
データ活用とデータガバナンスに貢献するデータパイプライン
- MLOps
- データ加工
- 自動化
「導入したAIの予測精度をさらに引き上げたい」「AIの判定をより安定させて、現場のビジネスに深く定着させたい」――。AIモデルを開発・提供する当社にも、ビジネスを前進させるためのこうした前向きなご相談が頻繁に寄せられます。AIのみならず、データを活用したプロジェクトを成功に導き、期待以上の投資対効果(ROI)を生み出す最大の鍵。それは、AIに入力される「データ」の品質です。私たちAIベンダーは、日々モデルのアルゴリズムを磨き上げ、最高精度のエンジンを開発しています。
しかし、その最先端のAIモデルがお客様のビジネスの現場で真価を120%発揮するためには、「高品質なデータ」という極上の燃料が欠かせません。実運用において、AIがビジネスに貢献できるパフォーマンスの8割は、この「入力データの品質」で決まると言っても過言ではないのです。
逆に言えば、どれほど優秀なAIエンジンであっても、不純物(ノイズや形式の不備)が混ざったデータを与えられれば、正しい答えを導き出すことは困難です(ITの世界ではこれを「GIGO:ゴミを入れればゴミが出る」と呼びます)。だからこそ、私たちは、モデルの提供だけでなく、AIのポテンシャルを最大化するための「データパイプライン」の重要性にも強く着目しています。本記事では、データパイプラインの役割と、データ活用の成功に直結する「データガバナンス」との関係について解説します。
データ活用の歴史は、そのまま「ビジネスの意思決定がどのように進化してきたか」の歴史でもあります。かつては単なる「過去の記録」に過ぎなかったデータが、現代ではビジネスの未来を予測する「AIの原動力」へと変貌を遂げました。この進化の歩みを振り返ることで、なぜ今「データパイプライン」や「データガバナンス」がこれほどまでに重要視されているのかが見えてきます。
データの活用は、業務のIT化(デジタル化)から始まりました。紙の台帳で行っていた経理や顧客管理がデータベースへと置き換わり、データを「正確に記録・保存する」ことが主目的でした。この時代のデータ活用は、月末の売上集計や在庫確認といった定型レポートの作成が中心であり、主に「過去の事実を確認するため」のものでした。データは特定の部署(情報システム部など)が管理し、現場のビジネス部門が直接触れる機会は限られていました。
インターネットやスマートフォンの爆発的な普及により、データの量・種類・発生頻度が劇的に増加しました。「ビッグデータ」時代の幕開けです。この頃から、企業はデータを単なる記録ではなく「ビジネスのヒントを見つける宝の山」と捉え始めます。データウェアハウス(DWH)やBI(ビジネスインテリジェンス)ツールが普及し、膨大なデータから「なぜ売上が上がったのか」「どの顧客層が離反しやすいのか」といった高度な「分析」が行われるようになりました。しかし、この段階ではまだ、データから得た示唆をもとに「人間が意思決定を行う」ことが主流でした。
クラウドコンピューティングの進化とAI(機械学習)の実用化により、データ活用は「過去の分析」から「未来の予測・業務の自動化」へと大きなパラダイムシフトを起こします。「明日の需要はどれくらいか」「最適な価格はいくらか」をAIが瞬時に判定し、ビジネスの現場に直接組み込まれるようになりました。
ここで企業が直面したのが「手作業によるデータ加工の限界」です。大量のデータをリアルタイムかつ高頻度でAIのエンジンに供給するためには、人間の手によるスプレッドシートの集計では到底追いつきません。そこで、散在するデータを自動で収集・加工し、AIへと絶え間なく届ける「データパイプライン」が不可欠なインフラとして脚光を浴びるようになったのです。
冒頭に述べた通り、データ活用において、データの品質は極めて重要です。
データに基づいた判断を行う場面において、不正確なデータは、誤った意思決定につながりかねません。AI開発においても、信頼できないデータ(ガバナンス不在のデータ)を学習させることは大きなリスクです。
データの品質を左右する要素には、以下のようなものがあります。
データの品質を高めるために最も重要なのは、「手作業による」「都度の(アドホックな)データ加工」から脱却することです。現場でよく見られるのが、担当者が毎朝スプレッドシートを開き、手作業で不要な列を削除したり、日付の表記を直したりしてからシステムにアップロードする、という光景です。
しかし、こうした属人的な作業は、入力ミスや担当者不在時の作業停滞や更新遅れを引き起こし、いわゆる「シャドーIT(管理部門が把握していない非公式なシステム運用)」の温床になります。
このようなオペレーションをなくすために、データパイプラインを構築して一連の処理を自動で行います。つまり、データパイプラインとは、社内のあちこちに散らばっている既存のデータを、新たな活用目的(日次レポートの作成、MAツールへの連携、AIによる予測など)に合わせて自動的に収集・加工・統合し、BIツールや他のシステムへ送り届ける工場のようなシステムのことなのです。(食材の調達 → 下ごしらえ・調理 → 配達までを行う、食品加工工場に似ています)
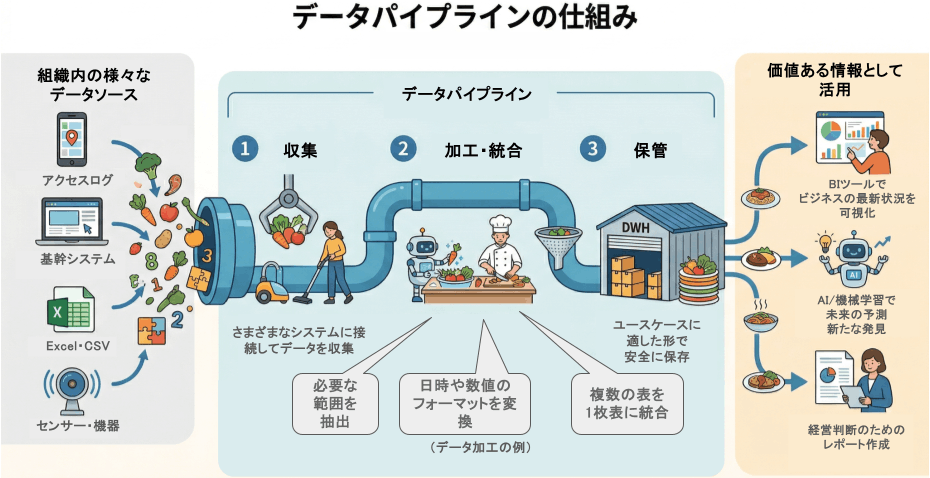
多くの企業では、業務の中心となるシステム(基幹システム)を導入しています。
また、専用のシステム・SaaSを導入しているケースや、Excel・スプレッドシートにデータを入力して管理している部署も多いことでしょう。
このような、さまざま領域に様々な形式で保管されているデータを組み合わせることで、新しい発見やユースケースを得られる場合があります。
データパイプラインには、予め決められた保管場所にデータを取りに行く機能が含まれます。
収集されたデータは、その利用目的に応じて適切な形に加工する必要があります。
例えば、
といった処理を行います。
また、表形式のデータの場合、複数の表を1枚の表に統合する処理を行うこともあります。データの加工・統合内容は、処理結果の使い途(ユースケース)を踏まえて決定する必要があります。(同じ食材でも、どんな料理に仕上げるかによって調理方法が異なりますよね)
加工・統合されたデータは、誰かが何らかの目的をもって使います。
データをどこに出力・保存すべきかは、ユースケースによってさまざまです。
例えば、
といったパターンがあります。
データパイプラインで加工されたデータは、ユースケースごとにあらかじめ決められた場所にデータを配達します。
このような機能を持つデータパイプラインを構築し、一連の処理をシステム化・標準化することで、「誰がいつ扱っても、必ず同じ品質のデータが出力される状態」を担保できます。
特に、一貫性・正確性・適時性が求められるAI運用においては、手作業の排除は絶対条件なのです。
各部署に存在する個々のデータに対して、データの管理者が入力や更新・アクセス権限等に関するルールを策定・運用し、品質を担保する取り組みを「データマネジメント」と呼びます。また、一般的に「データガバナンス」とは、各部署で行われているデータマネジメントの取り組みが適切に実施されているかを会社全体で監督・評価する仕組みを指します。「データガバナンス」と聞くと、セキュリティ部門が定めた「守りのルール」や「面倒な制約」というイメージがまず思い浮かぶかもしれません。しかし、データガバナンスとはAIの投資対効果(ROI)を最大化し、誤った意思決定のリスクからビジネスを守る「攻めの品質保証」なのです。
とはいえ、企業内の各部署で、自分たちが持つデータを各々のルールで運用し、かつそのルールが全社的に機能していることを人の手によってモニタリングするには、膨大な工数がかかります。また、データの定義とデータマネジメントに関する技術的な知識の両方を有する人員を、各組織に配置する必要があります。
マネジメント対象のデータが増えるほど、マネジメントの仕組みを構築し、自動化することが大きなメリットを生みます。データパイプラインは、この仕組みの組み込み先としても有力な選択肢です。
データパイプラインに組み込むデータガバナンスの機能として、以下の3つが挙げられます。
収集したデータが、「予め決められたルールに則った状態であるかをチェックする」機能です。
例えば以下のような内容を機械的にチェックします。
加工前・加工後のデータに対して、必要最小限のアクセス権限を適用します。
また、個人情報や機密データが含まれる場合、パイプラインの途中で匿名化・マスキング処理を行い、セキュアな状態にします。
といった情報を、樹形図のように追跡可能にする仕組みです。
万が一、データの集計結果やAIの予測結果に異常が見られたときに、すぐに原因のデータを特定して修正することができます。このような機能を組み込むことで、データパイプラインは、単なるデータの移動手段ではなく、データガバナンス(品質・セキュリティ・ポリシー)を自動的・強制的に適用する「関所」として機能します。
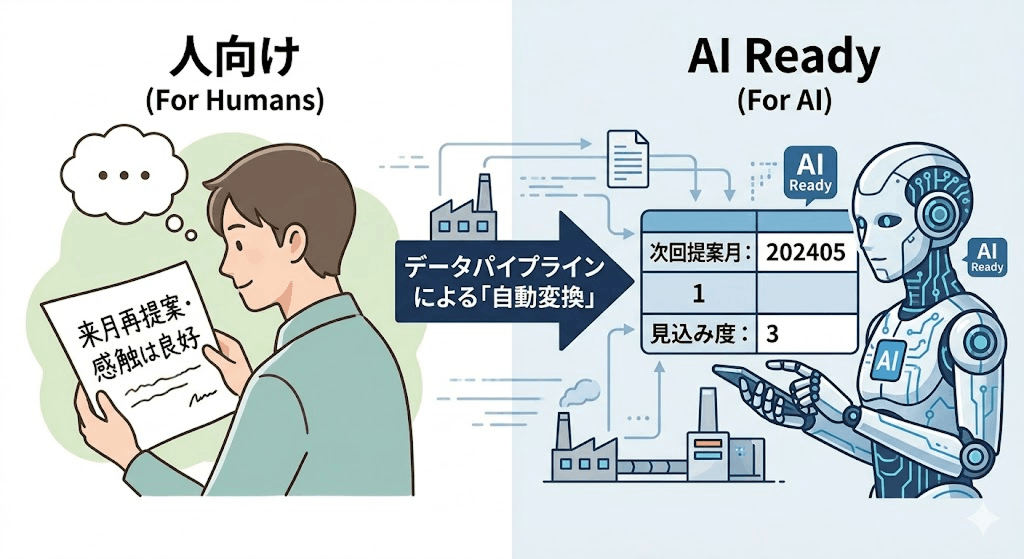
データパイプラインは、AIの学習や予測に使用するデータに対しても非常に重要な役割を果たします。ここで理解しておきたいのは、「人が見てわかりやすいデータ」と「AIが扱いやすいデータ」は全く異なるということです。例えば、営業担当者が顧客リストの備考欄に「来月再提案・感触は良好」とメモを残したとします。人はこれを読んで状況を理解できますが、AIモデルはこのような自由記述のテキストをそのままでは上手く計算できません。
AIが扱いやすいのは、「次回提案月:202405」「見込み度:A(数値なら3)」のように、ルールに従ってフラグ化・構造化されたデータです。
世の中のデータの多くは「人が見てわかりやすいデータ」のまま保存されています。
これをパイプラインを通じてAIが扱いやすい形に自動変換しておくことで、AIの処理結果が格段に安定します。また、AIに不要な計算をさせないことで、クラウドの処理コストを大幅に抑制することにもつながります。このような、AIが安全かつ高精度に扱える状態のデータを、「『AI Ready』なデータ」と呼びます。
最後に、パイプラインを通じて質の高いデータを手に入れるために、データを利用する側(ビジネスユーザー)が設計の初期段階でクリアにしておくべきポイントを挙げます。
「誰が(ステークホルダー)」「何の目的で」そのデータを使うのか。「どれくらいの頻度(毎日・毎時・リアルタイム)で」「いつまでに更新されていればよいのか」を定義します。
ユースケースの目的を達成するために、「どんなデータが必要か」「その元データをどの組織が持っているか」をステークホルダーと一緒に明らかにします。また、必要なデータが「全社的なデータポリシーやセキュリティ要件をクリアできるか」も確認しておく必要があります。
必要なデータが「どこに保存されているか」「どれくらいの頻度(毎日・毎時・リアルタイム)」で「いつまでに更新されていればよいのか」を定義します。また、パイプラインが収集した処理対象のデータの形式(表形式の列の並び順、数値や日時のフォーマットなど)についても定義します。
あらかじめ処理対象データの形式を決めておく=データマネジメントのルールを一つ作ることです。パイプラインが処理可能な形式を「ガイドライン」として共有し、現場のデータ作成者・管理者がそれを遵守することで、結果として全社的なデータマネジメントルールの整備・データガバナンスの推進に大きく貢献することになるのです。
データパイプラインは、裏方のITシステムではありません。ビジネスの現場でデータを安全に活用し、成果を出すための最重要インフラです。手作業による加工をなくし、パイプライン上でガバナンスを効かせることで、データは「AI Ready」な資産へと変わります。データやAIの持つポテンシャルを引き出し、データを活用したビジネスの成功につなげるために、ぜひ「ガバナンスが組み込まれたデータパイプライン」の構築に目を向けてみてください。
パイプラインで整備されたデータを、実際のビジネス成果(予測や分析)へと繋げるのがdotDataです。複雑なデータからAIに最適な「特徴量」を自動設計することで、本記事のテーマである「データガバナンス」を保ったまま、データ活用のスピードを飛躍的に高めます。
本記事で解説した「AI Ready」なデータから、ビジネスを動かす核心(特徴量)を自動で見出すのが dotData Insight です。パイプラインで集約された統計的事実に生成AIを掛け合わせることで、数値の羅列を「具体的なアクションプラン」へと即座に変換します。データ基盤の整備を、確実なビジネス成果とROIに結びつける一歩先のデータ活用を体験してみませんか。
データパイプラインの方が、より広範な処理を求められています。
ETL / ELTは以下の要素で構成された一連のデータ処理プロセスを指します。
一方、データパイプラインに含まれるデータ処理は、この限りではありません。
といった処理を含むこともあります。
特にAI予測(3)やテキスト解析(4)の自動化を実現したい場合は、弊社のdotData FeatureFactoryやdotData TexSenseが強力な武器となります。貴社のデータ環境に合わせた最適な実装イメージをご提案しますので、まずはお気軽にご相談ください。
表形式のデータはもちろん、画像や長文テキストなど多岐にわたります。
生成AI登場以前は、表など一定の形式を持つ構造化データが処理の対象でした。しかし、生成AIの登場により、画像・音声・長文テキスト等の非構造化データも扱うことができるようになりました。データの加工を行うソフトウェアだけでなく、データを保存するデータベースも進化を続けており、保存可能なデータ量の拡大はもちろん、非構造化データを格納・加工することができるデータベース製品も登場しています。
形式を問わずにさまざまなデータを抽出し、そのままデータレイクなどに蓄積→生成AIを使用して、データの種類に応じた柔軟な処理を行うパイプラインも登場しており、データパイプラインのアーキテクチャはさらなる広がりを見せています。
代表的なデータパイプラインのユースケースをご紹介します。


