
Databricks AI + Data Summit 2025レポート – AIエージェントからLakehouseまで、未来のデータ活用とは
- データ分析
- 生成AI
- DX


2025年6月15日〜18日、カリフォルニア州サンフランシスコにて開催された「Databricks AI + Data Summit 2025」は、データとAIの最前線を体感できる世界最大級のカンファレンスとなりました。全世界から22,000名以上が集結し、日本からも280名以上の参加者が現地に足を運びました。本記事では、このサミットの模様を詳しくレポートするとともに、データレイクやAIエンジニアリング、セルフ分析の高度化といった最新トピックを紹介します。
その前にまず、今回のサミットを主催した「Databricks」という企業について、簡単に触れておきましょう。
Databricksとは、クラウド型データプラットフォームを提供するアメリカの企業であり、2013年にカリフォルニア大学バークレー校の研究者たちによって設立されました。彼らは、大量データを高速処理するためのオープンソースフレームワーク「Apache Spark」の開発者たちであり、まさにビッグデータ処理の第一人者です。
設立当初はSparkの技術支援やコンサルティングを中心に活動していましたが、2015年ごろから方向性を大きく変え、クラウド型データプラットフォームの開発と提供に注力するようになりました。現在のDatabricksは、機械学習の基盤、生成AIの実行環境、データウェアハウスとデータレイクの統合といった領域でリーダーシップを発揮しており、企業におけるAI導入やデータ活用の中核を担っています。
売上規模においても急成長を遂げており、ARR(年間経常収益)は2020年時点で約1,000億円だったものが、5倍以上に到達する見込みとも言われています。2024年12月時点の評価額は約10兆円ともされ、日本企業で例えるならKDDIやリクルートに匹敵するほどの規模です。
Databricksの技術戦略における特筆すべき点は、オープン性と統合性です。Apache Sparkに加え、Delta LakeやLakehouseアーキテクチャ、Unity Catalogといったクラウドに最適化されたデータプラットフォームを提供し、しかもそれらの多くをオープンソースとして公開しています。これは、「データの民主化」というグローバルな潮流を体現するアプローチであり、今後のAI社会に不可欠な基盤技術といえるでしょう。
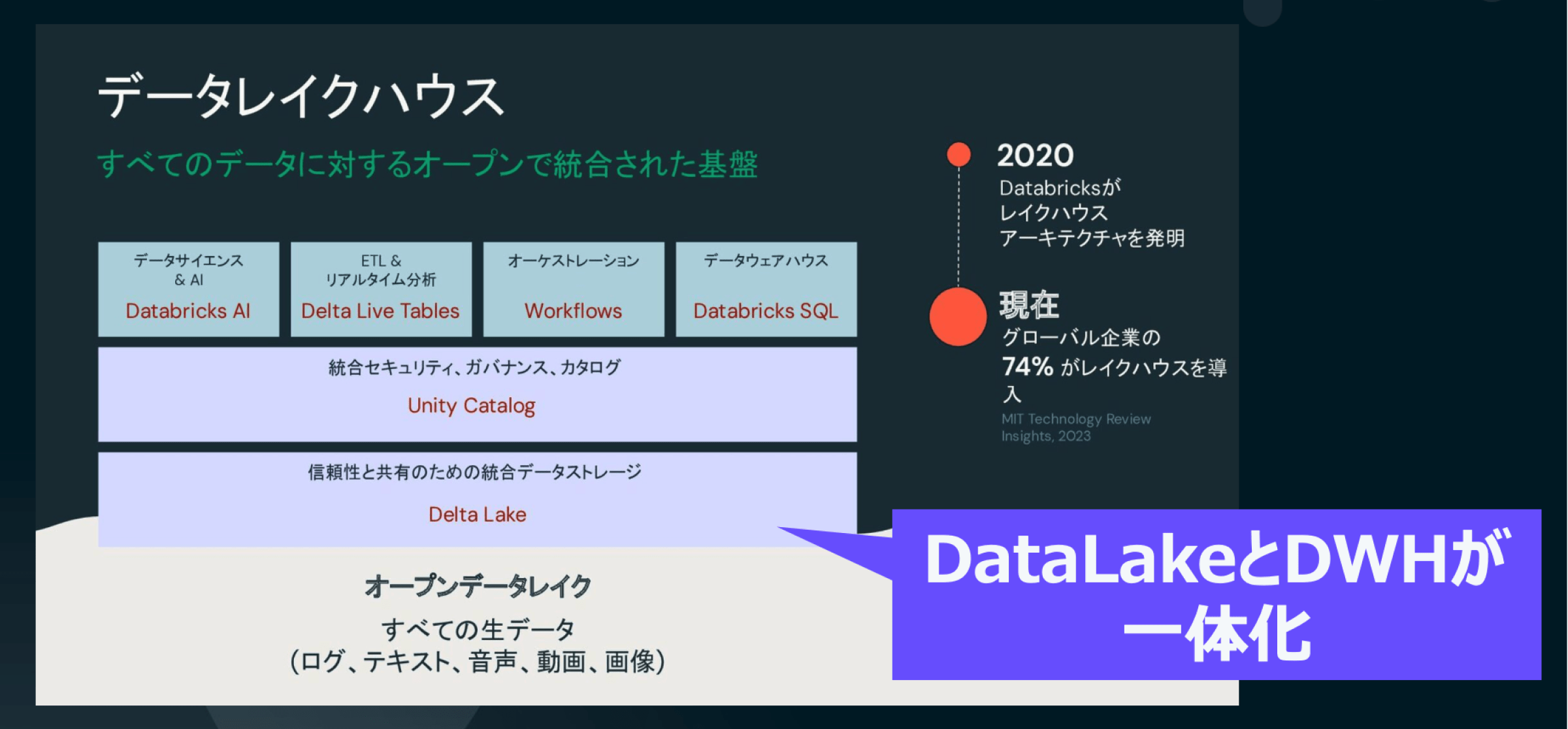
Databricksを語るうえで欠かせないのが、「Lakehouse(レイクハウス)」というアーキテクチャです。これは、従来別々に管理されていたデータウェアハウスとデータレイクを一元的に統合するモデルであり、構造化データと非構造化データを1つのプラットフォームで処理・分析できる点が最大の特徴です。
従来、企業ではこれらのデータを別々に扱う必要があり、層ごとの処理や分担が求められていました。こうした分断は、全社的な分析やAI活用の柔軟性を妨げる要因となっていました。
Lakehouseはこの課題を解消し、一貫性と柔軟性を両立する統合型のデータ基盤として設計されています。中核となるのは、オープンフォーマットのDelta Lakeであり、大規模データの信頼性ある処理とスケーラブルな運用をクラウド上で実現します。
実際、Databricksによると世界中のグローバル企業の74%がこのLakehouseを導入しており、Azure Databricksなどクラウドとの連携も強化されています。Databricksは、Microsoft AzureやAWS、Google Cloudといった主要クラウドプロバイダーとのパートナーシップも深めており、柔軟でスケーラブルなクラウドストレージ環境の中でデータ処理とAIの実行を効率化する統合プラットフォームを提供しています。
ここからは、本記事の中心テーマである「AI & Data Summit 2025」についてご紹介します。
このイベントは、Databricksが毎年主催するグローバルカンファレンスであり、2025年は過去最大規模での開催となりました。6月15日から18日までの4日間、世界中のデータサイエンティスト、エンジニア、ビジネスリーダーがサンフランシスコに集結し、最新のAI技術やデータ戦略について活発な議論が行われました。
日本からも過去最多となる280名以上が現地に参加しており、日本語向けの振り返りセッションや懇親会も実施されるなど、日本市場への注力がうかがえました。
このような背景のもと、サミットのキーノートやセッションで繰り返し語られていたキーワードのひとつが、「データプロダクト」という考え方です。これは、次章で詳しく解説します。
データプロダクトとは、単なるデータの集まりではなく、特定の利用者(市場)に対し、価値をもたらすよう”パッケージ化・品質保証”されたデータ資産を意味します。
従来、企業におけるデータ管理は部門ごとに分散し、それぞれが独自にクレンジングやETL(データ変換)、品質管理を行っていました。このような構造は、サイロ化の原因になり、データの再利用性が低く、全社的なデータ活用や意思決定のスピードが制約されてしまいます。
データプロダクトの考え方では、利用部門は「データのユーザー」であり、データ自体はあらかじめ利用方法や品質基準、メタデータ、モニタリング機能が付属された「再利用可能なコンポーネント」として提供されます。これにより、エンタープライズ全体でのデータの民主化とスケーラブルな活用が実現できるようになります。このようなデータプロダクトを実現するために必要不可欠なのが、統合されたデータ分析基盤です。
Databricks AI & Data Summit 2025において、データ基盤に関する最も注目すべき発表は、「Lakebase」と「Unity Catalogの拡張」でした。これらの発表は、Databricksの戦略と密接に結びついており、2024年に実施されたNeonおよびTabularの買収が背景にあります。Neonの技術はLakebaseに、Tabularの技術はUnity Catalogの新機能に直接活用されています。いずれも約1500億円(約10億ドル)規模の大型買収であり、今回の発表はあわせて3000億円規模の投資によるものです。
これらは、Databricksが長年掲げてきた「データとAIの統合」というビジョンを、さらに力強く前進させる重要なマイルストーンとなっています。
「Lakebase」とは、運用データベース(OLTP)と分析データベース(OLAP)の境界を取り払うことを目的とした新アーキテクチャです。サーバーレスでPostgreSQL互換、しかもDelta Lakeベースで動作するこのデータベースは、ストレージとコンピュートを分離し、負荷に応じてスケーラブルにリソースを割り当てることができます。
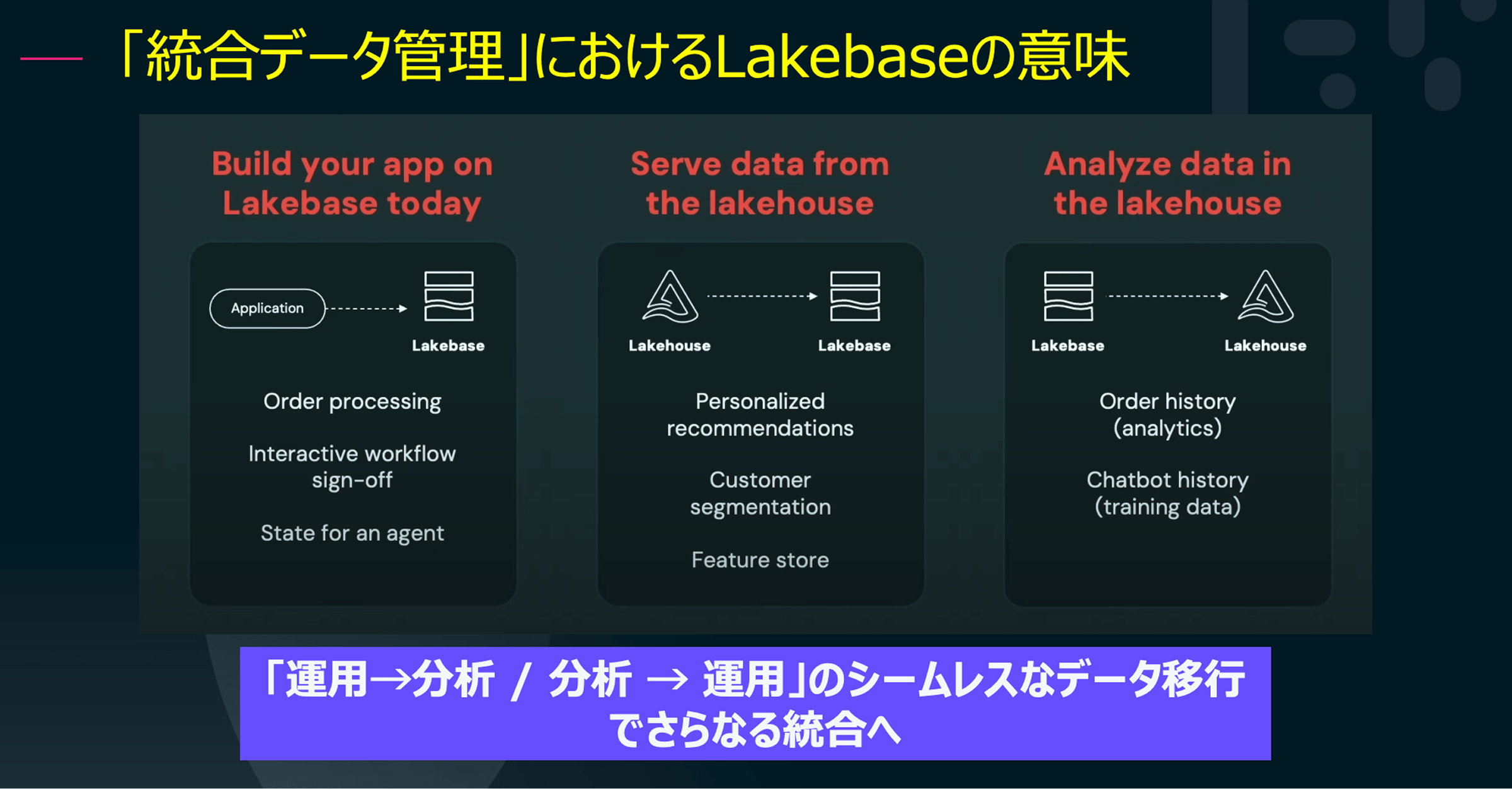
たとえば、アプリケーションから発生したデータを即座に分析基盤へ連携し、リアルタイムで注文履歴を分析して業務に反映するといったシナリオが、ETLやリバースETLといった手間なしで実現されます。これは、運用と分析が融合した“完全統合型データ基盤”と呼ぶにふさわしい進化です。
このLakebaseの導入により、データウェアハウスとデータレイクの融合は次のステージへと突入しました。
Unity Catalogは、Databricks内外のデータやAIモデルを一元的に管理するメタデータカタログとして知られていましたが、今回のアップデートにより、その用途と柔軟性が格段に広がりました。主な新機能は次の2つです:
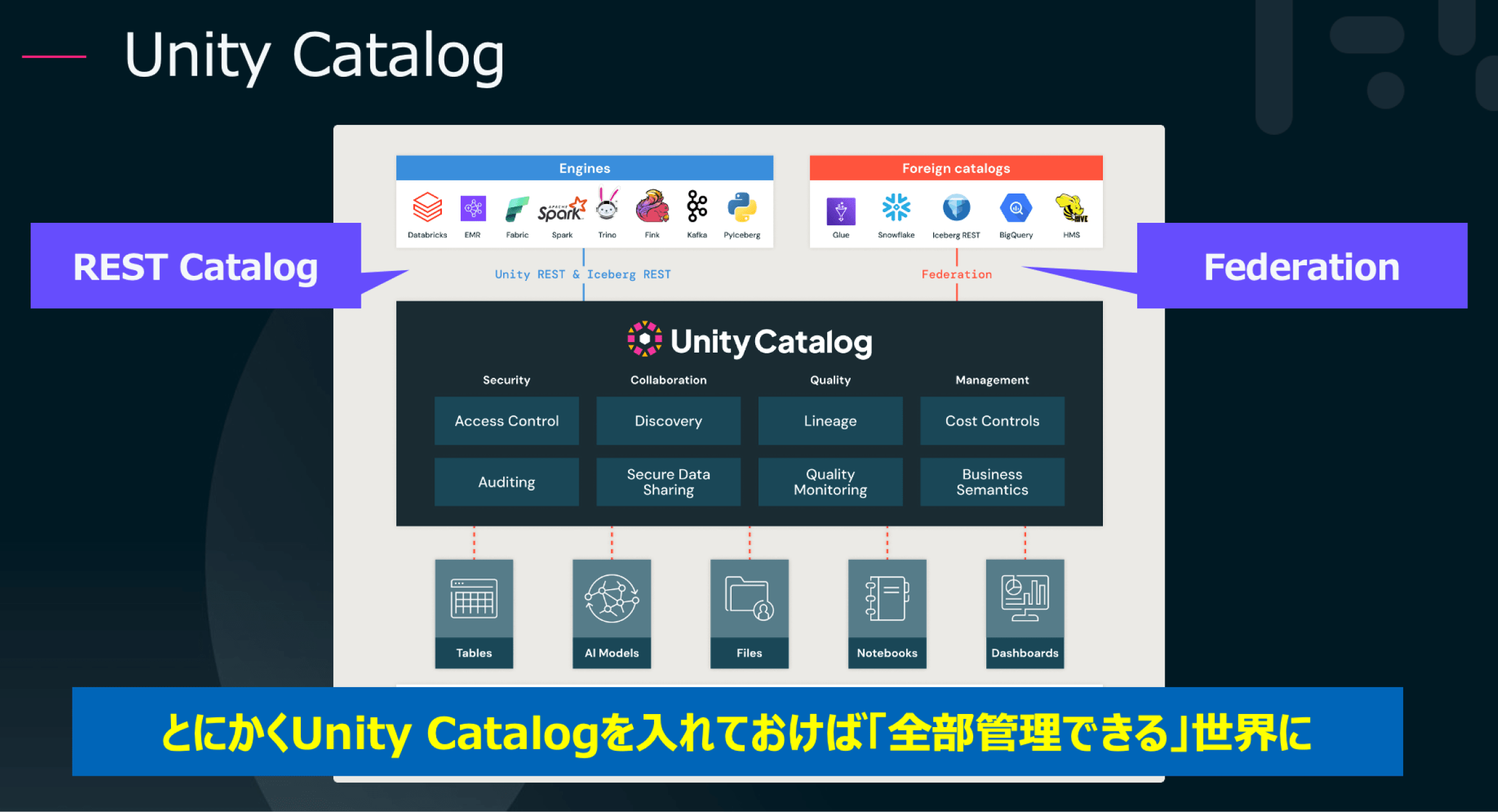
Iceberg形式で保存されたデータを、Amazon EMR、Trino、Snowflakeなど他の分析エンジンからも参照可能にするAPIが追加されました。これにより、Databricks以外のシステムからも、統一されたメタデータでデータ活用が可能になります。
外部のIcebergテーブルをUnity Catalogに直接統合し、仮想的に統合されたデータ基盤を構築できます。これにより、クラウドアカウントやストレージにまたがるデータ統合もシームレスに実現されます。
部門ごとにKPIの定義が異なり、Power BIやTableauで計算結果が食い違う、こうした課題を解決するのが、Unity Catalog MetricsとUnity Catalog Discoveryです。
ビジネス指標をレイクハウス層で定義し一元管理することで、どのツールを使っても一貫した結果が得られます。さらに、メトリクス定義やダッシュボード管理、承認プロセスの統合機能も強化され、データの整合性と信頼性を高めています。

このように、LakebaseとUnity Catalogを組み合わせることで、より統合されたデータ管理が実現し、企業のデータプロダクト活用を支援します。

2025年のサミットで最も注目されたトピックのひとつが、「AIエンジニアリング」です。これは、ソフトウェアエンジニアリングの原則をAI開発・運用に適用し、安定性・保守性・品質を担保する技術体系を意味します。
2024年は、複数のAIエージェントが連携してタスクをこなす「複合AIシステム(Compound AI Systems)」が注目を集めましたが、2025年はそれをどうプロダクション品質で構築・運用するかが大きなテーマとなっています。
イベントでは、このAIエンジニアリングを支えるためのツールをいくつも発表しました。以下はその代表例です:
これらのツールを活用することで、AIの開発・評価・改善の全工程が自動化・効率化され、AIの活用を一段階上の次元へと引き上げています。
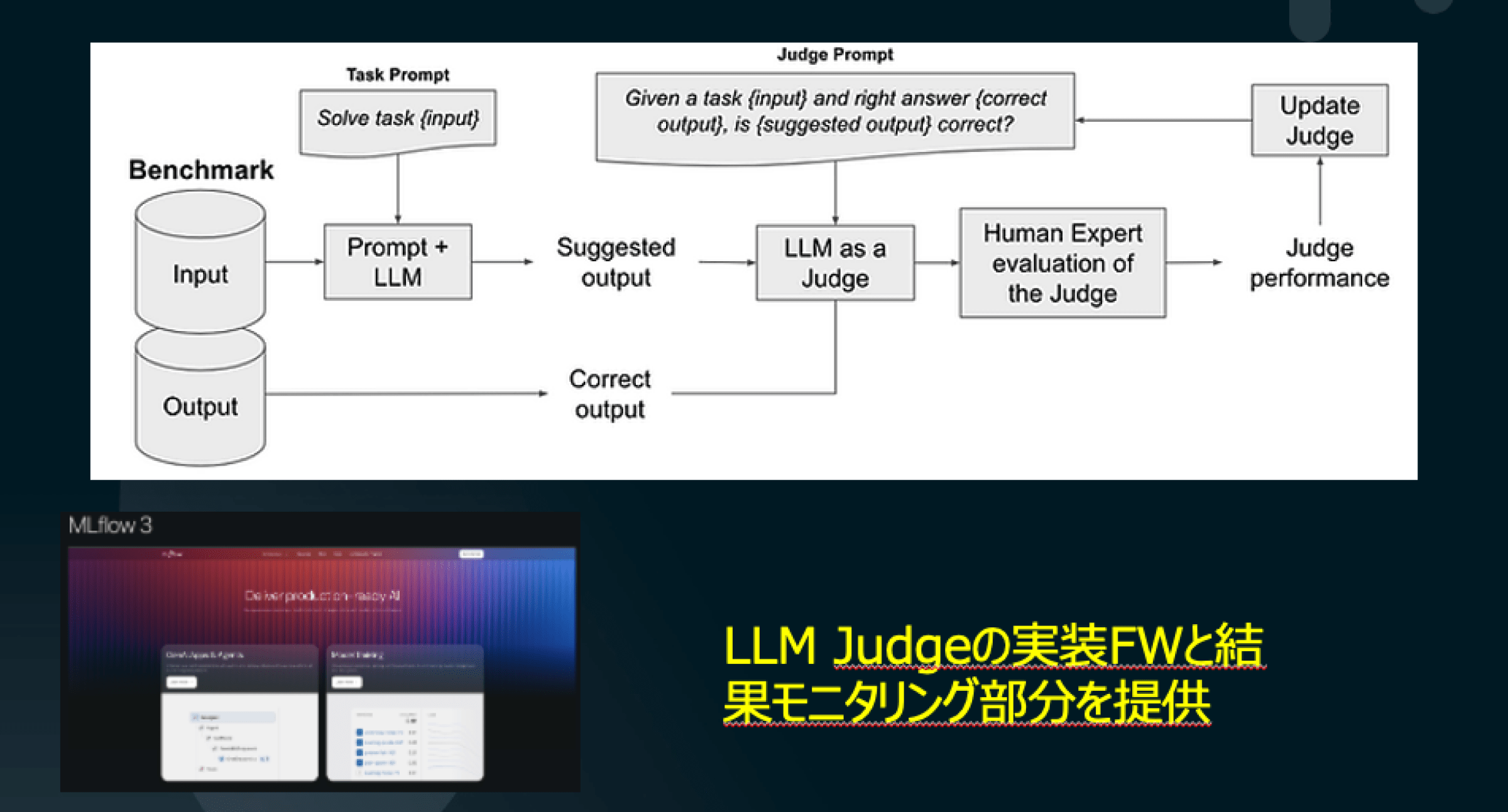
上の図は生成AIの品質をどのように担保していくかという点を端的に表現した図です。MLflow 3.0の中核となるのが「LLM Judge」の概念です。これは、AI出力の品質を別のAIが評価する仕組みで、従来のような期待出力との一致だけではなく、「その出力は適切か」「より良い回答か」といった柔軟な評価が求められる生成AI時代に対応しています。
LLM Judgeでは、入力と出力のペアに対し、「この結果は妥当かどうか」を判断するジャッジ用プロンプトを用意し、その結果に基づいてプロンプトの改善やキャリブレーションを行います。人間の専門家が関与する場合もあり、出力の妥当性や改善点を精査します。
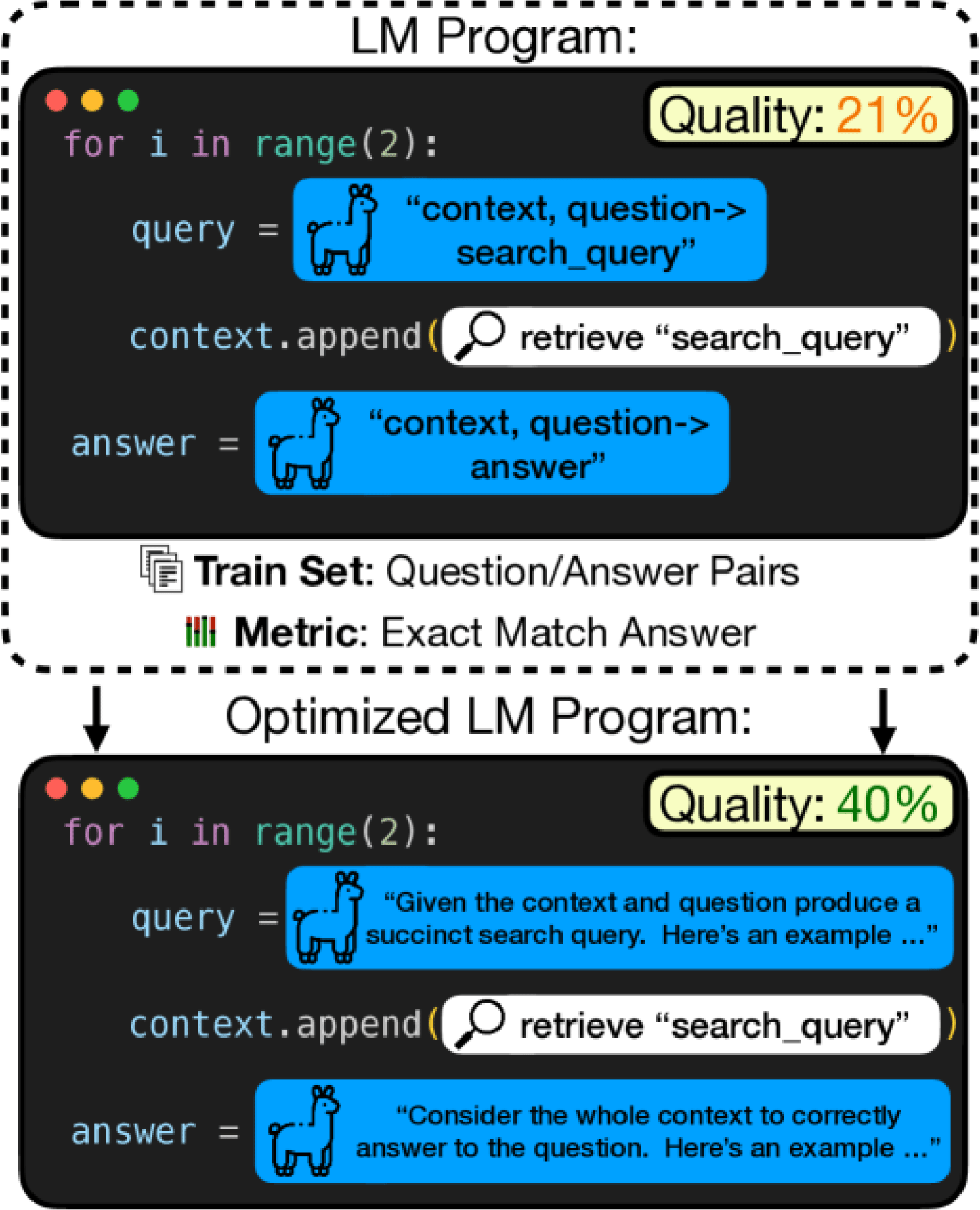
これはプロンプトを自動で最適化することができるオープンソースで、AIが評価結果に基づいて自らプロンプトを調整・改善していきます。LLM Judgeによって成功・失敗のラベルが付いた出力をもとに、DSPyはFew-shot Exampleの追加や表現の微調整、失敗条件の回避といった形で、最適なプロンプトを自動生成します。さらに、評価データの拡充を促す機能も備えており、これらのプロンプト設計・チューニングもAIの仕事になりつつあります。
これらの機能は、AIがAIを自己評価・自己改善するという全く新しいパラダイムを実現しており、AI開発の属人性を排除し、高速・高品質なAI導入が可能となります。

Databricksが新たに発表した「AgentBricks」は、AIエージェントの設計・開発・評価・改善を自然言語で完結できる統合開発環境です。これは、AIをデバッグするAI、と言えるものです。
以下は、AgentBricksの主な特徴です:
これらは、すべてDatabricksの統合プラットフォーム上で動作し、生成AI、評価AI、オーケストレーションAIが連携して一つのシステムを構築するという、非常に高度な連携が実現されています。
現時点ではまだまだAIエンジニアを対象とした機能ですが、将来的にはノーコードでのAI開発が一般化し、ビジネスユーザー自身がAIを活用する未来の実現が見えてきています。まさに、AIエージェントの民主化と呼べる流れです。
今回のキーノートでは、Databricksが長年掲げてきた「データ活用の民主化」に向けた大きな進展が示されました。特に注目を集めたのが、Lakeflow DesignerとAIによるBI支援機能の2つのデモです。

Lakeflow Designerは、自然言語による指示でETL処理を構築できるノーコードツールです。デモでは、コンタクトセンターの通話ログを用い、「案件がクローズされているか」を判定する列を追加し、担当者ごとのクローズ率を算出する処理が自然言語で実行されました。
処理内容は自動的に視覚化され、各ステップの入力・出力も容易に確認できます。さらに、プレゼンターが集計イメージ(画像)をアップロードし、「このように集計したい」と指示したところ、対応するSQLと処理フローが自動生成される様子が披露され、会場でも驚きの声が上がるほどの注目を集めました。
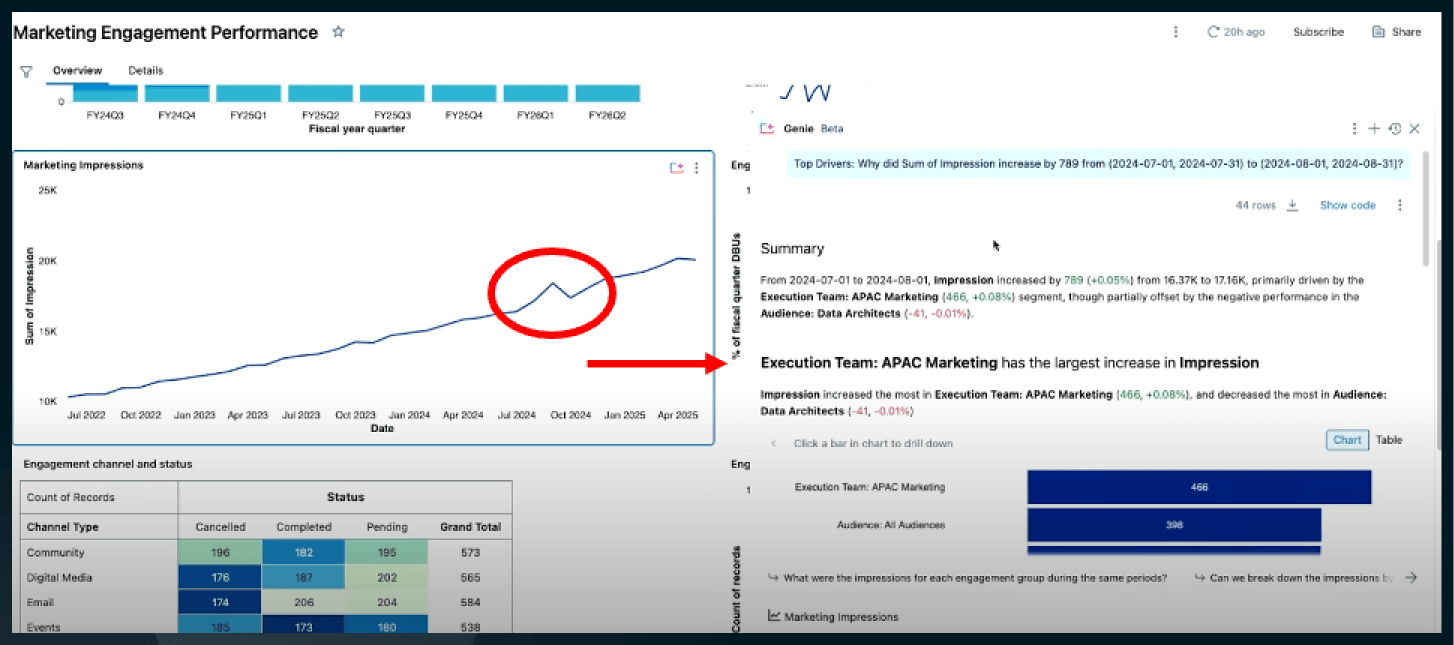
AIによる高度なクエリ処理の例として、BI分析が紹介されました。時間ごとのマーケティングインプレッションを示す折れ線グラフに急増箇所があり、その理由を自然言語で尋ねると、AIが関連テーブルを自動で検索し、「APAC地域のマーケティング活動が増加している」といった解釈を即座に提示してくれます。さらに、その根拠となるテーブルも自動表示され、背景まで把握できます。これまでこうした分析にはデータエンジニアの助けが必要でしたが、今後は自然言語だけで直感的に深い分析が行えるようになる点が、大きな進化として紹介されました。
Databricks AI & Data Summit 2025の全体を通して、dotDataが特に注目したトレンドは次の3つです:
一方で、データ活用の「民主化」には未解決の課題も残ります。この10年、分析ツールやAutoMLなどの普及にも関わらず、多くのビジネスユーザーが深い分析や洞察を引き出せていないのが実情です。デモで示されたような高度なクエリ応答を実現するには、現場で価値を出し続けるためのデータ整備が必要ですが、データ整備には大きな労力とスキルが求められます。また、データが整備された上でも、ビジネスユーザーが深い洞察を得るには、データに対して正しい「問い」を立て、そこから得られる結果を深堀りしていくスキルが求められます。
こうした課題に対し、dotDataはdotData InsightとdotData Feature Factoryという2つのソリューションを提供しています。
dotData Insightは、業務部門が主導するデータ分析をAIが支援する仕組みです。AIが業務データから自動で重要な特徴量を抽出し、ユーザーは専門知識がなくても「こういうことが知りたい」という問いをもとに分析を進められます。さらに生成AIがその結果に対する解釈や仮説設計を支援するため、分析のハードルが大きく下がります。
一方、dotData Feature Factoryは、Databricksと連携して、社内の構造化・非構造化データを特徴量化し、メタデータ付きの高品質なデータプロダクトとして活用できるようにする仕組みです。これにより、生の業務データを「シルバーデータ」や「ゴールドデータ」へと昇華させ、Unity Catalog上でガバナンスを効かせた管理が可能になります。
これらを組み合わせることで、dotData Insightは従来のBIやMLツールと連携しつつ、誰もが使える分析プラットフォームの実現を目指しています。さらに詳細なデモや活用事例について興味がある方は、ぜひお気軽にお問い合わせください。


