり入出力のコントロールが難しいっていうところで、人間はどんどん自分たちの作業を楽に効率よくしていくためにシステム化して、システムにそれをプログラムして、決まった命令をすれば、決まった入力値に対して、決まった出力、期待する出力が出て、それが期待していた出力が出ないものはバグという表現になって、修正を加えていって、人が想定したものをシステムにお願いするっていうのが、このITが当たり前になった世の中の常という形だと思っています。

人間の代替をする上で、全ての領域、当然カバーできないところもあり、こういった生成AIのような人工知能って言っていいのか、かなり広い幅になりますが、そういったこのLLMを中心としたアプリケーションを作ることで、人間らしさみたいなものを組み込んでいくと、今度はシステムが人間らしくなるって、どういうことなんだろうか?っていうふうに考えた結果、やっぱりこういうことかなって思っています。
人間の自由度みたいな、人間に毎日同じインプットを与えても、同じアウトプットにならないっていうところが人間らしさかなと思うと、至極当然かなと思っていて、これが結果的に生成AIのセキュリティっていうところを考える上では、なんかシステムっぽくない、人間をマネージするようなセキュリティ対策を考えなければならないっていうところが、矛盾というか、面白い考え方だなというふうには、自分は整理していて思っています。こういったところが、すごく難しくなってきているポイントかなと思っています。
坂本:たしかに、少し聞いていて思ったのは、ソーシャルハッキングみたいなところと、このプロンプトインジェクションみたいなところは、少し似てる部分があるかなというか、こういう入力を与えたら、こういうことなんでしょう。人間がやってくれるのか、LLMがやってくれるのかわからないですけど、そういうふうに誘導していくというか、似ているところはあるのかなと。
日比野:そうですよね。人間を騙すかのように、LLMを騙すじゃないですけど、詐欺の電話みたいな感じの動きになるので、すごく面白いなと思っています。その入出力をコントロールしていくっていうところでいくと、このOWASP Top10の脅威はLLMの01番のプロンプトインジェクションが主にインプット部分っていうところの、今坂本さんがおっしゃったようなところのプロンプトの部分で脅威として考えられる部分ですね。
2つ目の出力に関していうと、LLM02の安全が確認できていない出力は出力のハンドリングであったり、あとはLLM06の機密情報の漏洩といったところ、主にこういったあたりが、LLMの人間らしさが出ることによって、コントロールが難しくなるような脅威だなと自分は思っています。
生成AIのセキュリティ対策
それに対応するようなセキュリティのソリューション、対策といったところでは入力値のバリエーションやサニタイズというのを、いかにこの自由度の高いプロンプトの中でリスク低減を図っていくか、ここが一つのテクニックになるかなと思っています。

入力をある程度コントロールできれば、出力のリスクというものを減らせるというのがあるので、出力を絞るより、まず入力を絞ろうみたいなところ、データソースに近いところで絞る方が、後工程で絞るより費用対効果が高いんじゃないかというところがあるかと思っています。
ただ、ここを絞りすぎるとそもそもビジネスとして、この強力なLLMアプリケーションを使った良いサービスを作ろうというところにだいぶ制限がかかってしまって、目標としていたアプリケーションが作れないというケースもやっぱり出てきてしまいますので、ここの匙加減も非常に難しくなりますし、ロジックをどう作っていくかというところも、すごく頭を悩ませるポイントだなと思っています。
自動化と人間による品質担保の矛盾と楽しさ
ここだけで対策しきるのは難しいと思っていますので、入力の自由度をある程度許容していきながらも、特に機密情報の漏洩という部分に関しては、DLP(Data Loss Prevention)というようなソリューションは、LLMに限らずありますので、そういった機密情報、特に個人情報であったり、あとは金融関連の口座情報、カード情報みたいな、ある程度ロジックができあがっているような出力に関しては、フィルタリングできるということは、こういったところで応用ができると思っています。
やっぱりこれが人間らしくなってくるところで、特徴的だなと思っていますし、結構坂本さんとも、この手の話、雑談でしたかと思うのですが、出力という部分を最終的にシステムにお願いしつつも、人による出力チェックというHuman in the loopというような、ソースコードレビューも、その一つかなと思ってますけど、こういったところで、自動化しつつも、やっぱり最後の最後、こういうところは人間が品質を担保しようみたいなことはLLMにもやっぱり現れてきているなというところが特徴的だったなと思っています。
このHuman in the loopの部分って、やっぱり矛盾をはらんで面白いかなと僕は思っているんですけど。
坂本:そうですね。はい。自分はソフトエンジニアとして働いていて、やっぱり自分が楽したいから、いろいろ自動化して楽しようと思って、プログラムを変えたり、システム作ったりするわけですけど。
でもそれを突き詰めて、色々なこと、幅広いタスクをやらせようとしたら、結局は最終的な品質担保は人がやらなきゃいけないケースが結構あるよというのは、面白いところでもあり、そこを含めてよろしくやってくれたら一番いいけど、やっぱりハルシネーションの問題ってなかなかそんなに簡単に解決できる問題でもないので、やっぱりそこは、どういうことをやるにかにもよりますけども、もちろん例えば絵を描いて欲しいとかで、その絵が別にどうなろうと、別にそれがいい絵だなって思うくらいあれば、別にどういう絵でもいいんですけど、やっぱりクリティカルな業務システムに繋がるような出力を生成AIが作ったり、それが特に検証されずに、そのまま使われると、やっぱりひどいことが起こるんじゃないかっていうところで、そこは人が入りましょうとか、もちろんそのグラデーションがあると思うので、そこはどういう要件があるのかっていうことを見極めて適正なことをやる必要があると、まあそういうことだと。
日比野:そうですね。最近だとEUのAI法案では、このLLMを採用しても問題がないシステムというか、領域っていうところをリスクが高いシステムでは許容されない。使うことを許容しないとか、どういったシステム、重要性の高いシステムなのか、そうじゃない今おっしゃったようなシステムなのかによって、LLMっていうところを適用しても問題ないのか、それともそこは基本的に適用する範囲じゃないっていうふうに、こういった法律でも、基本的にその辺りを明確に定めてたりもするので、生体認証を使うような重要なシステムの中ではLLMを組み込むなとか、法律の中で定めてたりとかするので、そういうのもスコープ自体を法律で狭めてしまうところもあります。そこをそれは法律なんで当然やったらダメですけど、そこの法律にはもう守れているんだけども、やっぱり重要性の高いシステムというものに関しては、対策の仕方として、やっぱりそこまで人がチェックするということで担保するっていうのも、1つの対策のやり方なのかなと僕も少し思ったりするので、そういうところを含めて、どうやってシステムを組み上げていくかっていうのが、重要なポイントなのかなと個人的には思っています。
そろそろいい感じの時間になってきてますけれども、dotData Insightの中で、今日僕がお話ししたようなポイントを、実際どういう形で実装に繋げていったのかみたいなところって、坂本さんの方で特徴的なところとか、特に気にしたポイントとかって、どういったところがあったかって聞いてもいいですか?
終わりに:実装から学ぶ生成AIのセキュリティの重要性
坂本:やっぱり、どういう情報がそもそもLLMに送られるかっていうところだったり、結局そこから出てきた情報がどう使われるかが、ここでいうインプットとアウトプットのところですけど、そういうところをちゃんと考えて、それがちゃんと考えられた上で、じゃあ、そのインプットがこういうふうに操作されたら、何が起こりうるんだとか、出力にこういうものが入ってきたら、何が起こりうるんだということを考えて、そういうことが起きた時に他の部分でセーフガードがきちんとかかるような仕組みになっている方だったりだとか、そういうことをやっぱり考えるっていうのがありましたね。
具体的なリスク管理と対策の例
例えばアウトプットの方だとdotData Insightの事例と少しずれるかもしれないですけど、例えばよくデータ分析とか、データ解析っていうところだと、自然言語で問い合わせたら、裏側ではSQLを作って問い合わせて、データを取り出したいっていうユースケースは結構あると思うんです。やっぱりSQLをとりあえず作ってくれるけど、そのSQLが本当にそのまま実行できちゃう、生成されたものをバリデーションせずに、そのまま使ってしまうと、本来はアクセスできないデータかもしれないのに、勝手にそのデータにアクセスして結果が出てきてしまう。
そんなことを何も考えずに作ると、そういうことが起きてしまうと思うんですけど、一方でSQLとしては、その権限を守ってないような広範囲なデータが取れるSQLが例えばLLMが作ったとしても、そのSQLを実行する部分で、きちんとそのアクセスコントロールとか、Authorizationができていれば、たとえSQLで非常に広範囲なデータを取ろうとしても、実際にSQLを実行するタイミングではランタイムで権限がないということで、エラーになるだとか、そういうことをきちんとできてるんだっけっていうところをインプットとアウトプットで見て、対策ができてるんだっけとか、こういうシナリオがあったらという対応に守られるんだっけっていうところを、やっぱりきちんと考えて検証して大丈夫だよねっていうところを見ていく。
そういうようなことの、繰り返しだったりとか、その時にそれをもっと効率よくできるようには、するにはどうすればいいんだろうとか、セキュリティだと多層防御っていう形で、2層、3層用意しておいて、全部すり抜けなければ守れるよねっていう仕組みで担保するだとか、そういうことって例えば入力値でも、最初機械でフィルタリングしてなんでしょうね。おかしなものが入ってこないようにするっていうものを、付け加えるだけでも、かなりそこで落とせるものってあるかもしれないしとか、そういうことをいろいろ考えて、dotDataをどういうふうに扱うことで、安全に使えるかってことを考えていくというか、そういう感じですかね。
日比野:なんかテストシナリオを考えるのってやっぱりLLMだと大変ですよね。
継続的な学習と改善の重要性
坂本:そうですね。いろんなケースが考えられるのでというところだったりとか、やっぱり出てくるのもがあまり予想できないようなものが出てくるので、やっぱり完全にテストしきるっていうことが、難しいところはもちろんあります。
日比野:想定した結果が、例えば5回やってみたら、5回とも違う結果が出るみたいな。そういうこともありえそうな気もするし、テストで何を見るかってすごい難しそうですよね。
坂本:そうですね。やっぱりテストで完璧に仕上げて、もちろん一定の品質を保てるようにこういうシナリオで、こういうふうにテストしてっていうのは、もちろんやりつつ、やっぱり本番、我々の製品だと、よくあるのは、色々な性質のデータがあって、そういうデータを、特性のデータに組み合わせて、もちろんテストではカバーしきれて、お客さんのデータって本当に色々なバリエーションがあるので、そのすべてをテストするってやっぱりできないので、本番でやっぱり何かを実行した時に、データに起因する何らかの問題が出るっていうことって、もちろんあると思うんですけど。
やっぱりそういうものが出た時に、そこから学んで次のリリースでは同じような問題が起きないようにするってことはできますので、もちろんやるっていうのは、もちろん当然ですけど、一応そこでランタイムで問題が出る時に、クイックに検索して、例えば修正するとか、そういう部分を考えて、きちんと作っておくということも結構大事かなと思います。
日比野:それはランタイムで色々な、例えば権限エラーが出たりとか、想定していないエラーが出るってことをトリガーにして、このケースが出力されているんだ。じゃあやっぱりテストでこういうことを考えなきゃとか、そういうような学びをフィードバックしていく形になるんですか?
坂本:そうですね。はい。それはどういった問題かにもよりますけど、そうですね。問題が起きていることを、もちろんシステム側で自動で検知できると一番ベストですけど、もちろんユーザーが使ってて、明らかにこういうデータを取り込んだ時に、全然期待する結果と違うものが出てくるよって言われるケースというか、もちろんSaaSで自分たちが完全に、全部ホストしてる場合だったら、お客さんのデータももちろん見ようと思えば全部見れるのかもしれないですけど、我々の製品だとお客様の環境とかにホストしているようなケースとかもあって、そういうものって、我々がデータとかを必ずしも全部見れたりするわけではないんですよね。
そういうケースだとやっぱりそこでデータ依存で問題が起きた場合は、お客さん側に少しヒアリングさせていただいて解決するっていうところがあります。
そこをいかにクイックに解決して、お客さまがきちんとビジネス価値を出せるような活動に集中してもらえるような形にできるかっていうところは、単に全てを完璧に仕上げて出すというところ以外にも、そういう面でもできることがあるのかなと。
日比野:面白いですよね。そういったことをリスクも当然考えるとは思うのですが、そういったことをチャレンジしながら製品にいち早く組み込みつつ、お客さんと一緒にしながら、よりいい価値とか、何かアウトプットを得ようとするところ、今日話もいろいろ聞けているので、僕自身も聞いてて面白いなと思うので、すごいいい取り組みに関わらせていただいたなって、個人的にちょっと思いました。
坂本:そうですね。やっぱりお客さんに対してはそうですね。こういうふうに使いたいんだけど、こういうこと懸念だよねってお客さんと話すと出てくることってあるので、やっぱりそういうことをいかにこういう仕組みで、こういうふうにすれば大丈夫ですよねっていうところを早くきちんと仕上げてお客様に提供していけるかっていうところが、製品を作っているものとしては、きちんとやっていきたいなと思っているので、お客さまにより安全に、より大きい価値を届けられたらといいなと、そういうふうに思って作っていますという感じです。
日比野:はい。了解です。ありがとうございます。
坂本:というところで、生成AIのセキュリティというところで、dotDataが、dotData Insightという製品を使って、その中で生成AIを使っていますよというところとか、LLMのセキュリティで、どういう問題があるかだったり、セキュリティに関して、どういうことを気にしなきゃいけないかとか、そういったところを、今日はお話しさせていただいたので、1つでも、2つでもその中で学びがあり、持ち帰ってもらえるものがあればなと思います。今後も我々も生成AIを使った機能とかを、どんどん使っていく中で、どんどん便利にしつつきちんとセキュリティだったり、レギュレーションだったり、気にしなきゃいけないことをこなしていけるようにしていく中で、また新たな知見や学びがあれば、そういうものは積極的に共有していけたらなというところで思っているので、引き続きよろしくお願いします。
今日の生成AIのセキュリティのセッションは、このような感じで終わりということで、もしdotDataについて今日の話に興味があるよとか、この生成AIのセキュリティについて、もっと深掘りしたいとか、そういうのがあれば、気軽にお問い合わせフォームから連絡いただければと思います。
ご視聴いただきありがとうございました。
日比野:ありがとうございました。
坂本:日比野さんも、ありがとうございました。