
生成AIの可能性を引き出す効果的なプロンプトエンジニアリングの方法
- データ分析
- 生成AI
- AI開発
生成AIは、さまざまな業界で大きな変革を起こし始めています。このブログシリーズは、企業におけるデータ活用の新しい地平を開く、生成AIの可能性について解説します。その第四弾となる本ブログでは、生成AIの仕組みを解説し、生成AIを効果的に使う上で最も重要な技術である、プロンプトエンジアリングについて解説します。
生成AIは機械学習の技術を元に作られています。機械学習は、コーパスと呼ばれる入力と期待する出力のデータのペアを元に、入力と出力の関係をモデルとして学習し、入力のみが与えられた場合に、出力を返す、という技術です。この観点では、生成AIも機械学習の技術の1つと捉えられます。
しかし、従来のAIと、生成AIの大きな違いは、規模と汎用性にあります。従来のAIは、特定のタスク、例えば、機械翻訳、文書要約、画像認識といったタスクに特化されてきました。このため、タスクに特化したコーパスが用意され、学習したモデルはそのタスクでしか使用できません。これは、入力と出力の関係は非常に複雑で、その関係をモデル化するには各タスクに特化したアルゴリズムが必要であり、一つのモデルが複数のタスクをこなすことは難しいと考えられていたためです。
しかし、深層学習技術の発展と計算機の進化により、生成AIが登場しました。生成AIは、桁違いに大きいコーパスで、桁違いに大きいパラメタを持つニューラルネットワークを学習させたAIモデルです。例えば、OpenAIのGPT 4.0では、5000億から数兆のパラメタを持つ、と言われています。これにより汎用的な入力と出力の関係をモデル化できるようになり、タスクを定義するテキスト自体も入力に含めて処理できるようになりました。
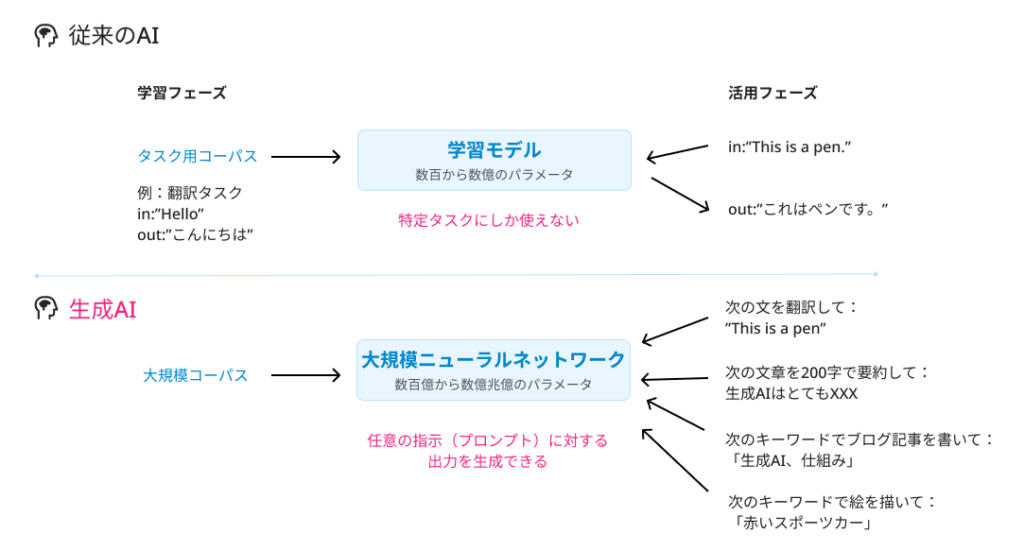
生成AIは、大規模コーパスに含まれる知識が詰まった知識ベースとして考えることができます。これを活用するために重要になるのが、生成AIに与える「指示」です。 この「指示」は、プロンプトと呼ばれており、生成AIをうまく使うための重要なコンセプトになっています。
プロンプトエンジニアリングとは、生成AIを効果的に活用するために、言語モデルへの命令(プロンプト)を最適に設計する技術で、学問分野としても認知されるようになってきています。例えば、ChatGPTへ効果的な命令(プロンプト)をすると質の良い対話ができるように、プロンプトは生成AIがどのような情報を出力するかを決定する重要な要素であり、正確で適切なプロンプトを設計することが重要であるとともに、few shot promptingのように具体的な例示をすることで、生成AIから狙った回答を引き出すことができます。
プロンプトエンジニアリングについては様々な情報が公開されていますが、ここではOpenAPIが公式に提供しているプロンプトエンジニアリングのガイドで述べられている6つのポイントを紹介します。この文書は多様なユースケースを考え長い内容になっているため、本ブログでは、企業内のデータ分析のユースケースにおいて、具体例を交えてエッセンスを絞り紹介することで、データ分析の文脈で生成AIを効果的に使う方法をお伝えします。
生成AIは人間と同じく指示が不十分だと期待しない結果を返すことがあります。また、データ活用のコンテキストでは、生成AIの出力を別のプログラムで処理したいことが多く、厳密に出力フォーマットを定義することが重要になります。「明確な指示」という言葉自体が曖昧ですので、ここでは自然言語で書かれたアンケートの集計を行う、というユースケースの例を見てみましょう。あなたは千件以上の自由記述アンケートのデータを持っています。これを目で読むのは大変なので、それを生成AIに集計させることにしました。

このプロンプトでは以下の点がポイントになっています。
生成AIには、ハルシネーションと呼ばれる問題があります。生成AI、事実とは異なるそれらしい回答を出すことがあります。嘘の無い結果を得るには、根拠を示すよう指示することが有効です。
先ほどと同じアンケートの集約の例では「各回答に「待ち時間に対する不満」が含まれるか否かを判定し、含まれるか否かをYesかNoで回答してください。さらに、その不満を言及している箇所も出力してください。」と指示することが有効です。
複雑なタスクを曖昧なまま与えると生成AIが誤った理解に基づき出力を出すため、期待と異なる結果を返す可能性が増えます。生成AIに実行させたいタスクがサブタスクに分割できる場合、ステップバイステップで指示を与えることが好ましいです。例えば、顧客との会議の書き起こしデータを要約させるユースケースを考えます。


一般に、端的な指示を与えることは良いことですが、生成AIに端的な質問のみを与えると単純なつまらない回答を示す傾向があります。生成AIにより深い洞察を期待する際には、生成AIにどのような観点での洞察を求めるかを指示したり、出力の数を増やして指定することで、深く、幅広く考えさせることが重要です。深い洞察を期待するタスクの例として、データ分析で得られた情報の解釈を生成AIに手伝ってもらう、というユースケースを考えます。


生成AIは汎用的なツールですが、他のツールを用いた方が効果的なシーンがたくさんあります。例えば、現状の生成AIに表構造のデータそのものを入力として与え、データ分析を行わせることは効果的ではありません。一つ上の解約分析の例では、「40代の女性の顧客は、一般の顧客に比べ、入会後3ヶ月に解約する確率が1.5倍以上である」という分析結果だけを生成AIに与えています。データ内から統計的なパターンを見つけ出す作業は、それに特化した別のツールで実施した方が、正確性やスケーラビリティなど、さまざまな観点でメリットがあります。このように、プログラムや他のツールで実施可能なところは他のツールで解消し、生成AIに与えるべきタスクをよく考えることが重要になります。
プロンプトのチューニングにおいては、プロンプトの修正を行った後その結果をきちんと評価し改善していくことが重要です。この際のポイントとなるのは、期待する結果の正解を用意しそれと比較して評価すること、そして、比較による評価指標を定義し、その指標に基づき各プロンプトの良さを定量的に評価することです。
例えば、一つ目の例で示した、自然言語で書かれたアンケートの集計を自動化するプロンプトの設計を考えてみましょう。
このタスクでは、各回答に「待ち時間に対する不満」が含まれるかどうかを判断するものでした。この場合、最初に少数のデータを人間が読み、正解の例を作ること、そして、このデータをテストデータとしてあるプロンプトで生成AIが出力した結果と比較し、何%の精度が出るかを確認することをお勧めします。
要約のような結果の正解判定が難しいようなケースでは、評価用のプロンプトで生成AIを使って評価することをお勧めします。例えば、会議書き起こしの要約タスクの例では、人間が作った要約と生成AIが作成した要約と比較するプロンプトを作り、その結果を元に生成AIで評価することが推奨されています。

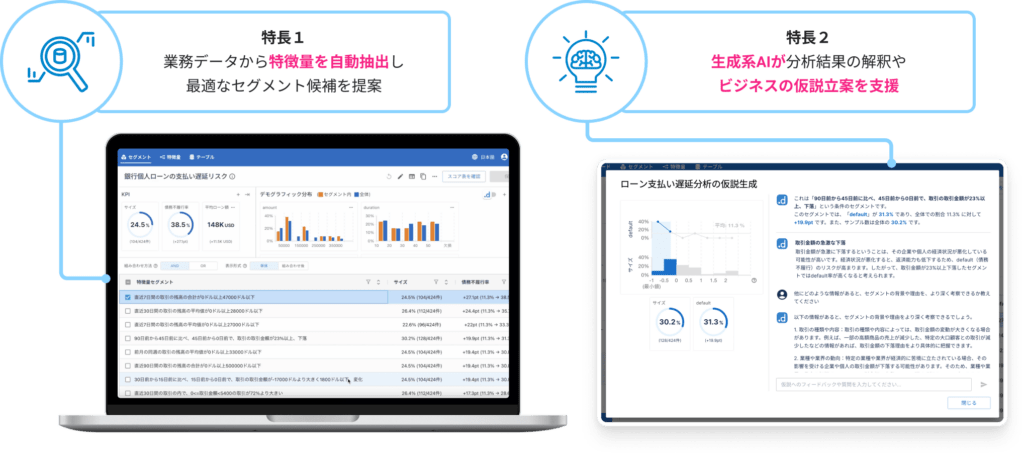
dotDataでは、「データからの知識」である特徴量と、生成AIを融合したdotData Insightによって企業のビジネスアナリティクスを推進しています。生成AIは、企業内のデータ活用において、データの加工・解釈を助ける重要なツールになりうる存在ですが、生成AIだけで全てが解決できるわけではありません。dotData Insightは、dotDataの独自のAIが、従来の手作業による分析では発見することができなかった、或いは、数週間から数ヶ月もの時間がかかっていた、複雑な業務データの重要なパターン(特徴量)を抽出し、そのパターンの解釈を生成AI、LLM(大規模言語モデル)が支援することで、データからの仮説立案や施策設計を支援します。
生成AIブログ – パート1 :生成AIとは? – 生成AIは企業のデータ活用をどのように進化するのか?
生成AIブログ – パート2 :LLMとは? – 大規模言語モデルのデータアナリティクス応用
生成AIブログ – パート3 :生成AIとLangChain
生成AIブログ – パート4 :生成AIの可能性を引き出す効果的なプロンプトエンジニアリングの方法 (このブログ)
併せて読みたい :生成AIによる業務効率化の方法9選を解説!メリットや導入方法も紹介
併せて読みたい :生成AI開発企業おすすめ32選!選び方と各社特徴、費用を解説


