
LLMとは? – 大規模言語モデルのデータアナリティクス応用
- データ分析
- 生成AI
- ビジネスアナリティクス
生成AI(ジェネレーティブAI /生成系AI)は、さまざまな業界で大きな変革を起こし始めています。このブログシリーズは、企業におけるデータ活用の新しい地平を開く、生成AIの可能性について解説します。その第二弾となる、本ブログでは、生成AIの仕組みであるLLM(大規模言語モデル、Large Language Models)と、そのデータ分析への応用例を紹介します。
生成AIに関する基本的な解説や画像生成AIとしての解説、識別系AIとの違い、生成AIの活用サービスなどについては、既に多くの記事で扱われているため、本ブログシリーズでは、生成AIの活用事例や、生成AIの仕組みとしてLLM(大規模言語モデル)、LangChainなどのトピックを、「企業のデータ活用」という切り口に焦点を当てて解説していく予定です。
生成AI、LLM(Large Language Model)、そしてGPT(Generative Pre-trained Transformer)は、どのような関連性を持っているのでしょうか?以下は、ChatGPTのGPT4にその関係を問い合わせた結果です。
生成AI(Generative AI)は、人間のようなコンテンツ(テキスト、画像、音声など)を作成する技術群を指します。この中で、大規模言語モデル(LLM)は、膨大なテキストデータから言語の構造を学習し、新しいテキストを生成する特化したAI(人工知能)の一種です。GPT(Generative Pre-trained Transformer)は、LLMの一例で、特に事前学習と微調整のフレームワークを用いて、幅広い言語タスクに適応可能なモデルです。GPTは、会話応答、文章生成、翻訳といった様々な応用が可能で、その柔軟性と汎用性から、生成AI技術の代表例とされます。つまり、GPTはLLMの具体的実現形態であり、LLM自体は生成AIの広範なカテゴリー内に位置付けられます。

このように、LLMは、特に言語生成を目的とした生成AIのモデルやフレームワークを指す総称であり、GPT(Generative Pre-trained Transformer)は、大量のデータから学習して言語を生成する機能を持つLLMの一つの具体的な実装例であると理解することができます。本ブログでは、LLMとGPTは区別せず、ほぼ同じ意味として説明していきます。
なお、関連した技術としてディープラーニング(深層学習)があります。ディープラーニングは、巨大なパラメータ数をもつ多層ニューラルネットワークとよばれる機械学習モデルとその学習技術全般を指します。LLMは、ディープラーニングの一つの応用例で、特に自然言語を扱うタスクに対して最適化されています。
LLMは(大規模言語モデルは)、その名称が示す通り、言語生成を得意とする自然言語処理モデル(或いは、自然言語モデル)の一種です。この能力を活用して、自然言語での問い合わせの意図を把握し、それに応じたプログラム言語のコード(コードジェネレーション)を生成することが可能です。
この技術を用いることで、データ分析における前処理やデータ加工の工程においてもLLMを活用することができます。例えば、以下に示すのは、GPT4を使ってデータクレンジングを行うSQL文を生成させた場合の一例です。
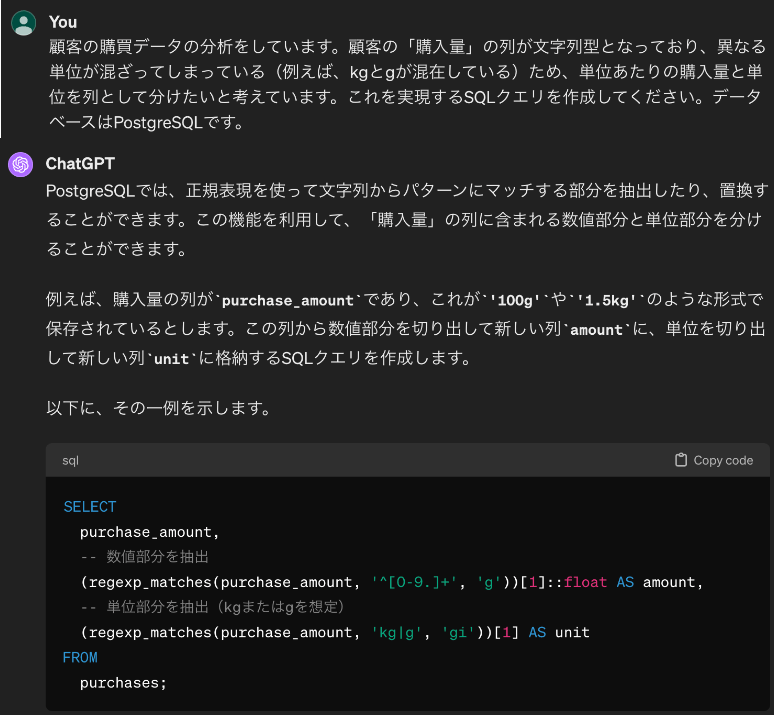
このように、GPTに対して特定の前処理を実施したい内容を指示するだけで、ユーザーが直接プログラムを書く必要がなくなります。提示した例は基本的なものですが、ノーコードインターフェースと組み合わせることで、より高度なデータ前処理やデータ加工を、自然言語の指示だけで実施することが可能になります。また、データ前処理に関する新たなアイデアをLLMに提案してもらうこともできます。
コードジェネレーションの技術を応用することで、自然言語による問い合わせだけで様々なデータ可視化を実現できます。以下に、アメリカの人口を州ごとに可視化する例を紹介します。
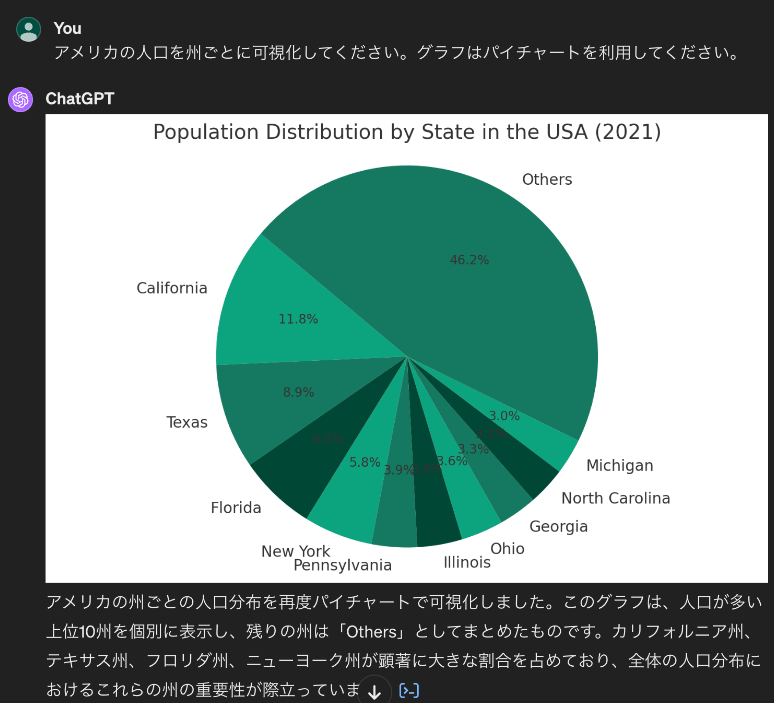
この例では、可視化対象のデータ(アメリカの州ごとの人口)をLLMを通じて取得しました。もちろん、自身で指定したデータを用いることも可能です。このプロセスの背景では、Pythonによる可視化コードが生成され、この場合、ChatGPTがPythonの実行環境と自動的に連携して可視化結果を出力しています。
このようにLLMを活用することで、簡易な可視化なら従来のBIツールを用いるよりも遥かに容易に実現可能です。ただし、現在のところ多くのLLMが直接扱えるデータ量には限界があり、また計算量の増加によりコストが大きくなる点には注意が必要です。
データが複雑になるとハルシネーション(ブログ1参照)のリスクも増えます。そのため、LLMの可視化結果を盲目的に受け入れるのではなく、直感に反する結果が得られた場合は元のデータを検証し、真偽を確かめることが重要です。
LLMは、データ加工や可視化といった単一のタスクに留まらず、より複雑なデータ分析タスクもこなすことが可能です。次の例では、従業員データをCSVフォーマットで入力し、サマリーレポートを作成しています(データソースはKaggleのオープンデータを使用)。
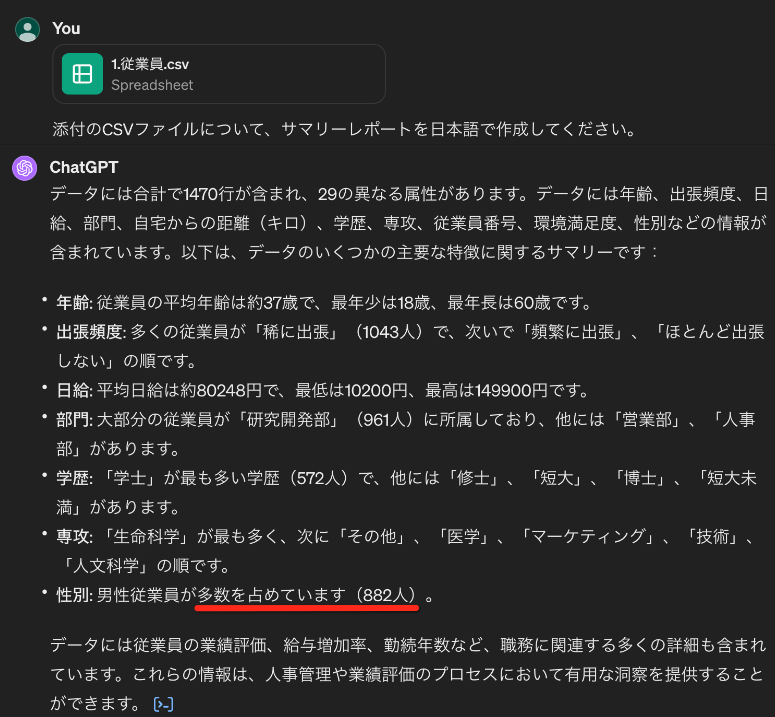
この例を見ると、「サマリーレポートを作成してください」という抽象的な要求に対しても、LLMがデータ項目ごとの概要を自動生成していることが確認できます。一方で、性別のサマリとしては男性が60%(882/1470)を「男性従業員が多数を占めています」と解釈しており、単に生成AIの日本語を鵜呑みにするのではなく、その背後の数字の確認には注意が必要です。
これまでの3つの応用例を組み合わせ、より具体的な指示をLLMに出せば、データの加工、レポート作成、そしてレポート内でのデータ可視化という、データ分析プロセス全体をLLMのサポートによって大幅に簡素化できます。現時点ではLLMの技術的な限界が存在し、データ分析実務で利用するとなると、このブログで紹介されているような単純な例のようにはいきませんが、近い将来、企業のデータ分析に革命をもたらすことは間違いないでしょう。ブログ1では、この変化に伴い求められる企業のデータ人材のスキルについて議論しました。このようなデータ分析の新しいアプローチは、事業部門を中心としたビジネスアナリティクスの推進力となるでしょう。
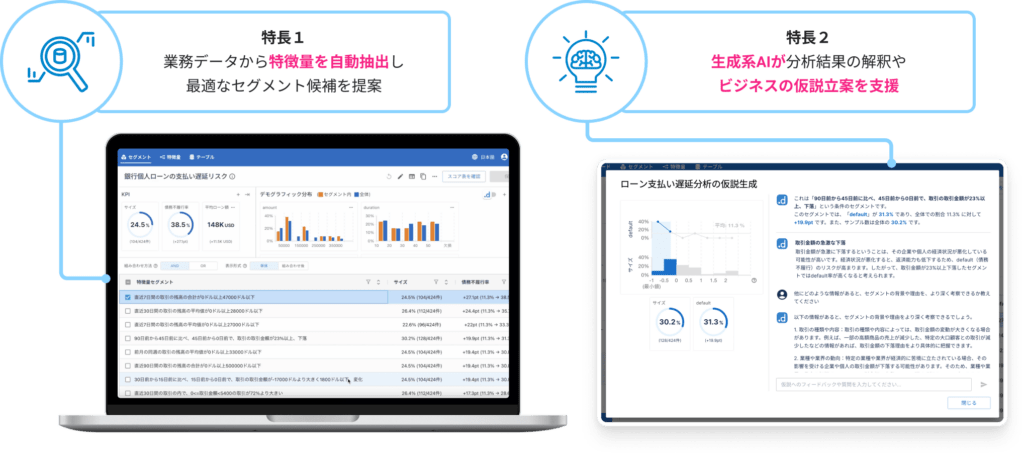
dotDataでは、「データからの知識」である特徴量と、生成AIを融合したdotData Insightによって企業のビジネスアナリティクスを推進しています。dotDataの独自のAIが、従来の手作業による分析では発見することができなかった、或いは、数週間から数ヶ月もの時間がかかっていた、複雑な業務データの重要なパターン(特徴量)を抽出します。dotData Insightでは、データの品質の改善、生成される特徴量の自然言語による説明、特徴量に対するビジネス解釈の支援など、さまざまな用途でLLMを活用しています。dotData Insightを利用することで、統計的事実としての特徴量をdotDataのAIが導き出し、その解釈や洞察に基づいた施策の立案を、LLMが対話形式で支援します。
生成AIブログ – パート1 :生成AIとは? – 生成AIは企業のデータ活用をどのように進化するのか?
生成AIブログ – パート2 :LLMとは? – 大規模言語モデルのデータアナリティクス応用(このブログ)
併せて読みたい :LLMをローカルで動かす方法:Ollamaで最小構成からスタート


