
Snowflake Summit 2025 レポート – AI時代に求められるクラウドデータプラットフォームの進化とは
- データ分析
- 生成AI
- DX
2025年、サンフランシスコで開催された「Snowflake Summit 2025」は、「Build the Future of AI and Apps」をテーマに、世界中から約2万人が参加する過去最大規模のイベントとなりました。日本からも300名以上が現地に足を運び、クラウドデータやAI活用に対する関心の高さが伺えました。

本記事では、特に印象的だったキーノートや新機能の数々を紹介しつつ、Snowflakeがなぜ「次世代のクラウド型データプラットフォーム」として注目されるのか、その理由を掘り下げていきます。
Snowflakeは、クラウド上でデータウェアハウス、データレイク、データエンジニアリング、そしてAI・アプリケーション開発までを一貫して実行できる、統合型のクラウドデータプラットフォームです。AWS、Azure、Google Cloudといった主要クラウドに対応し、構造化・半構造化・非構造化データのすべてを扱える柔軟性を持つ点が特徴です。また、セキュリティやガバナンス、スケーラビリティに優れ、データの集約から分析、AI活用までをワンストップで支援する基盤として、世界中の企業で導入が進んでいます。

Snowflake Summit 2025の初日のオープニングキーノートで、Snowflake CEOのスリダール・ラマスワミ氏は、「There is no AI strategy without a data strategy(データ戦略なしにAI戦略はありえない)」という明確なメッセージを発信しました。これは、AIを本格的にビジネスで活用するためには、まず堅牢で一貫したデータ戦略が不可欠であるということを強調するものです。
企業が競争力を維持・強化していくためには、構造化データや非構造化データを正確に収集し、適切に管理・活用するための基盤が必要です。Snowflakeはクラウドネイティブなデータプラットフォームとして、データの統合、ガバナンス、分析までをシームレスに実現できる環境を提供しており、まさに「AI Ready」を支えるインフラとしての役割を果たしています。
ニューヨーク証券取引所(NYSE)プレジデントのリン・マーチン氏が、「Sanctity of Data(データの神聖さ)」という表現を用い、AI活用におけるデータ品質の重要性について強く訴えました。「AIを真に機能させるには、信頼できる“真実の源(good source of truth)”が必要であり、それが欠けると、望ましくない結果(unfortunate outcomes)を招く」との指摘は、多くの参加者の印象に残ったはずです。
特に生成AIにおいては、事実に基づかない誤出力、いわゆる「ハルシネーション」がしばしば問題になります。こうした事象の多くは、元となるデータの質や構造に起因しているため、AIを有効に活用するには、信頼性の高いデータの整備と品質管理が欠かせません。この「データの神聖さ」という視点は、翌日のプラットフォームキーノートでも繰り返し取り上げられ、AI戦略を支える根幹として、データ品質の重要性が改めて強調されました。
ラマスワミ氏はまた、「The true magic of a great technology is taking something that’s very complicated and making it feel easy. The key to a great solution is simplicity.」(偉大なテクノロジーの真の魔法は、非常に複雑なものを簡単に感じさせることにあります。素晴らしいソリューションの鍵はシンプルさです。)とも語りました。これはまさに、私たちがプロダクト開発において最も大切にしている価値観の一つ、「シンプルさ」に通じる考え方です。
データサイエンスや統計といった領域は、ユーザーのスキルや知識レベルによって理解度が大きく異なります。だからこそ、dotDataでは、アドバンスドユーザーだけでなく、カジュアルに分析したい方にも最適な体験を提供できるよう、ユーザーに応じたベストなUXを日々追求しています。
AIやデータ活用が進む一方で、システムはますます複雑化しています。その結果、運用・管理が難しくなったり、理解に時間がかかるという課題も出てきています。Snowflakeはこうした状況に対し、「複雑なものをシンプルにする」ことを製品設計の中心に据えており、直感的で使いやすい体験を重視しています。この姿勢は、私たちが目指す製品開発の方向性とも一致しており、今後のAI時代においてさらに重要性を増していくと感じます。
オープニングキーノートにはOpenAI CEOのサム・アルトマン氏も登壇し、パネルディスカッションの中で2025年におけるAIとの向き合い方について問われました。その中でアルトマン氏は「Just do it(まずやってみること)」というシンプルな言葉を選びました。
AI技術が日進月歩で進化するなか、慎重に計画を練りすぎるよりも、まず小さくてもいいから実行に移すことが重要である──というアルトマン氏の考え方は、現場の担当者にも経営層にも強いインパクトを与えるものでした。AI時代の不確実性の中で、スピード感を持ってチャレンジする姿勢の大切さを再認識させられる発言でした。


2日目のプラットフォームキーノートではSnowflakeの執行役員製品担当クリスチャン・クレイナーマン氏らが、同社の主要なアップデートを紹介しました。
今回は、データとAIに関するイノベーションを、顧客の視点に立ってわかりやすく伝える工夫として、「I want…(〜したい)」というニーズ表現を軸に、さまざまなユースケースが提示されました。それに対してSnowflakeがどのような機能で応えるのかを、「You can…(〜できる)」という形で紹介する構成となっており、顧客のニーズとSnowflakeのイノベーションをつなぐ形で、各アップデートの意義が語られました。
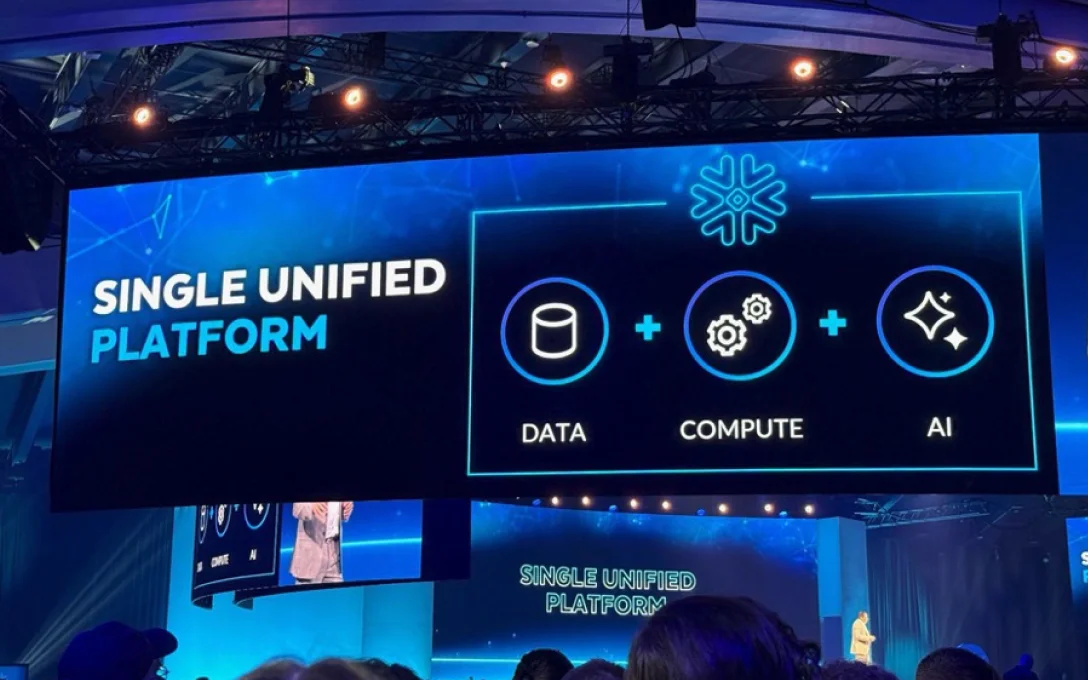

Snowflakeは、将来的な拡張性と柔軟性を備えた Single Unified Platform として進化を続けており、ビジネスの新たなニーズが発生した際にも、データの場所やシステムの違い、さらにはコンピューティングの環境差にもとらわれず、迅速に対応できる基盤を提供しています。これは、データのライフサイクル全体にわたってユーザーの取り組みを支援するという設計思想に基づいています。
その中核となるのが、オープンフォーマットである Apache Iceberg のサポートです。Iceberg は構造化・非構造化を問わず、大規模データを効率的に管理できるテーブルフォーマットであり、柔軟なデータアーキテクチャの構築を可能にします。SnowflakeはOSS開発支援にも積極的に取り組んでおり、Apache Iceberg の Variant 型のサポートなど、相互運用性とオープン性の向上に貢献しています。
さらに、Apache Polaris Catalogとの連携によって、Snowflake外部のクエリエンジンやデータ分析基盤との接続も可能となり、コンピューティングリソースを外部と柔軟に連携させながら、エコシステム全体としての拡張性を確保しています。これらの技術基盤により、Snowflake はAI時代のデータ活用に求められる「将来性のあるデータアーキテクチャ」の実現を支えています。
データガバナンスの観点では、Snowflake Horizon Catalog が中核機能として位置付けられており、データの発見・理解・アクセス制御ポリシーの適用・タグ付け・継承管理など、組織全体での安全かつ効率的なデータ活用を実現しています。たとえば、センシティブデータを自動的に検出・タグ付けし、その情報が派生テーブルにも引き継がれる仕組みにより、厳格かつ一貫性のあるデータ管理が可能です。
Snowflake Horizon Catalogでは、個人情報などのセンシティブデータを自動的に検出し、タグを付与する機能が備わっています。これにより、あるテーブルに機密性の高い情報が含まれている場合、そのデータを元に作成された新たなテーブルにも自動でタグが継承され、情報漏洩リスクを低減できます。
機密データを直接扱えない開発・検証環境向けに、既存のテーブルをベースにしたダミーデータの自動生成機能も提供されています。ただのランダムデータではなく、元データの分布を模倣した構造になっており、分析可能な品質を保ちつつ、安全性も確保されています。
社内に存在するデータ資産やAIアプリケーションを横断的に管理・検索できる Internal Marketplaceも導入されています。利用者は目的のデータやアセットをポータル上で検索し、利用申請を行うことができます。管理者は申請の内容を確認し、使用目的やコストなどを把握した上で、承認・制御を行う仕組みとなっています。
この仕組みにより、大規模組織内での安全なデータ共有と再利用が促進され、データの価値を最大化しつつ、コンプライアンスやコスト管理との両立が可能になります。
さらに、このInternal Marketplaceは dotDataとの親和性も高く、たとえばdotDataで生成された新たな特徴量テーブルなどを、社内の他部門と安全かつ効率的に共有・利活用するためのデータ分析基盤としても機能します。特徴量というビジネスに意味のある情報を、Internal Marketplace上で「データプロダクト」として取り扱うことで、組織全体でのAI・分析活用を加速させることが可能です。
このように、SnowflakeとdotDataの連携によって、データのガバナンスと実用的な分析活用が一貫したプロセスで実現される点は、非常に大きな利点と言えるでしょう。
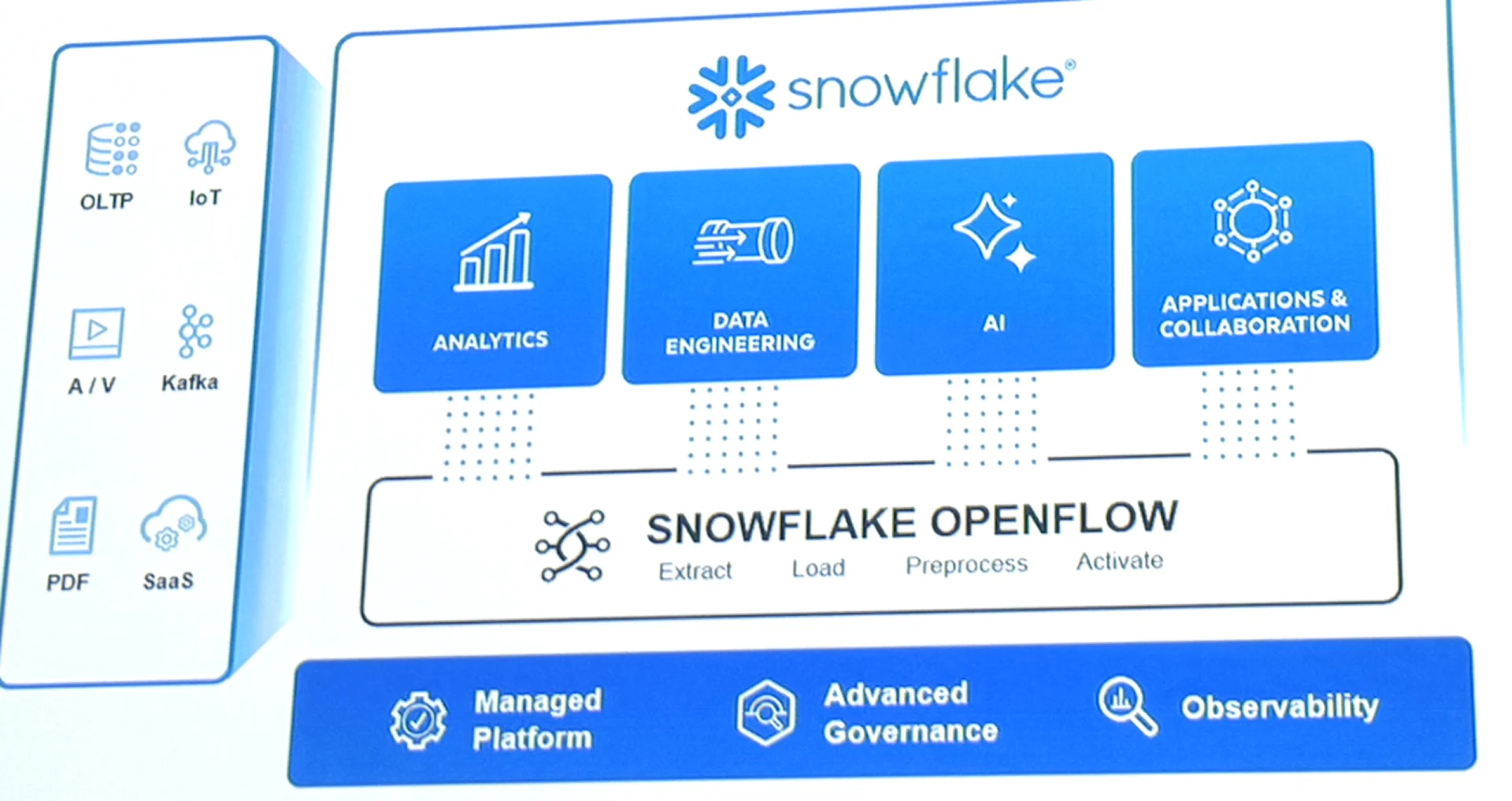
Snowflakeはもともと構造化データに特化したデータ分析基盤として発展してきましたが、AI時代を迎える中で、非構造化データやストリーミングデータも含めた統合的なデータ処理基盤へと進化を遂げつつあります。
今回発表された新機能「Snowflake Openflow」は、その象徴的な取り組みの一つです。Openflowは、バッチ処理、ストリーミング、ファイルベースなど多様なデータソースを、統一されたインターフェースでSnowflakeに取り込むことができるパイプラインサービスです。
Openflowは、オープンソースのApache NiFiを基盤としており、Snowflakeが公式にサポートしていないような特殊なデータソースにも柔軟に対応可能です。GUIベースで視覚的にパイプラインを構築できるため、エンジニア以外のユーザーにも扱いやすい設計となっています。
この仕組みにより、従来は複雑なETL開発が必要だった非構造化データやリアルタイムデータの取り込みが、よりスムーズにSnowflake上で実現できるようになりました。
このOpenflowの背景には、Snowflakeが買収したDatavoloの技術統合があります。買収後、自社プラットフォームに組み込まれたことで、Snowflakeとの親和性が飛躍的に向上。データの取り込みから活用まで、エンドツーエンドで支援する強力なデータパイプライン基盤として提供されています。
Snowflakeは、従来のデータウェアハウスの枠を超え、アプリケーションホスティング基盤としての機能拡張を進めています。データに加え、アプリケーションを同一基盤上で実行・管理できるようになることで、データドリブンな意思決定とアクションをシームレスにつなぐことが可能になります。
今回新たに発表された「Snowflake Postgres」は、PostgreSQL互換のマネージドデータベースです。従来、Snowflakeは分析用途に最適化されたデータ基盤であり、トランザクション処理にはやや不向きとされてきました。しかし、Snowflake Postgresの登場により、業務アプリケーションやトランザクション系のシステム開発もSnowflake上で実現できるようになります。
たとえば、昨年 GA となった Snowflake 内でコンテナ化されたアプリケーションを実行・管理できるフルマネージドサービスの「Snowpark Container Services」と組み合わせることで、いわゆる業務アプリケーションをSnowflakeのセキュアで統制された環境内でホスティングすることができるようになっていくような方向性が考えられます。
これが実現すると、企業はデータ分析とアプリケーション実行の両面を同一基盤で管理できるようになり、開発・運用の効率性と一貫性が大幅に向上できそうです。
Snowflakeのこうした進化により、データ分析から施策実行までをワンストップで行える環境が整いつつあります。データを集めて終わりではなく、インサイトを即座にアプリケーションやサービスに反映することで、ビジネスインパクトを最大化できるようになります。
Snowflakeが新たに発表した「Cortex AI SQL」は、構造化データと非構造化データの垣根を超えて、SQLで直接クエリを実行できる革新的な機能です。これまで、画像・音声・テキストなどの非構造化データを扱うには、ETL処理や特徴量の抽出、ラグ(RAG)の構築など、手間のかかる前処理が必要でした。
AISQLを使えば、こうした前処理を行わずに、直接SQLを使って非構造化データを分析することが可能になります。これは、構造化データ中心だった従来のBI・分析ツールとは一線を画す進化です。
AISQLでは、生成AIがクエリを補助することで、今まで困難だったユースケースも簡単に実現できます。たとえば、以下のような複雑な分析が可能になります。
このように、SQLと生成AIを組み合わせることで、画像・テキストなどの非構造化データをシームレスに活用できる点がAISQLの大きな特長です。
AISQLの活用シーンは上記にとどまりません。たとえば、以下のような業務にも応用できます。
これらをSQLベースで実現できることで、データサイエンスやMLの専門知識がなくても、高度な分析とインサイト抽出が可能になります。
AI、とりわけ生成AIをビジネスで活用する際、壁となるのが「クラウドデータや構造化データに含まれる“意味”をAIが理解できていない」という課題です。たとえば、「売上」や「クリック率」といった言葉ひとつをとっても、組織ごとに定義や計算方法は異なります。Snowflakeのようなデータプラットフォーム上に蓄積されたビッグデータを、文脈に即して活用するには、システム的なデータとビジネス的な意味づけを橋渡しする仕組みが必要になります。
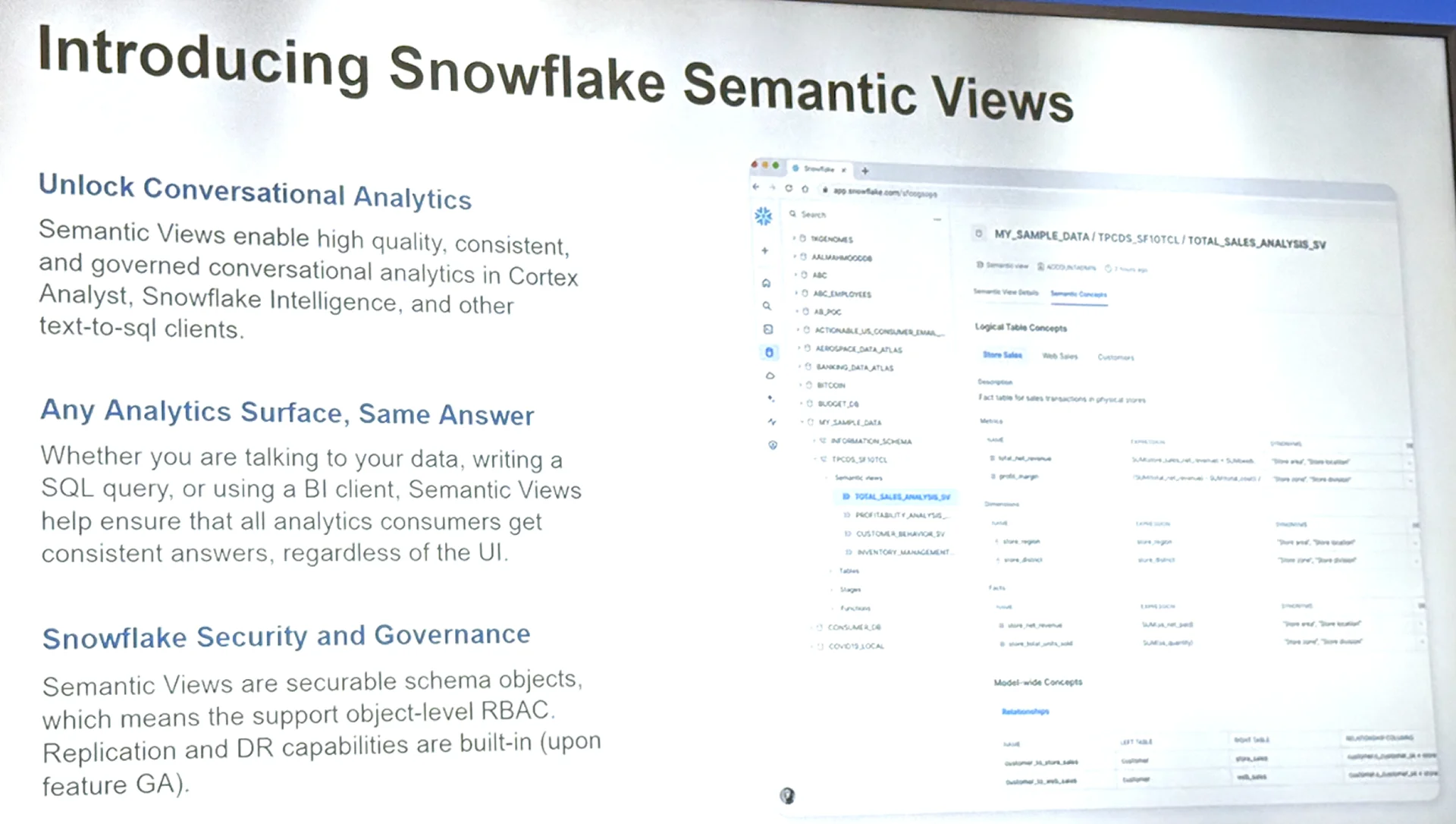
Snowflakeは、この課題に対する解決策として「Semantic View」という新たなクラウド型データプラットフォーム機能を導入しました。Semantic Viewは、売上や利益といったビジネス用語と、Snowflakeのデータウェアハウス上にある実際のデータソースや計算式をひも付けて定義できるレイヤーです。この定義を通じて、生成AIは自然言語の質問に対して、どのテーブルの、どのカラムを、どのように集計すればよいのかを自動的に判断できるようになります。
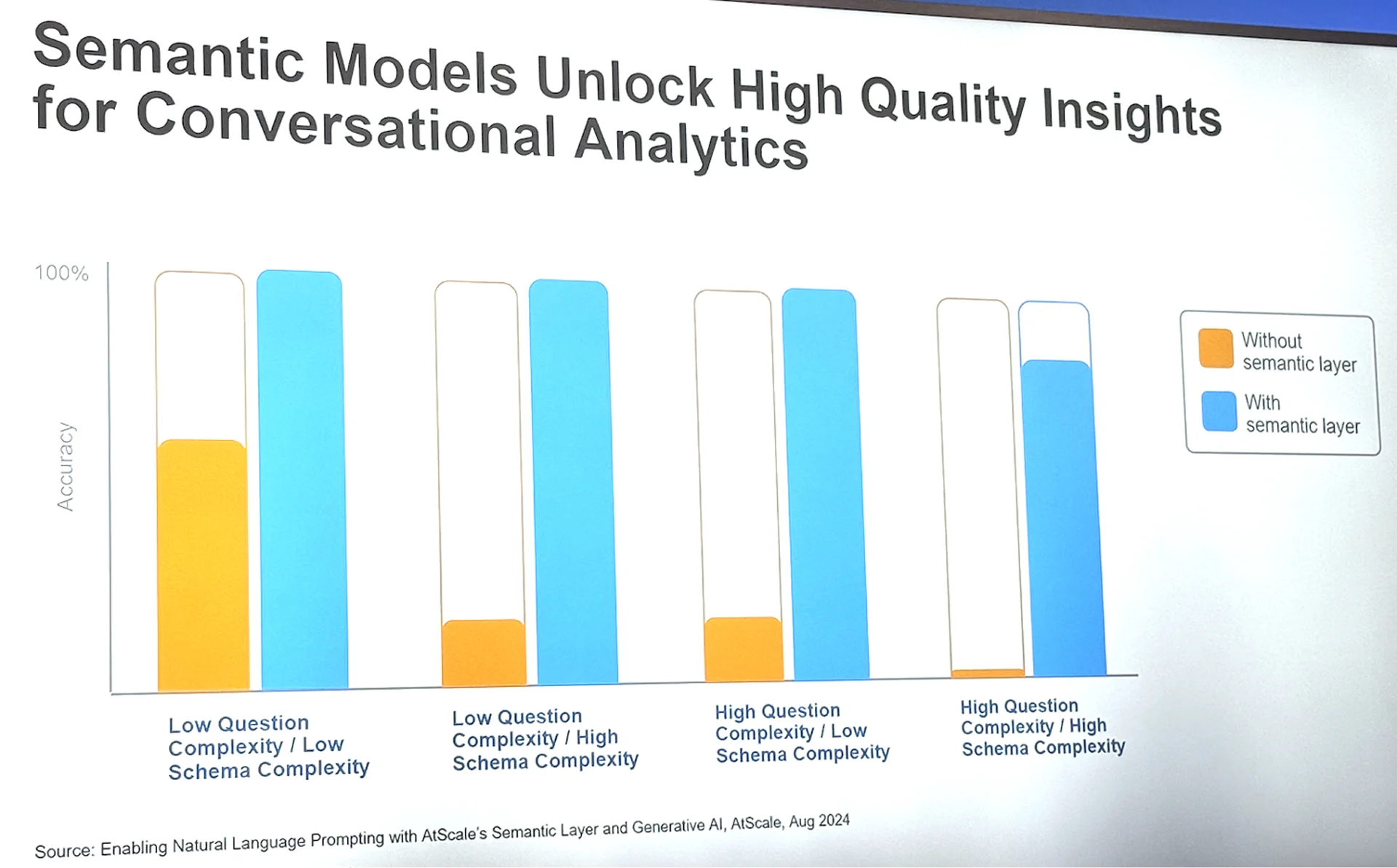
生成AIに対して「この月のクリック率を教えて」と質問しても、クリック率の算出式や参照すべき期間、使用するテーブルが明確でなければ、AIは正しいSQLを生成できません。実際、Snowflakeのセッションでは、Semantic Layerを使用した場合と使用しない場合で、自然言語クエリに対する正解率に明確な差が生じるという検証結果も共有されていました。Semantic Layerを適用したケースでは、AIが正しい回答を返す割合が大幅に向上しており、「意味を与えたデータ」がAI活用の前提であることが、改めて裏付けられました。
Semantic Viewによって実現されるのは、単なるデータの補足情報ではなく、「組織として共通の意味でデータを見る」ためのフレームワークです。これにより、AIが人間のようにビジネスコンテキストを理解し、意図に即した答えを返すことが可能になります。AIの正確なアウトプットは、その背後にあるデータ構造と意味付けがいかに整備されているかにかかっています。SnowflakeのSemantic Viewは、まさにその要となる仕組みです。
Snowflake Summit 2025で最も注目を集めた機能のひとつが、「Snowflake Intelligence」と呼ばれるAIエージェント機能です。従来のBIツールやアシスタント機能では、あくまでユーザーが明確な意図を持って操作する必要がありました。しかし、Snowflake Intelligenceは、それを一歩進めて、「ユーザーの代わりに仮説を立て、適切な分析を行い、結果を提示する」ことが可能な、自律型のAIエージェントです。
たとえば、ユーザーが「今月のフェスティバルチケットの販売トレンドを教えて」と自然言語で入力するだけで、Snowflake Intelligenceは内部のSemantic viewやユーザーの権限情報を参照し、必要なデータにアクセス。適切な分析処理を自動で行い、結果を可視化して提示してくれます。
この流れは、ユーザーが明示的に「どのテーブルを使って、どんな条件で分析するか」といったことを指定する必要がないため、非技術者でも容易に高度な分析を行えるという大きなメリットがあります。
AIエージェントの信頼性を支えているのが、前述のSemantic Viewとの連携です。単に生成AIが自由にSQLを作るのではなく、組織で定義されたビジネスロジックに基づいてクエリが生成されるため、「何となくそれらしい答え」ではなく、「ビジネス的に正しい答え」を導き出せるようになっています。この仕組みにより、「AIは何を根拠にその結論を出したのか?」という説明責任(Accountability)にも対応することができ、企業にとっても安心して導入できる要素となっています。
このようなAIエージェントの進化により、データ分析や活用のハードルは一気に下がりつつあります。これまで専門部署やデータサイエンティストに依存していた業務でも、現場の担当者が自らAIを活用して仮説検証や施策立案を行える時代が到来しようとしています。Snowflake Intelligenceは、その第一歩となる画期的な機能であり、「AIを使う」のではなく「AIと共に業務を進める」という新しい業務スタイルを現実のものにしようとしています。
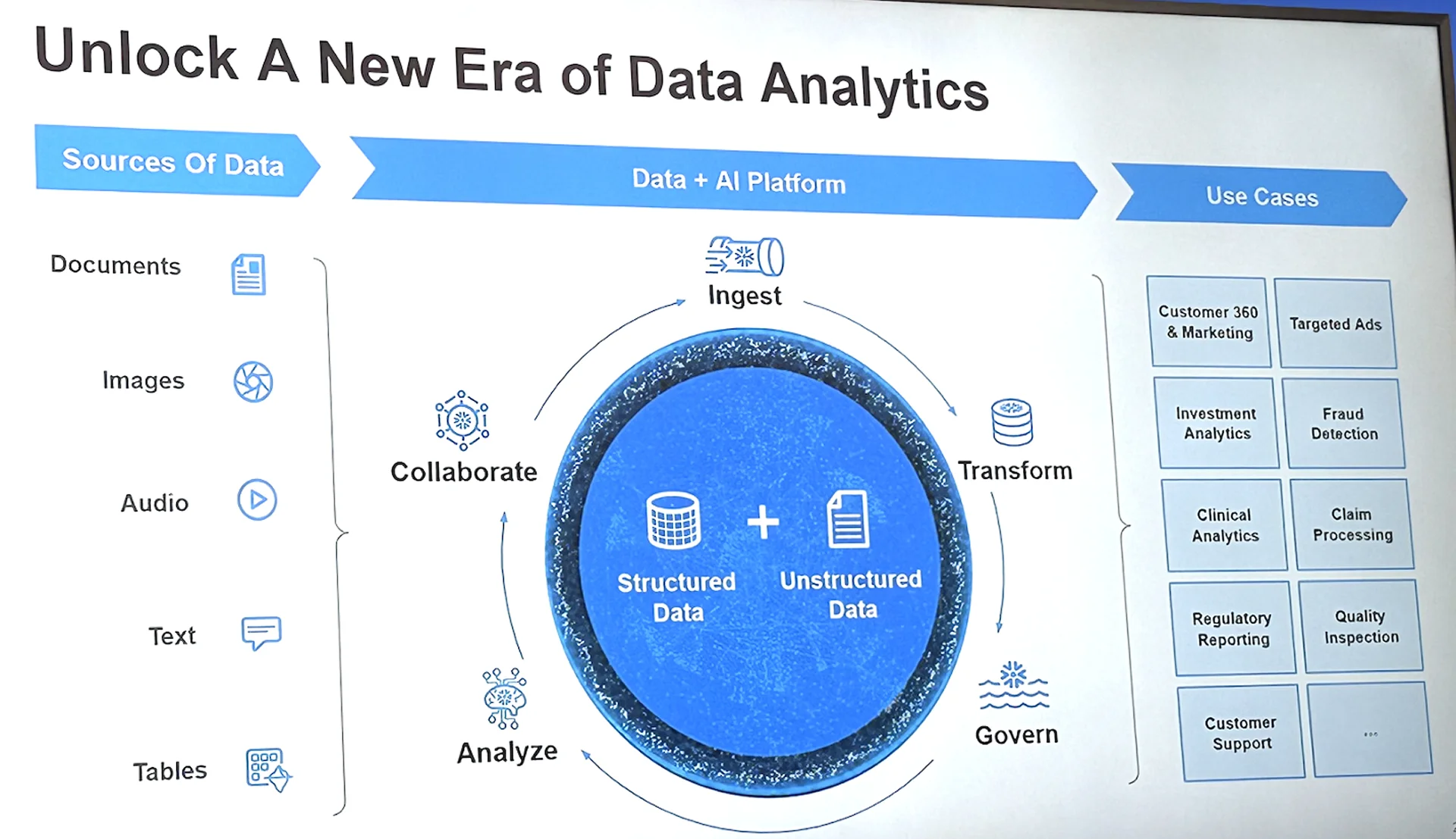
Snowflake はクラウド型データプラットフォームとして、データウェアハウスとデータレイクの両方を兼ね備えたハイブリッドな構成を実現しており、クラウドネイティブなアーキテクチャにより、構造化データ・非構造化データの双方に柔軟に対応しています。
本サミットで発表された数々の機能は、まさに「AI時代に最適化されたクラウドデータ基盤」の方向性を示しています。クラウド上の膨大なデータをどのように統合し、どのように活用するか、その問いに、Snowflake は確かな答えを提供し続けているのです。
AI時代の競争力を高めるために、Snowflakeの導入を検討する企業が増えているのも納得です。今後、Snowflake と dotData の連携がさらに進むことで、日本企業のAI活用も次のステージへと進化していくことでしょう。
Snowflake Summit 2025では、「AI Ready(AI活用の準備が整った状態)」というキーワードが繰り返し登場しました。AIをビジネスで活用するには、単にデータを集めるだけでなく、整理・管理し、インサイトへと変換できる状態にしておくことが求められます。この「AI Ready」を実現するうえで、SnowflakeとdotDataの連携が重要な意味を持ちます。
Snowflakeは、構造化・非構造化を問わず、膨大なデータを効率的に蓄積・処理・ガバナンスできる、強力なデータ基盤を提供しています。しかし、蓄積された“生データ”は、ビジネスインサイトに直接つながるとは限らず、活用には仮説の立案やSQLの知識が必要になる場合もあります。
そこで有効なのが、dotDataが提供するdotData Feature Factoryです。これは、Snowflakeに蓄積されたデータから、AIが特徴量(ビジネスの目的に対応するデータに隠れた重要なパターン情報)を自動生成する仕組みです。生成された特徴量は、Snowflake上でガバナンスを維持したまま、他部署やアプリケーションと安全に共有できます。
さらに、dotData Insightと組み合わせることで、生成された特徴量からビジネスKPIへの影響要因を発見し、施策立案や対象リストの抽出までを、専門知識なしで直感的に実行することが可能になります。
このように、SnowflakeとdotDataを組み合わせることで、
という一連の流れを、一気通貫で実現できます。
すでにSnowflakeを導入しており、次のステップとしてAI活用や高度な分析に取り組みたいとお考えの企業、あるいは可視化を超えた深い示唆を得たい企業にとって、この連携は極めて有効なアプローチとなるでしょう。自社のデータをもっと活かしたい、AI活用を次のフェーズに進めたいとお考えの方は、ぜひ一度ご相談ください。


