
単発で終わらせない!「データの活用」を業務に定着させる5つの実践ポイント
- データ分析
- 自動化
データ活用を業務に定着させ、継続的なビジネス成果を生むための鍵は、分析プロセスの「パイプライン化による自動化」と「業務オペレーションへの組み込み」にあります。本記事では、過去の単発分析から脱却し、データ分析自動化を通じて分析結果を業務サイクルに組み込み、毎月回る継続的な運用にするための具体的な実践ポイントを解説します。
データ活用が単発で終わってしまう主な理由は、「属人化した手作業のプロセス」と「業務からの乖離」の2点にあります。企業がデータ活用ビジネスを推進する際、外部の専門家に依頼して立派なレポートが作成されたとしても、現場の意思決定に活かされなければ継続的な価値は生み出せません。具体的には以下のような構造的な問題が挙げられます。
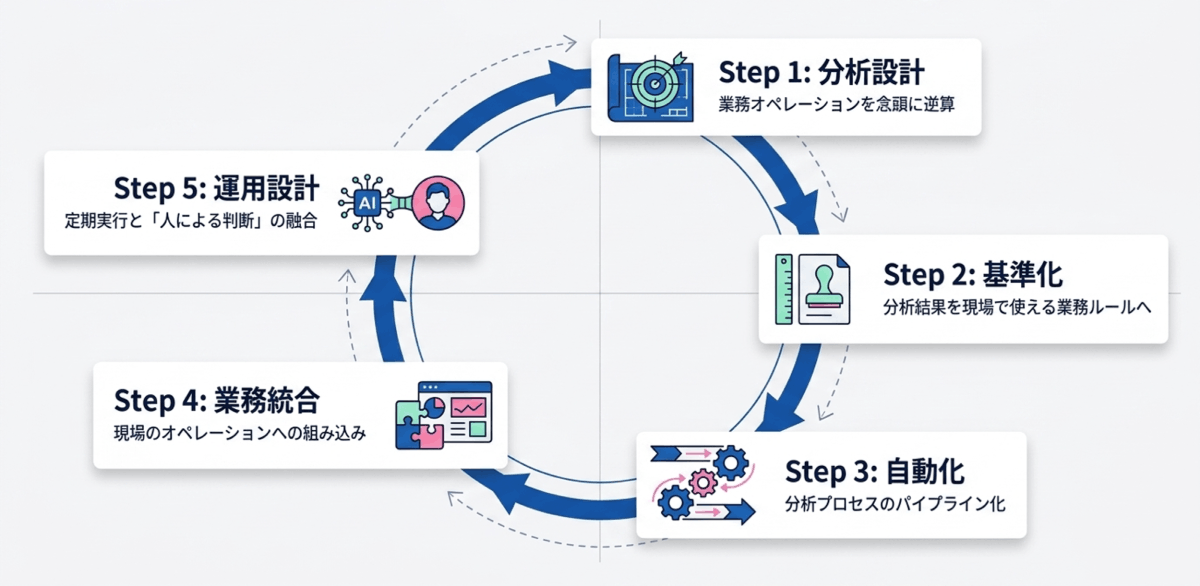
データの活用をビジネスに定着させるには、最初から業務オペレーションでの活用を念頭に置き、分析プロセス全体をパイプライン化して自動化する5つのステップが必要です。
データ利活用を進める上で、まずは「具体的な業務オペレーションで、分析結果をどのように活用するのか」を明確にします。利用するデータの種類を決め、現場で活用できるアウトプット(出力形式やタイミング)を逆算して分析を設計します。
データに基づいて発見された新しい洞察を、一時的な気づきで終わらせてはいけません。それらを日々の業務で実行可能な基準やルールへと変換し、業務プロセスに落とし込みます。
データを収集・加工し、分析してレポートを出力するまでの一連のプロセスを統合し、自動化(パイプライン化)します。手作業による属人化を排除し、人的ミスや運用負荷を最小限に抑えることで、データの活用を安定させます。
作成した自動化パイプラインと新しい基準を、既存の業務フローの中に統合します。現場の担当者がスムーズに実行できるよう、分かりやすいインターフェースや定型レポート(スコアカード形式など)で提供することが有効です。
自動化された分析結果を、豊富なドメイン知識を持つ現場の人間が解釈し、最終判断を下す体制を作ることが成功の鍵です。環境変化によるデータ傾向の変化(データドリフト)を防ぐためにも、定期的にStep 1の分析設計を再実行し、判断基準をアップデートしていく運用設計が求められます。
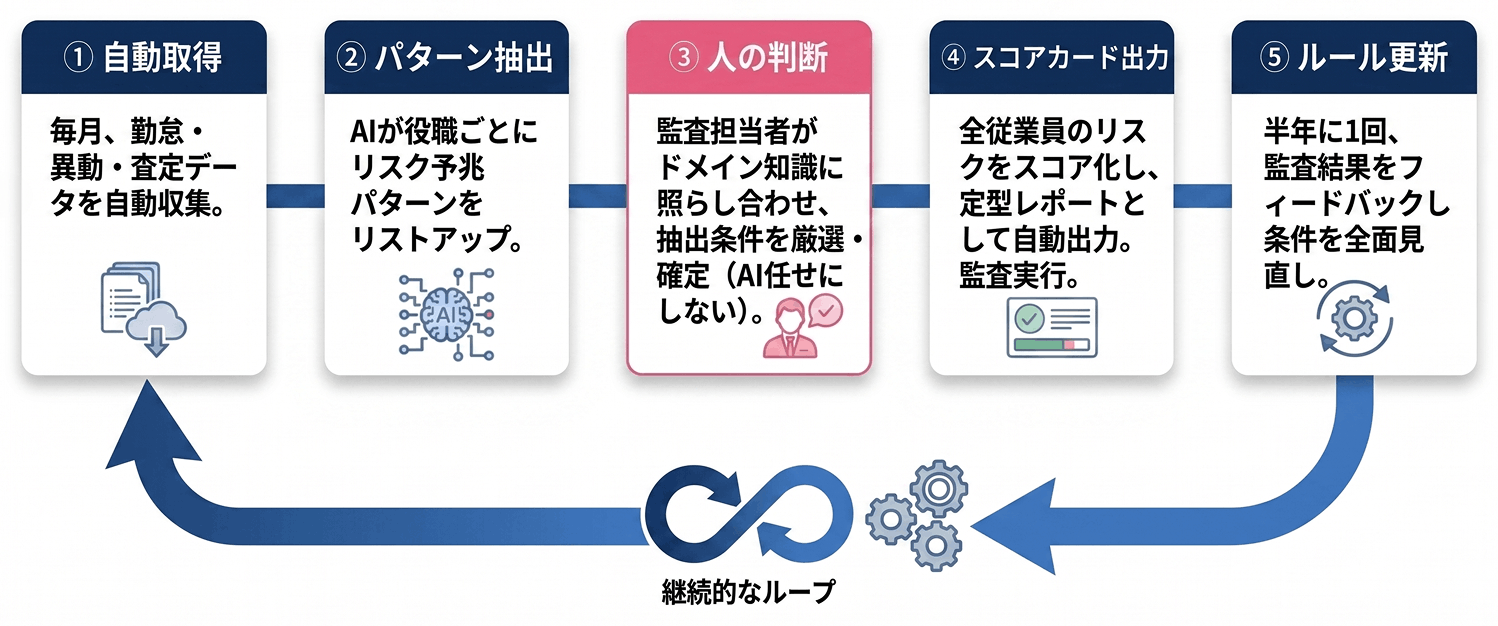
内部監査業務に継続型データ活用を組み込むことで、過去の事例や担当者の経験則に頼っていた監査対象者の選定を、客観的かつ高精度に実施できるようになります。 以下は、従業員のコンプライアンス違反リスクの予兆を検知し、未然に防ぐことを目的とした運用の事例です。
従来は専門人材の知見や勘に頼って対象者を選定していましたが、属人的な見逃しのリスクがあり、網羅性や客観性に課題がありました。そこで、データドリブンなリスク予兆管理の仕組みを導入し、膨大な従業員の中から効率的に監査対象者を特定することを目指しました。
不正の発生パターンは役職や職種(管理職か否か、営業職か技術職かなど)によって異なるため、従業員をセグメント分けして分析を行います。例えば、管理職のコンプライアンス違反リスクには、以下のように全く異なる2つのパターンが存在することがデータから明らかになりました。
このような発見をもとに、「直近の3ヶ月間で残業時間が60時間以上」といった具体的な抽出条件を作成し、毎月の監査対象者の選定基準として活用します。
毎月の監査業務を想定し、分析の単位を「社員×月」に設定した上で、以下のような自動化フローで運用しています。
このように、自動化によるプロセス効率化と、専門人材による高度な判断を組み合わせることで、監査業務の精度を継続的に向上させることが可能になります。
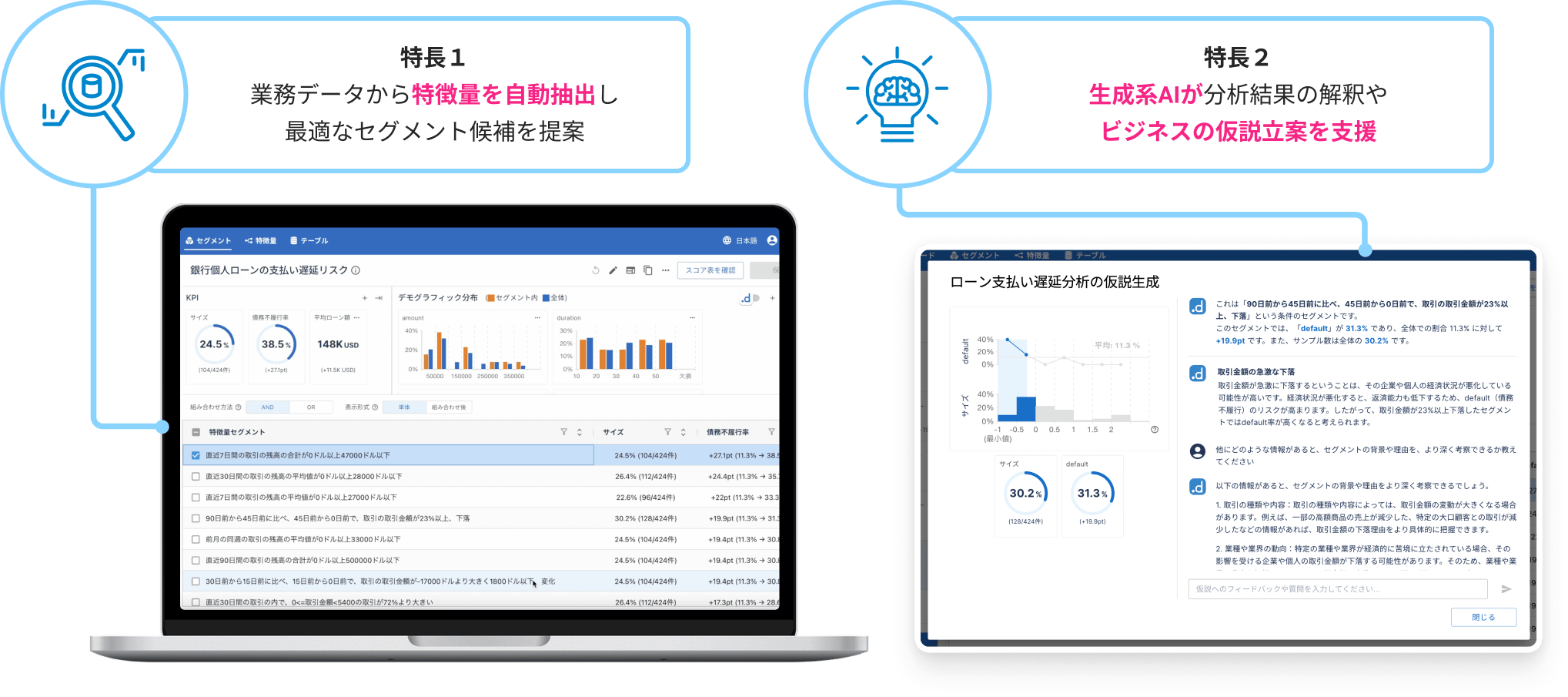
本格的なデータ活用を自社で定着させるには、分析プロセスを構築し実務へ組み込むというハードルが存在します。dotDataでは、製品である「dotData Insight」と、それを支える「3つのサービス」を組み合わせることで、現場主導の継続的な運用を強力にサポートします。
「dotData Insight」は、業務データから「特徴量(データパターン)」を自動抽出し、最適な条件(セグメント)の候補を提案するデータ分析プラットフォームです。主な特長は以下の通りです。
単発の分析で終わらせず、分析プロセス全体を業務オペレーションに組み込んでパイプライン化・自動化するために、dotData Insightの前・中・後(プレ・オン・ポスト)をカバーする3つのサービスを提供しています。
これらの製品とサービスを組み合わせることで、分析部門と業務部門の分断を解消し、データ活用によるビジネス価値の最大化を継続的に図ることが可能になります。
データ活用は、単発の分析プロジェクトで終わらせるべきではありません。業務の効率化や迅速な意思決定を実現するためには、分析プロセス全体を自動化し、日々の業務オペレーションの中に「データに基づいて判断し、アクションプランを策定する」サイクルを定着させることが重要です。本記事で紹介した5つの実践ポイントを参考に、自社のデータ活用を「やりっぱなし」から「継続型」へと進化させ、データ活用によるビジネス価値の最大化を目指しましょう。
業務のサイクルに応じて見直しの頻度を柔軟に設定できます。データ活用のメリットを最大化するためには、ビジネスのスピードに合わせて見直しの頻度を3ヶ月に1回などに上げることも容易です。データ分析自動化パイプラインが構築されていれば、新しいデータや条件の変更に伴う見直し作業自体に大きな手間はかかりません。
一般的に、検証(PoC)から実際の業務への組み込みまで、最短で半年程度の期間を見込みます。まずは現在企業の中に蓄積されたデータを活用して3ヶ月程度の検証を行い、自動化パイプラインのプロトタイプを作成します。その後、1〜2ヶ月をかけて本番環境や実際の業務フローへの組み込みを行っていくアプローチが確実です。
プロジェクトの初期段階から、決裁権を持つ役職者(部長層など)を巻き込むことが最も効果的です。決断が早く現場を直接動かせる人物が最初から関わることで、データを分析して得られた洞察を実務へと適用する判断を即座に下すことができます。しかし、役職者の毎回参加が難しければ、少なくとも現場のキーマンの参加が欠かせません。現場のドメイン知識に基づいた判断体制を作ることが、ビジネスの成果を出し、持続的な運用を実現する鍵となります。
はい、小売業の在庫最適化や製造業の予防保守など、幅広い業務に適用可能です。その他にも、人事部門での離職リスク検知や、金融業の信用リスクモニタリングなどがあげられます。最新のデータからリスクや傾向を定期的に出力し、日々の具体的な業務やアクションプランの策定につなげていくサイクルは、様々なビジネスシーンで横展開が可能です。

