
カテゴリ属性に対する特徴量設計
- ブログ
データは機械学習やAIにとって中心的な存在です。各データセットには一般的に、数値だけでなく非数値(カテゴリ)の属性が含まれています。機械学習の目標は、これら両方を含む利用可能なデータに基づいて、正解である値を予測するモデルを構築することです。以下に示すデータセットの例は、Kaggle(Student Performance Data Set | Kaggle)で公開されているものです。このうち性別、人種/民族、親の教育レベル、昼食、テストへの準備、コースといった属性は非数値のカテゴリであり、数学のスコア、リーディングのスコア、ライティングのスコアといった属性は数値に分類されます。
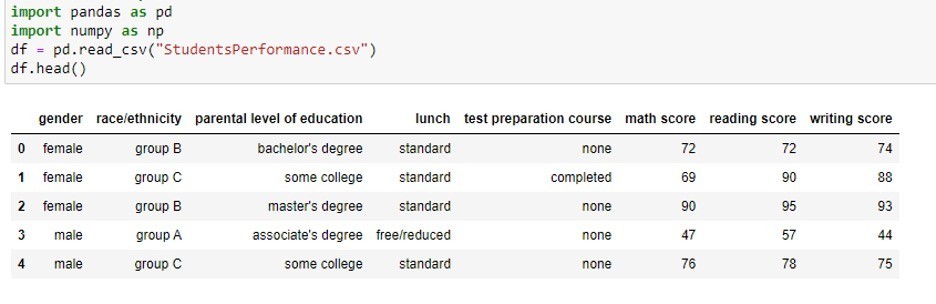
これらのうち、数値的な特徴量は分析が容易であり、ターゲット変数への影響も簡単に分析できます。一方、一部の機械学習アルゴリズム(例:決定木などのルールベースのアルゴリズム)はカテゴリ属性を直接扱えるものの、多くの機械学習アルゴリズムは入力属性が数値であることを前提にしています。また、カテゴリ属性とターゲット変数の間の「相関」を分析するのが難しいのも課題の1つです。このようなカテゴリ属性の課題を解決するために、カテゴリ属性に対する特徴量設計が必要となります。
一般的に特徴量設計では、データを操作したり変換したりして、ターゲット変数の予測に役立つ情報を抽出します。例えば、データの表現方法の変更や、統計的手法による新しい属性(特徴量)の生成といったものです。
カテゴリ属性に対する最も一般的な特徴量設計の方法は、カテゴリ属性を数値表現に変換するというものです。これは、カテゴリ値を数値へとエンコード(符号化)し、これによって多くの機械学習アルゴリズムにとって扱いやすい新しい数値属性を生成します。特徴量設計によって、データサイエンティストはカテゴリ属性の情報を迅速かつ柔軟にMLモデルに取り込むことが可能です。
数値表現(特徴量)を生成する際に求められるのは、カテゴリ属性とターゲット変数の関係を捉え、かつそれを保持することです。この記事では上述の「Student Performance Data Set」を例に、一般的なカテゴリ属性の特徴量設計手法について解説します。
dotData Feature Factory: Pythonデータサイエンティストのための特徴量自動設計
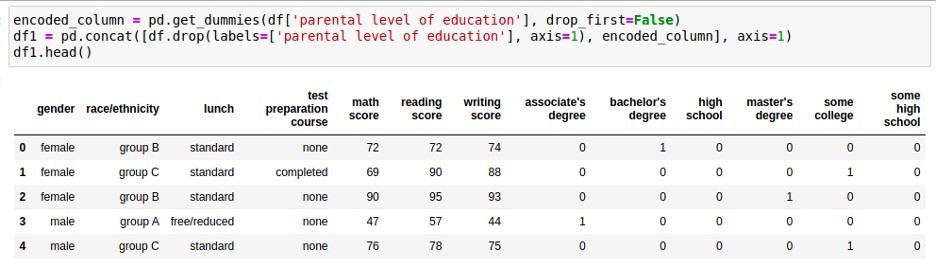
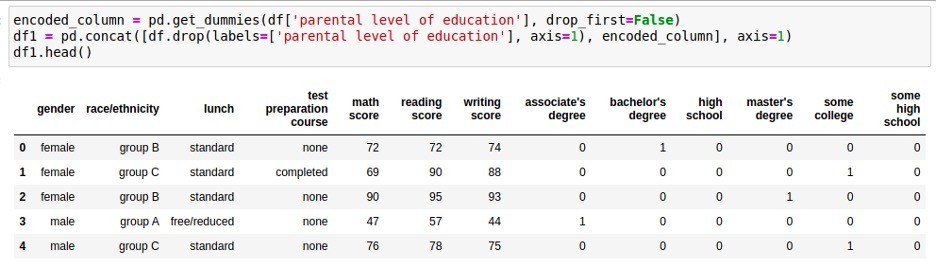
One-hotエンコーディングは最もシンプルかつ基本的な手法です。この手法では、各カテゴリ値に対してバイナリ(二値)の特徴量を割り当てます。あるカテゴリ値をとる場合は1、そうでない場合を0とするため「One-hot」と呼ばれています。One-hotエンコーディングによって生成される特徴量数は、カテゴリ属性のカテゴリ数と等しくなります。
あるカテゴリに「男性」と「女性」という属性が存在した場合、たとえば男性に「10」、女性に「01」という値を割り当てられます。より簡単にするなら下の桁を無視して、男性を「1」、女性を「0」と表現してもかまいません。カテゴリの属性が2種類以上存在する場合でも、同じ考え方で二値に符号化できます。新たに作成される二値属性(特徴量)の数は、カテゴリがN個ある場合N-1となります。
One-hotエンコーディングを適用すると、N-1次元の二値属性(特徴量)を新たなカラムとして、元のカテゴリカラムを置き換えます。One-hotエンコーディングを適用する主なメリットは、カテゴリカラムを、扱いやすい複数のバイナリ(二値)カラムにマッピングできる点です。また、新しいカラムは元のカテゴリ値に直接対応するため、One-hotエンコーディングによる特徴量は解釈が非常に容易であるという利点があります。
One-hotエンコーディングの欠点の一つは、各属性内のカテゴリ間の順序関係を表現できなくなる点にあります。たとえば「親の教育レベル」の場合、「修士号」は「学士号」よりも上位の学位です。しかしながら、One-hotエンコーディングによる特徴量ではこのようなカテゴリ間の順序関係を表現できません。
もう1つのOne-hotエンコーディング欠点は、カテゴリの数が多いカテゴリ属性を扱う場合に生じます。たとえば、小売業のデータセットにある「商品カテゴリ」カラムは100万ものカテゴリ数(商品数)を持つケースがあり得ます。そのようなカラムにOne-hotエンコーディングを適用すると、100万次元もの新しいカラムを追加しなくてはなりません。このような高次元の特徴量表現は学習結果の分散が大きいために精度の低下につながる、処理能力やメモリへの負荷が大きいなどの欠点となりえます。
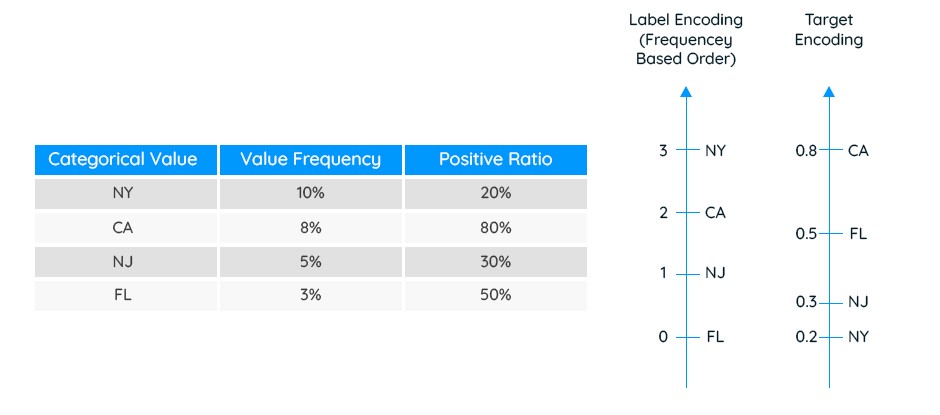
Labelエンコーディングはもう1つのよく知られた手法であり、カテゴリ値を0からN-1までの序数にマッピングするという直接的な変換をおこないます。各カテゴリ値は選択された範囲内のユニークな整数(または非整数値)に割り当てられます。たとえば(「学士号」, 「短大卒」, 「修士号」, 「準学士号」)は(0, 1, 2, 3)にマッピング可能です。
Labelエンコーディングは実装が簡単で、かつカテゴリ数の大きいカラムにOne-hotエンコーディングを適用する際の問題を解決できます。さらにカテゴリ値間の順序・分類関係を特徴量に導入可能です。
Labelエンコーディングには、カテゴリの順序決定が難しいという大きな課題があります。適切な順序を割り当てられれば、Labelエンコーディングは元のカテゴリ値の本質的な特徴を捉えることが可能です。しかしながら、適切な順序を割り当てられないとLabelエンコーディングの性能は低く、かつ理解が難しい特徴量が生成されるでしょう。ランダムによる順序割り当て、値の頻度、専門家による判断(手動)など、いくつかのシンプルでヒューリスティックな方法が役立つこともありますが、多くのカテゴリ値が存在する状況で、これらのヒューリスティックな方法をどのように適用すべきか難しい課題です。
元のカテゴリ属性に対してのみおこなわれるOne-hotエンコーディングやLabelエンコーディングと異なり、ターゲットエンコーディングはターゲット変数を用いてカテゴリ値から数値へのマッピングを算出します。ターゲットエンコーディングでは、ターゲット変数との関係が似ているカテゴリ値に対して類似した数値を割り当てます(その逆も同様)。これにより、ターゲットエンコーディングによる特徴量は、ターゲット値の情報を包含するため、多くのケースで機械学習モデルの改善に役立ちます。
以下の例で判別問題におけるLabelエンコーディング(カテゴリ値の頻度順)と、ターゲットエンコーディングの結果を示します。この例ではターゲットエンコーディングに単純な尤度ベースの方法を使用しました。ターゲットエンコーディングの特徴量の値が大きいほど、対応するカテゴリがターゲット変数と高い相関を持つことになります。
ターゲットエンコーディングの欠点は、オーバーフィッティングを避けるために多くの教師付データが必要になる点です。たとえば上記のデータセットで「WA」が1行しかない場合、陽性率は100%になってしまいます。この場合「WA」のターゲットエンコーディングの値は信頼できません。
dotDataでは、正則化付きのターゲットエンコーディング手法を適用し、小さなデータや低頻度のカテゴリ値に対してターゲットエンコーディングがオーバーフィットすることを回避します。正則化の程度はターゲットエンコーディング特徴量の予測力を最大化するために自動調整されます。
機械学習において特徴量設計は非常に重要であり、エンコーディングはカテゴリ値を表現する数値にマッピングするという、特徴量設計にとって必要不可欠なステップの1つです。
この記事ではOne-hotエンコーディング、Labelエンコーディング、ターゲットエンコーディングについて解説し、それぞれのメリットやデメリットを比較しました。現実の機械学習プロジェクトでは「唯一無二の」手法は存在せず、データの特性を分析した上で適切なエンコーディング手法を選択しなくてはなりません。dotDataのプラットフォームは、One-hotエンコーディングと正則化付きターゲットエンコーディングを自動的に適用し、使用する機械学習アルゴリズムにとって最も適切なエンコーディングを適用したカテゴリ特徴量を自動的に抽出します。