
時系列モデリングを強化する時間特徴量の設計 – パート3(ARIMAモデル、Prophetとの比較)
- 時系列データ
時系列モデルは、時間の経過とともに変化するデータのパターンと振る舞いを分析し予測するための統計的手法です。このブログシリーズの 「時系列・時間データに関する特徴量設計 – パート1」では、ARモデル、ARIMA、LTSM、Prophetなどの標準的な時系列モデルを説明し、その利点と欠点を議論しました。一方、パート2では、標準的な時系列モデルの欠点を解決する手法として、時間的データセットからの特徴量設計を紹介しました。
最終回となるパート3では、ARIMAとProphetモデルを検証し、それらに代わるアプローチとして特徴量設計比較し、特徴量設計の利点を示します。
このブログでは、ProphetのQuick Startから取得したデータセットを使用しました。データは、WikipediaのPeyton Manning(アメリカの元アメリカンフットボール選手)のページの日次ページビューのログに基づく時系列データです。データは8年間(2008年 – 2015年)にわたる周期的な時系列であり、一般的な時系列モデリング技術を示すのに理想的です。以下に、時間経過に伴うデータのクイックビューを示します。

このデータセットにはいくつかの興味深い振る舞いがあります:
2007年12月から2014年12月までの過去のデータに基づいて、2015年1月から2016年1月までの未来の期間を予測しました。データセットをPandas Dataframeとしてロードし、訓練用データセットと検証用データに分割しました。
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
# Prepare the data for ARIMA
train = df[df['ds'] < '2015-01-01'] # 7 years of data for training
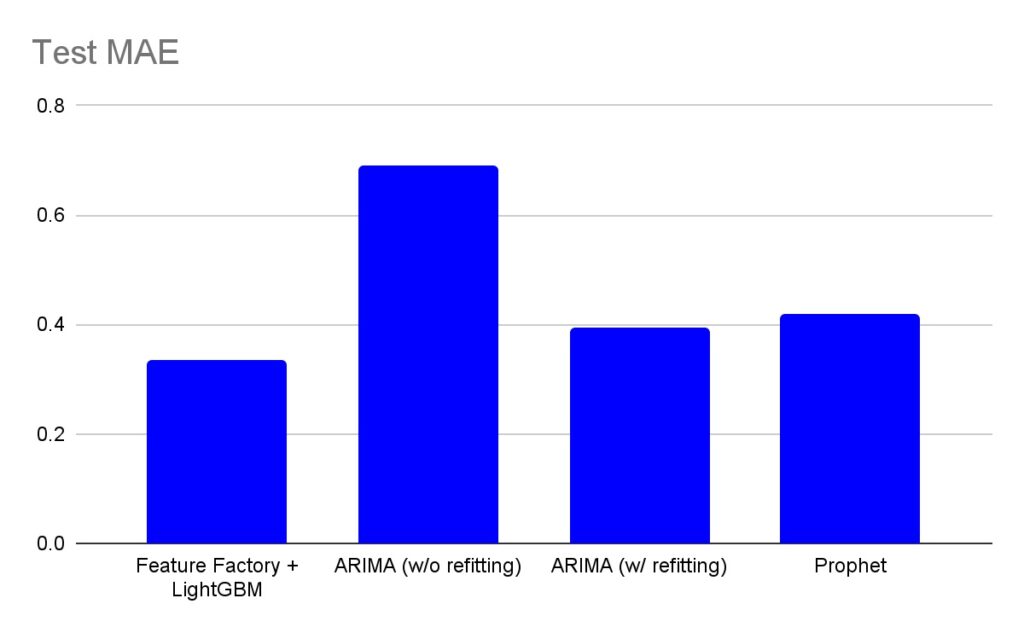
test = df[df['ds'] >= '2015-01-01'] # ~1 year and 1 month of data for test表1は、このブログで比較した4つの方法のMAEスコアをまとめています。
グラフに示されているように、「Feature Factory + LightGBM」はARIMAとProphetに比べて予測誤差(MAE)を15%-20%削減しました。予測誤差の大きな差は、時間的特徴量のアプローチが正確な予測モデルを構築する上でどれほど強力であるかを示しています。
さらに詳しく見ていきましょう。
パート1で議論したように、ARIMAとProphetは非常に一般的な時系列モデルです。
ARIMAは、時系列データを自己回帰(AR)、差分(I)、移動平均(MA)のコンポーネントを組み合わせてモデルが構成されます。
上記のコンポーネントは特徴量と同等であり、ARIMAはそれらを線形回帰モデルとして学習します。
Prophetとは、加法モデルを使用し、時系列をトレンド、季節性、休日の3つの主要なコンポーネントに分解します。モデルは、これらのコンポーネントが線形に組み合わさって観測値を生成すると仮定します。ARIMAに比べて、Prophetは自動的により多くの種類の特徴量をサポートし、これらの特徴量に対して線形および指数モデリングをサポートします。Prophetが自動的に検出する特徴量には以下のものがあります:
ARIMAについては、ARIMAのコンポーネント(ラグ、差分、移動平均)を自動的に検出し、その後ARIMAモデルを構築するARIMAの自動MLバージョンであるauto-ARIMAを使用しました。ARIMAとProphetのコードは以下の通りです。
import pmdarima as pm # to detect ARIMA parameters using auto-arima
from statsmodels.tsa.arima.model import ARIMA # to build the ARIMA model
# Auto-ARIMA to detect ARIMA model parameters
model = pm.auto_arima(train.y,
start_p=1, start_q=1,max_p=10, max_q=10,
m=1, # frequency of series set to annual
d=1, # 'd' determined manually using the adf test
seasonal=True,
start_P=1, start_Q=1, D=0,
trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
# Extracting the ARIMA parameters
model.get_params() #order (7,1,9) is obtained from `get_params()` method
# Build the ARIMA model
model_fit = ARIMA(train.y, order=(7, 1, 9)) # order for AR, I, MA components were obtained from auto-ARIMA
fitted = model_fit.fit()
# Forecast for the test period of 2015 (383 data points)
fc = fitted.forecast(383)
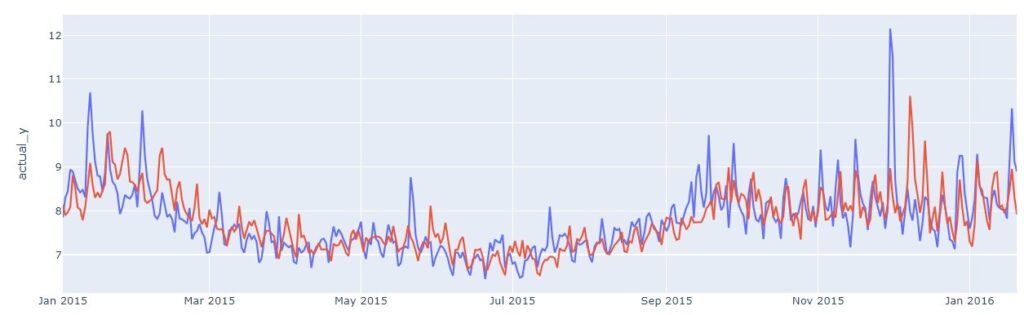
図2は、1年間の未来の期間(2015年1月から2016年1月)について、ARIMAを使用した予測されたページビューと実際のページビューを示しています。予測(赤線)が実績(青線)と非常に異なって見えることがわかります。この差異は、ARIMAモデルの単純な性質によるものです。すなわち、ARIMAは一度に一つの季節性しか捉えることができず、このデータの変動を完全に学習することができませんでした。もう一つ注目すべき点は、数ヶ月後に予測がフラットラインになることです。これは、予測期間中、ARIMAは以前の予測を使用して未来の予測を計算するためです。以前の予測を使用するということは、ARIMAは短期的な予測には良いかもしれませんが、長期的な予測には適さないことがわかります。

一般的な回避策は、ビジネスの精度要件に応じてARIMAモデルを定期的に再学習することです。週次の季節性を観察すると、モデルを週次で再学習することができます。図3は、週次で再学習したARIMAの予測を示しており、大幅な改善が見られます。このアプローチの重要な欠点の一つは、頻繁にモデルを再構築するというオーバーヘッド(この例では、週次)です。
# Date formatting to allow for weekly refit
date_format_tables = [df, train, test]
for table in date_format_tables:
table['ds'] = pd.to_datetime(table['ds'])
# Ensuring that we train on a weekly basis by identifying the test time point that is 7 days ahead of train
test['ds_pet'] = test['ds'] - pd.Timedelta(days=7)
#initializing a dataframe to collect the predictions
df_preds = pd.DataFrame(columns = ['ds', 'actual_y', 'test_pred'])
# Rebuilding the model on a weekly basis
for pet, start_date, i in zip(test['ds_pet'], test['ds'], range(len(test))):
train_rolling = df[df['ds'] < pet]
test_rolling = df[df['ds'] == start_date]
model_refit = ARIMA(train_rolling.y, order=(7, 1, 9))
fitted = model_refit.fit()
fc_test = pd.DataFrame({'yhat' : fitted.forecast(1)})
df_preds = df_preds.append({'ds' : start_date,
'actual_y' : test_rolling.iloc[0]['y'],
'test_pred' : fc_test.iloc[0]['yhat']},
ignore_index = True)
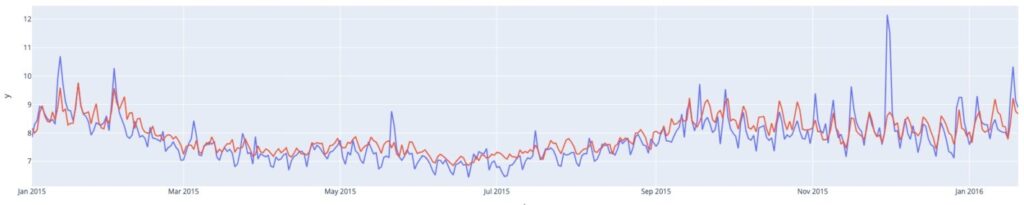
次に、ARIMAの再学習なしと同じ設定に基づいてProphetを適用しました。Prophetはこのデータセットの複数の季節パターンを捉えることができるため、週次の再学習なしでもProphetは比較的良好に機能しました。これは図4で示されています。一方、Prophetの予測は一貫して過大予測されています。また、Prophetは毎週が同じパターンを持つと仮定し、予測期間の長短にかかわらずそのパターンを無理やり当てはめるため、長期予測での適合は悪くなる傾向があります。
from prophet import Prophet # to build the Prophet model
# Set date column to the right format
train['ds'] = pd.to_datetime(train['ds'])
test['ds'] = pd.to_datetime(test['ds'])
# Build Prophet model
m = Prophet()
m.fit(train)
# Forecast for the test period of 2015 (383 data points)
forecast_for_train = m.predict(train)
forecast_for_test = m.predict(test)

パート2で議論したように、時系列モデルの代替手法は特徴量設計です。まず、特徴量設計は時系列データを特徴量の一枚表に変換します。次に、何らかの機械学習アルゴリズムを特徴量テーブルに適用し、予測モデルを学習します。
従来の特徴量設計は、データサイエンティストの経験と手作業に大きく依存していますが、dotDataはデータ基点で特徴量を発見する特徴量自動設計を提供しています。これは、時間データセットからさまざまな時系列特徴量を抽出するように設計されています。この日次ビューの予測問題に対してdotDataの特徴量自動設計を適用し、これらの特徴量に対してLightGBMモデルを使用します。
特徴量自動設計は、利用可能なデータに基づいてさまざまな時間範囲で特徴量を自動的に発見します。これにより、長期的および短期的な予測を容易に考慮することができます。このデータセットに対して特徴量自動設計が自動的に発見した特徴量のサンプルを以下に示します。
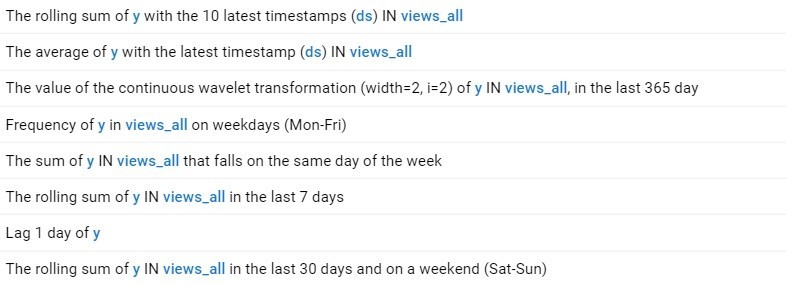
さまざまな時間範囲と特徴量集約関数が自動的に検出され、モデルで使用するための多くの特徴量が作成されています。
これらの時間的特徴量に基づいて、図6に示すように、代替手法(dotData Feature Factory + LightGBM)は最も正確な予測を生成しました(精度比較については、このブログの最初の部分の表1を参照してください)。dotDataはさまざまな時点での変動を手作業で検証することなく、季節性と非季節性のパターンを検出し、時系列のピークを自動的に捉ました。これをProphetモデルと比較すると、Prophetで観察された過学習問題が解消され、MAEの改善に寄与していることがわかります。
ARIMAモデルとProphetは、ワンストップで時系列予測を行う初心者にとっては便利な方法ですが、実践には様々な問題と困難が伴います。その根本的な課題は、探索される時系列特徴量の種類と、これらの方法で採用されるモデリング技術がモデルに組み込まれており、ユーザーによるカスタマイズができないことにあります。カスタマイズが不十分であれば、ユーザーが複雑な関係性のある時系列データをモデリングし、最先端の機械学習アルゴリズムを利用する能力が大幅に制限されます。
特徴量設計と最先端の機械学習アルゴリズムの組み合わせは、従来の時系列モデルが提起する多くの課題を克服することができます。 データ基点の特徴量発見プロセスを利用して特徴量を発見し、それらに対して機械学習を適用することで、ユーザーがより強力な時系列予測モデルを開発し、ドメイン知識を組み込むことが可能になります。
dotDataの特徴量エンジニアリングは、複雑な関係性をもつデータセットから時系列特徴量を捉えるのに優れています。特徴量エンジニアリングの自動化を使えば、予測に有効な時系列特徴量を自動的に開発し、ドメイン知識を組み込んでカスタマイズし、それらを高度な機械学習モデルに適用することができます。これにより、ロバストな予測が可能になります。
dotDataが企業における時系列予測にどのように活用できるのか興味がある方は、ぜひお気軽にお問い合わせください。


