
生成AIセキュリティの最前線:LLM活用で考える「攻め」と「守り」のバランス
- 生成AI
生成AI(LLM)の急速な進化と普及は、私たちの働き方やサービス提供のあり方を大きく変えつつあります。日々の業務でLLMを活用することで生産性を向上させたり、LLMを組み込んだ革新的なサービスを提供したりするなど、「攻め」の姿勢でAIを活用する動きが加速しています。しかし、その利便性の裏側には、従来のシステムとは異なる新たなセキュリティリスクが潜んでおり、これらのリスクに適切に対応するための「守り」の戦略が不可欠となっています。
本ブログでは、LLMアプリケーションのセキュリティの難しさ、OWASP Top 10に見る具体的な脅威、そしてエンタープライズ向けに製品を提供するdotDataがどのようにこれらの課題に取り組んでいるのかをご紹介し、組織における生成AI活用の「攻め」と「守り」のバランスについて考察します。
LLMのセキュリティを考える上で、まず理解すべきは従来のシステムとの構造的な違いです。従来のシステムは、入力、処理、出力という一連の流れの中で、処理部分(プログラムロジック)が固定されています。そのため、同じ入力値を与えれば必ず同じ出力値が得られるという前提でシステム設計やセキュリティ対策が行われてきました。システムに特定のインプットを与えて異なる結果が出力されれば、それは「バグ」と捉えられてきました。
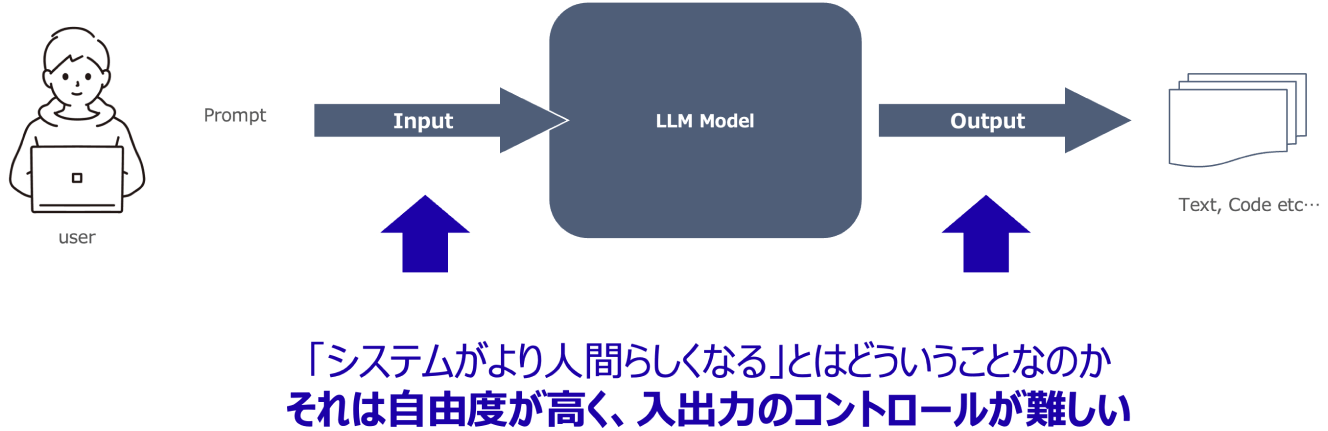
一方、LLMはより人間らしい振る舞いをします。人間が同じ質問をされても、気分や状況、あるいは時間の経過による成長によって回答が変わる可能性があるのと同様に、LLMアプリケーションでは同じ入力を与えても出力が一概に一定になるとは限りません。これにより、特に入出力のコントロールが難しくなるという点が、生成AIにおけるセキュリティ対策の難しいポイントとなります。この入出力の制御の難しさが、従来のシステムにはなかった、あるいはより複雑になった脅威を生み出しています。
ただし、LLMアプリケーションのセキュリティ対策の基本的な部分は、従来のシステムと大きく変わるわけではありません。入力の制御、出力の制御、サプライチェーンリスクへの対応などは引き続き重要です。
これらの基本的な対策に加え、前述の「入出力のコントロールの難しさ」に起因する新たな脅威への対策が必要となります。
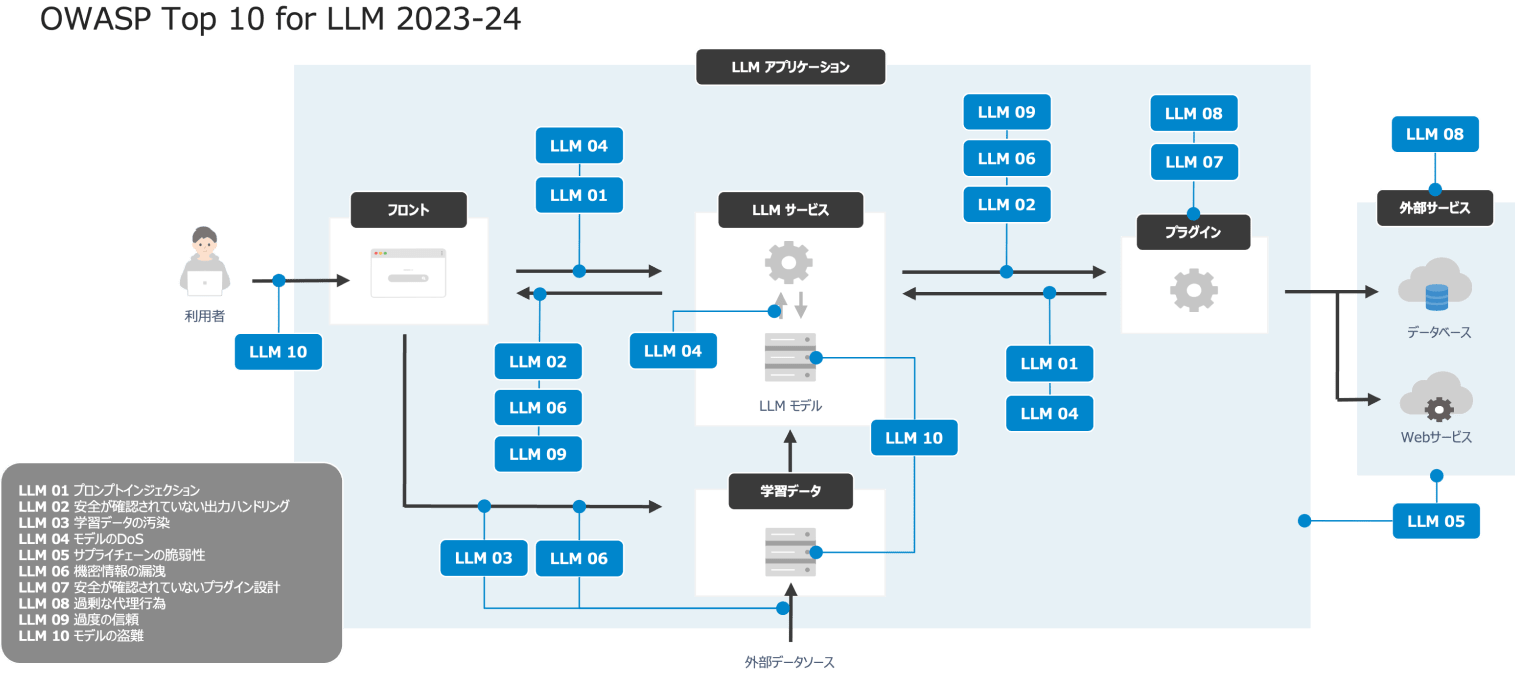
LLMセキュリティのリスクと対策を体系的に理解する上で、OWASP Top 10 for LLM Applicationsは非常に有効な「教科書」となります。これは、LLMアプリケーションにおける上位10個の脅威とその対策がまとめられたものです。
私たちが昨年のウェビナーで参照したものは2023年版でしたが、2025年版へのアップデートが2024年11月17日に行われています。名称も「OWASP Top 10 for LLM Applications 2025」に変更されました。約8割の項目は大きく変わっていませんが、新たに2つの脅威がランクインし、一部の脅威の名称や解釈も変更されています。
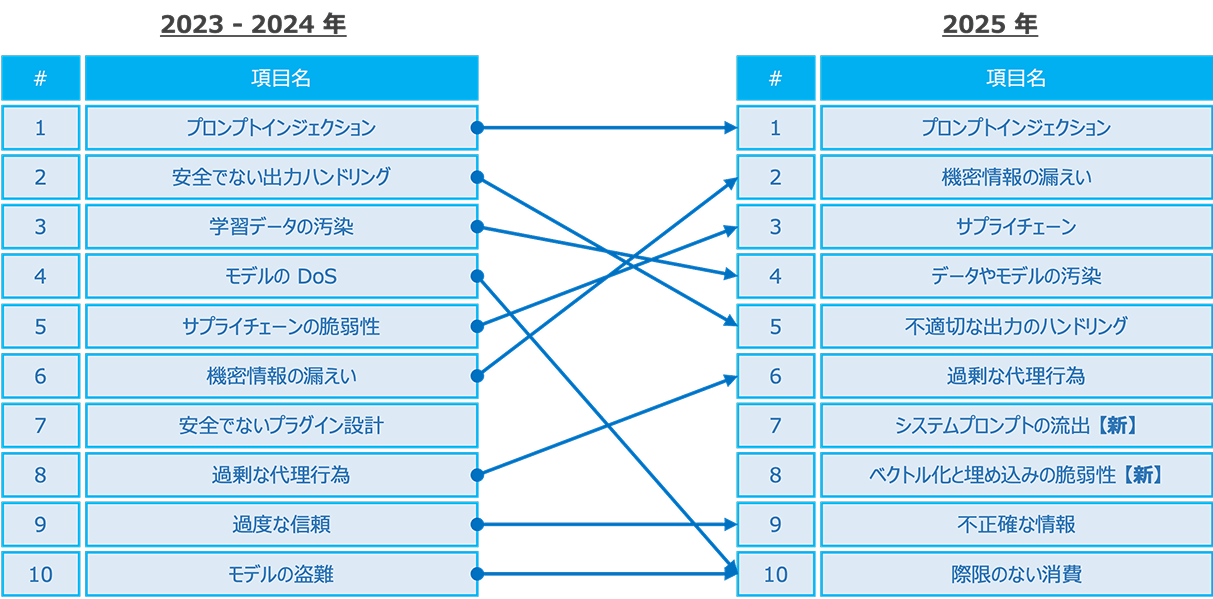
2025年版で新登場した脅威は以下の2つです。
ユーザーがLLMに直接入力する「ユーザープロンプト」とは異なり、「システムプロンプト」はシステムがLLMに「このように振る舞ってほしい」というルールや指示を定義するために内部的に使用するものです。ここに認証情報や機密情報が書き込まれている場合、そのシステムプロンプトが流出すると情報漏洩のリスクが発生します。したがって、システムプロンプトを定義する際には、機密情報を記述しないように注意する必要があります。
これは特にRAG(Retrieval-Augmented Generation)と呼ばれる、外部データソースを参照してLLMの回答を補強する仕組みに関連する脆弱性です。外部データソースに対してデータポイズニング(データの汚染)を行ったり、外部ソースを経由することで本来LLMから引き出すべきではない情報を引き出すようなプロンプトを組んだりする脅威が含まれます。
また、既存の脅威についても、名称や解釈の変更が見られます。
前回第2位だった「安全でない出力ハンドリング」は、今回第5位「不適切な出力ハンドリング」に、前回第3位だった「学習データの汚染」は、今回第4位「データやモデルの汚染」、前回第4位だった「モデルの可用性侵害攻撃」は、今回第10位「再限のない消費」に変更されています。これは、従来の可用性侵害(DoS)の観点だけでなく、モデルに対するDoS攻撃によってAPI利用料が高騰し、コスト増につながるという側面も含む表現となっています。
これらの変更は、この1年半ほどの間にLLMアプリケーションの実装が進む中で、より具体的で解像度の高い脅威が認識されるようになった結果と言えます。今後は、この2025年版のOWASP Top 10を参考に、LLMセキュリティのリスクと対策を検討していくのが良いでしょう。

過去1年間には、主要なLLMモデルの進化(GPTシリーズ、Gemini、Claude、DeepSeekなど)が見られました。マルチモーダル対応(言語だけでなく画像や動画の処理)、推論能力の強化、用途に応じた軽量化や高速化、そしてコスト削減といった進展がありました。
このような進化の裏側で、セキュリティに関するインシデントも発生しています。やはり最も多く見られる脅威はプロンプトインジェクションによる脆弱性を突いたものです。Slack AIやMicrosoft 365 Copilotといった有名なサービスでも、情報漏洩につながるプロンプトインジェクションが検出されています。また、今年話題になったDeepSeekに関しては、登場して間もなく米国ユーザーのデータが中国に漏洩したというニュースがあり、DeepSeek=危険という印象付けがされたこともありました。
法規制の面でも動きが見られます。欧州ではAI法の成立・施行など、厳しく規制する方向に進んでいます。米国では、前政権の規制強化の流れを現政権が撤廃するなど、比較的緩やかな方向に向かっています。日本では、今年の2月に罰則のない法令が閣議決定されています。このように、各国で規制の方向性が異なっており、経済成長を期待する流れと、リスクに対応する流れが入り混じっているのが現状と言えます。
データを取り扱う製品をエンタープライズのお客様に多く提供しているdotDataとしては、お客様に安心して製品を利用していただくことが非常に重要です。そのため、技術面、組織面の両面から包括的なセキュリティ対策を行っています。SOC 2 Type 2認証取得などもその一環です。アカウント管理、端末管理、従業員へのセキュリティ研修なども基本的な対策として実施しています。
生成AI機能の開発においても、これらのセキュリティ対策は適用されます。dotDataでは、お客様が生成AIを積極的に活用したい場合も、非常に保守的に利用したい場合もあることを考慮しています。また、組織によっては生成AIの利用自体に制限があったり、利用して良いデータが決まっていたりする場合もあります。どれだけ利用部門が生成AI機能の導入を望んでも、組織全体のガバナンスやセキュリティポリシーに合致しない製品は導入できません。
このような背景から、dotDataでは生成AI機能のセキュリティ要件を策定し、製品の新バージョンをリリースする際に、これらの要件を満たしているかどうかの評価(アセスメント)を必ず行っています。
具体的な取り組みの例として、以下のようなものがあります。
生成AI機能は非常に便利ですが、dotData製品の機能は生成AIに完全に依存しているわけではありません。生成AIがなくても dotData の特徴量自動設計などの主要機能は利用できます。これにより、生成AIの利用に慎重なお客様でも製品をご利用いただけるようにしています。
お客様が製品のリスクアセスメントを適切に行えるよう、どのようなデータがLLMに送られるのかを明確に開示しています。特に、ユーザーが自由にテキストを入力できる機能(例:AIとの対話機能)では、どのようなデータでも入力されうるため、お客様が最も懸念しやすい部分です。マニュアルなどで、機能ごとにどのようなデータがLLMに通信されるかを具体的に記載しています。
OWASP Top 10 for LLM Applicationsなどのガイドラインを参照し、ユーザーとLLMアプリケーション、LLM(モデル)、そしてアプリケーションが扱うデータの間で発生しうるリスクに対して、どのような対策が講じられているかを具体的に評価しています。入力されるデータ、LLMに送られるデータ、出力される結果がアプリケーション内でどのように利用されるかなどを細かくチェックし、予期せぬ挙動が起きないかなどを検討しています。これらのアセスメント結果は、開発段階だけでなく、リリース前の承認プロセスで利用されています。
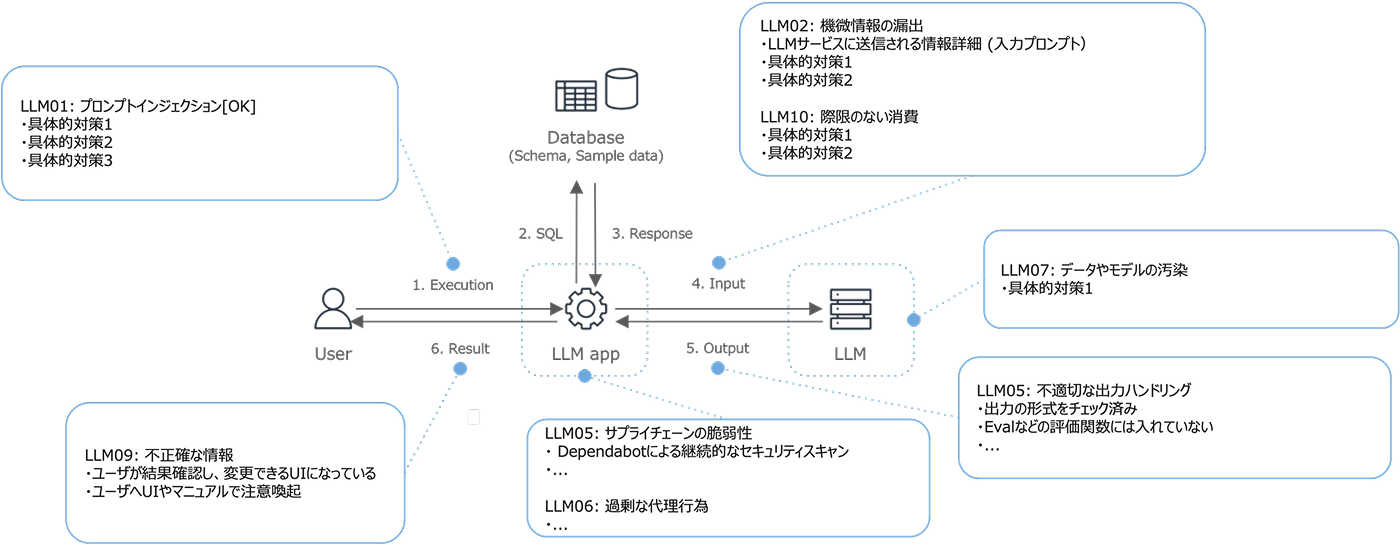
特に金融機関や政府機関など、データの活用に厳しい規制が存在するお客様の場合、データの国外転送やインターネット経由の通信が許可されないケースが多くあります。
例えば、OpenAIのような米国のサーバーでホスティングされているLLMモデルを直接利用する場合、お客様が入力したデータが米国に送信されてしまう可能性があります。これは日本の規制では問題となる場合があります。dotDataのSaaS版が日本国内でホストされていても、LLMへのリクエストが海外サーバーに向かえば同じ問題が発生します。この解決策の一つとして、AWS Bedrockのようなサービスを活用した閉域接続をサポートしています。
これにより、dotData製品(AWS東京リージョンでホスト)からAWS Bedrock(同じく東京リージョン)内のLLMモデル(Claudeなど)を利用する際に、通信がAWSのVPC内で完結し、データが国外に送信されることを回避できます。Bedrockを介することで、LLMモデル自体もAmazonのインフラ上でプライベートな通信で利用可能になります。
お客様のオンプレミス環境で生成AIを利用したいというニーズにも対応するため、dotData製品(dotData Feature Factoryなど)では、VLLMのようなオープンソースソフトウェアと、LlamaやDeepSeekのようなオープンモデルを組み合わせて、オンプレミス環境内で推論を完結させる仕組みを提供しています。
この取り組みにより、外部のLLMサービスに接続できない環境でも生成AIを利用可能にしています。ただし、この場合でも、利用するモデルが汚染されていないかなど、OWASP Top 10の観点から考慮すべき点は存在します。

これらの対策や、安全な利用のための情報(製品マニュアルやデプロイメントガイドなどでの補足)を提供することで、お客様が安心してdotData製品の生成AI機能を利用できるよう配慮しています。
組織内で生成AIツールを積極的に活用し、生産性向上を目指す上で、多くの企業が直面している課題があります。それは、新しいツールやモデルが日々登場し、進化していくスピードに対して、それらを評価・導入するためのセキュリティチェック体制が追いつかないという問題です。特に大規模な組織ほど、既存のソフトウェア導入フローに則ってセキュリティチェックを行う必要があり、これが数週間から数ヶ月かかる場合があります。このチェックがボトルネックとなり、新しい便利なツールを迅速に導入できない状況が生まれます。
もしチェック体制が弱ければ、リスクを十分に評価せずにツールを導入してしまい、情報漏洩などのインシデントにつながる可能性があります。逆に、全てを厳格にチェックしようとすると、ツールの導入が滞り、イノベーションの機会を失ってしまうことになります。これは、まさに「攻め」と「守り」のバランスをどのように取るかという課題です。
この課題に対し、dotDataを含む多くの企業が取り組んでいるのは、ツールの利用・導入フローを整理し、リスクに応じた段階的なアプローチを取ることです。

例えば、トライアル段階では機密性の低いデータのみを扱う、仮導入段階では一定のアセスメントを通過したデータのみを扱う、本格導入段階では完全に安全性が確認された上で、より機密性の高いデータも扱い得る、といったように、利用するデータの種類やリスクレベルに応じてツールの利用範囲や許可レベルを段階的に設けます。
開発におけるコード生成の例で言えば、誰が書いても似たようなコードになる「ボイラープレート的なコード」と、企業のコア資産となるような機密性の高いコードを分けて考え、生成AIへの入力可否を判断するといった方法が考えられます。
本番環境や本番データと、開発環境を明確に分離し、本番データが生成AIに安易に入力されないように制御します。
このような段階的かつ柔軟なアプローチを取ることで、完全に安全性が確認されるまで待つことなく、リスクをコントロールしながら新しいツールを試したり、限定的に導入したりすることが可能になります。これにより、セキュリティを維持しつつ、イノベーションの機会を最大限に活かすことを目指します。
生成AIの活用は、生産性向上や新たなサービス創出といった「攻め」の機会をもたらします。しかし、その進化の速さや新しい脅威の出現は、常にセキュリティ上の「守り」を意識することを私たちに要求します。
Model Context Protocol (MCP) のような、LLMが外部リソース(プラグインやエディタなど)と連携する仕組みが登場する中で、これらの信頼性をどう評価するかが新たな課題となっています。これは従来のオープンソースライブラリの利用と似た側面もありますが、LLM自体の不確実性(例:「嘘をつく」可能性)が加わることで、評価はさらに複雑になります。生成AIが安全かどうかを生成AIに聞くといった状況に陥る可能性も指摘されています。
結局のところ、セキュリティリスクを完全にゼロにすることは不可能です。どこかでリスクを受け入れ、最低限のチェックを行った上で利用を判断する必要があります。クラウド移行期に設定ミスによる情報漏洩が増加したのと同様に、LLMにおいても、脆弱性を突いた攻撃や意図しない設定ミスによる情報漏洩が増加する可能性があります。
したがって、私たちは常に新しい脅威や対策に関する情報をキャッチアップし、変化に適応していく必要があります。組織における生成AI活用の成功は、この「攻め」と「守り」のバランスをいかに賢く取り、リスクと向き合っていくかにかかっていると言えるでしょう。


