
データ活用のためのデータ基盤とは?構築プラクティスとアジャイルデータモデリング
- データ加工
- データ分析
- DX
今日のビジネス環境は変化が激しく、競争力を維持するためにはデータ活用が不可欠となっています。しかし、「データ活用」と一口に言っても、実際に推進するには様々な課題が存在するのが現場の実情です。本ブログでは、なぜ今データ活用が重要なのか、その推進を支えるデータ基盤とは何か、そしてデータをより効果的に活用するためのデータモデリングについて解説します。
データ活用の重要性が高まっている背景には、大きく分けて2つの時代の潮流があります。1つはITの技術革新で、AIやLLM(大規模言語モデル)が急速に発展し、データを活用した予測や意思決定が高度化しています。もう1つはデータの多様化です。これまでは基幹システムの一部のデータしか活用できませんでしたが、現在ではデバイスデータ、IoTデータ、オープンソースデータなど、様々な種類のデータが利用可能になっています。
この2つにより、かつては経営やリスク管理、社内業務改善が中心でしたが、今では商品・サービスの高度化や新たな価値創造へと広がっています。さらに顧客行動履歴分析によるパーソナライズ、サプライチェーン最適化、MaaSやBPaaS、ロボティクス、スマートシティといった新たなサービスの創出が可能になっています。
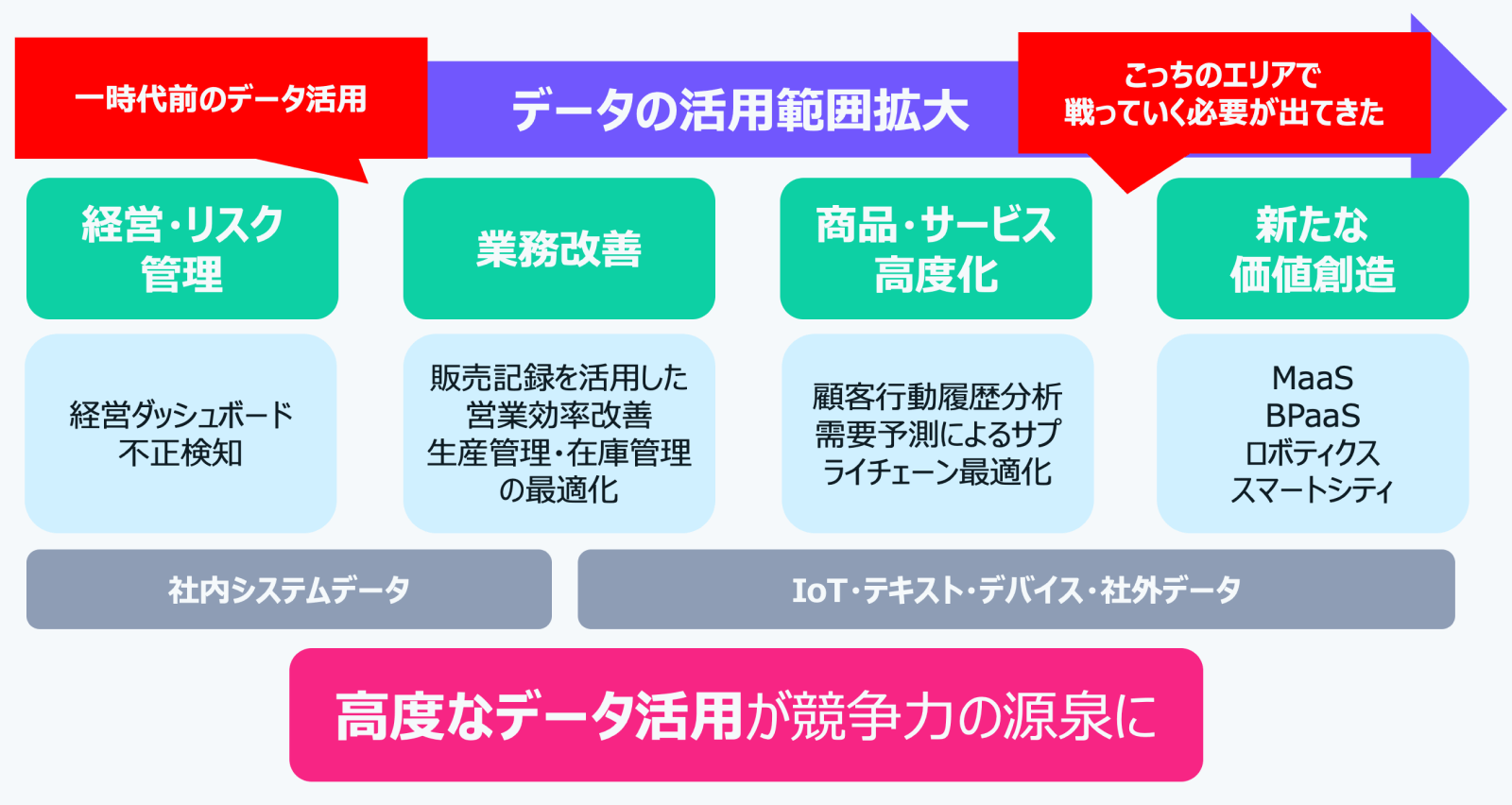
このように、高度なデータ活用は企業の競争力の源泉となっています。市場で勝ち抜くためには、自社のデータを見直し、高度に活用していくことが不可欠です。
ここまででデータ活用の重要性は理解しても、現実はそう簡単ではありません。データ活用を推進する上で立ちはだかる代表的な課題が3つあります。
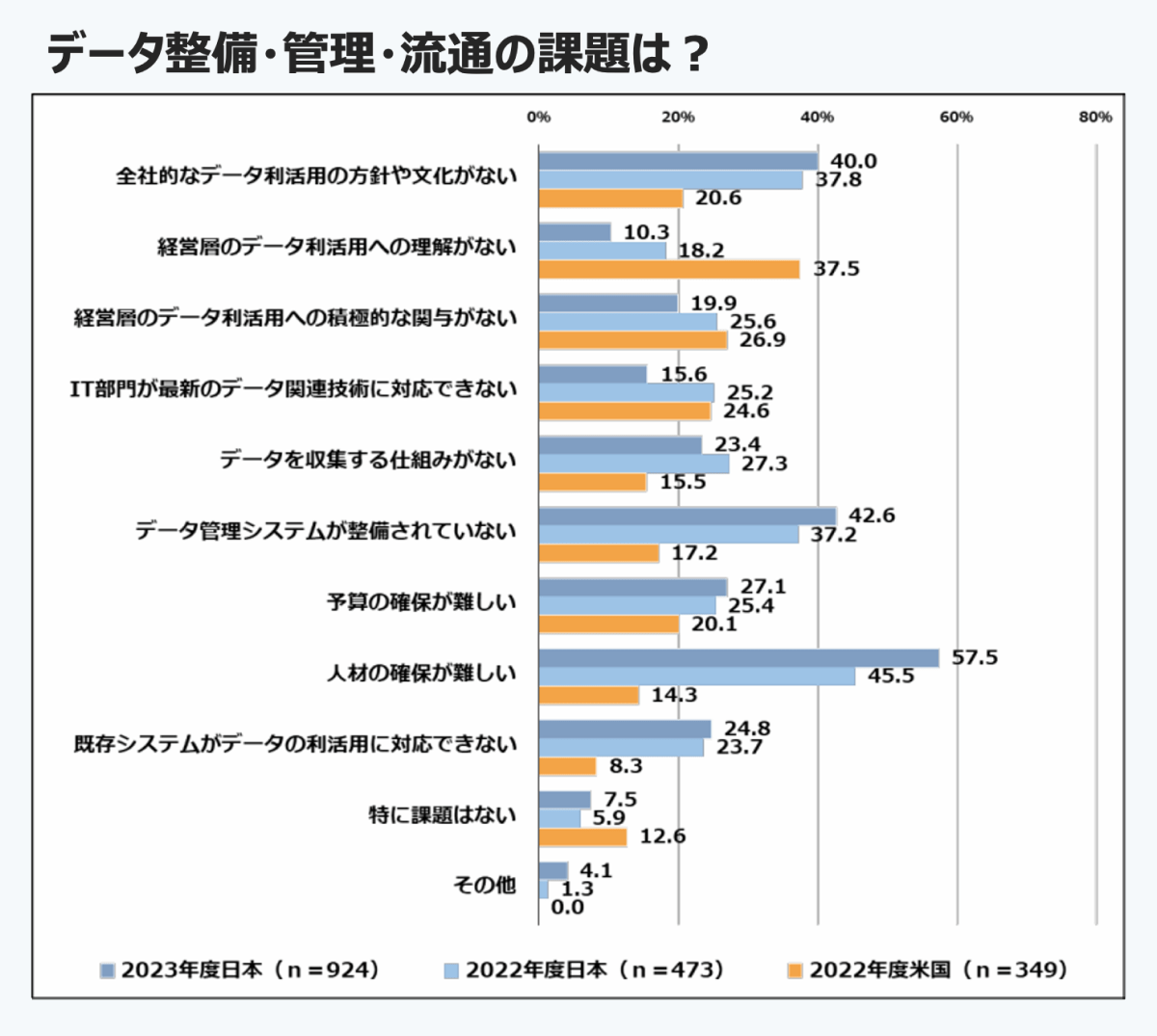
IPAの2023年の調査によると、企業の57.5%がデータの整備・管理・流通における最大の課題として「人材の確保の難しさ」を挙げています。特に、高度化する技術や多様なデータを活用できる人材、すなわちデータサイエンティストやエンジニアなどの高度人材が不足している実態が浮き彫りになっています。
さらに、同調査では約40%の企業が「全社的な方針や文化の欠如」も課題に挙げており、データの整備が進んでも、現場の担当者がその活用方法を理解できず、結果としてデータ利活用が進まないケースも多いことが示されています。
データのサイロ化とは、部門やシステムごとにデータが分断され、相互に連携されていない状態を指します。このような状況では、企業全体として多くのデータを保有していても、特定の目的に必要な情報を横断的に集めることが困難になります。また、同じ「売上」といった指標であっても、部門やシステムごとに定義や計測方法が異なる場合があり、こうした不一致が分析結果にばらつきを生じさせたり、誤った意思決定につながったりするリスクがあります。サイロ化は、データ活用の効率や精度を大きく損なう要因の一つです。
たとえ課題を乗り越えてデータの活用が進んだとしても、そこには新たなインシデントのリスクが伴います。まず懸念されるのがセキュリティリスクです。データ量が増加する中で、一元的な管理体制が整っていないと、アクセス権限の管理や監査体制が不十分になり、不正利用やプライバシー情報の漏洩といったリスクが高まります。加えて、データの定義や前提が組織内で十分に共有されていない場合、誤った解釈にもとづくデータ利用が発生するおそれがあります。その結果、活用によって得られるはずの知見や判断が不正確となり、期待していた効果が得られなくなってしまいます。
これらの課題を解決し、データ活用を円滑に進めるための仕組みが、データ基盤です。
データ基盤とは、企業や組織が様々なデータを集約し、一元的に管理、分析、活用するための基盤です。大量かつ多様なデータをビジネス上の意思決定やサービス開発に生かす仕組みを統合的に提供し、様々なデータを集約し、ビジネスに活かすことがデータ基盤の要となります。
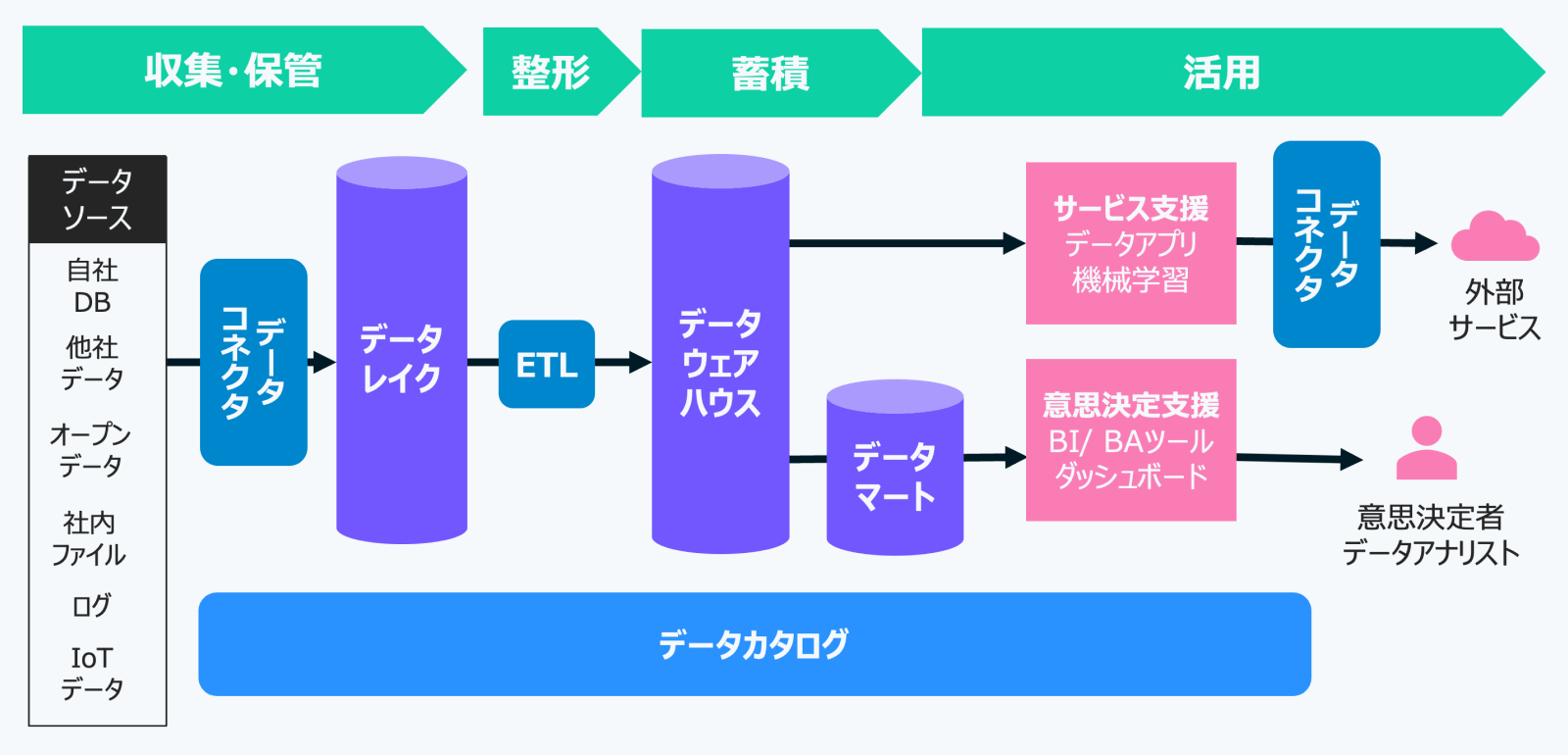
一般的なデータ基盤は、データをビジネスに活用するための一連のプロセスを担っています。その主な機能は、大きく4つの段階に分けて捉えることができます。
まず初めに行われるのが「データの収集と保管」です。これは、データベースやIoTデバイスなど、多様なソースからデータを取り込み、整形せずにそのまま保存するフェーズです。構造化データ・非構造化データのいずれにも対応する必要があり、後の処理に備えて、なるべく生データのまま保持しておくことが重要です。
次に、その収集データに対して「整形処理」を施します。ここでは、表記ゆれの統一、重複の排除、個人情報のマスキングなど、データの品質を高めるためのクリーニング作業が行われます。この段階を経ることで、分析や利活用に適した状態へと整えられていきます。
整形されたデータは、その後「蓄積」されます。このフェーズでは、単に保存するだけでなく、実際のユースケース――たとえば分析やサービス提供――に応じて、最適な形式で保持されます。収集・保管との違いは、この”目的に応じた再編成”にあります。
そして最終的に、「活用」の段階へと進みます。蓄積されたデータは、BI(ビジネスインテリジェンス)やBA(ビジネスアナリティクス)ツールを通じた意思決定支援に使われたり、データアプリケーションとしてサービスやプロダクトに組み込まれたりします。こうして、データは具体的なビジネス価値へと変換されていくのです。
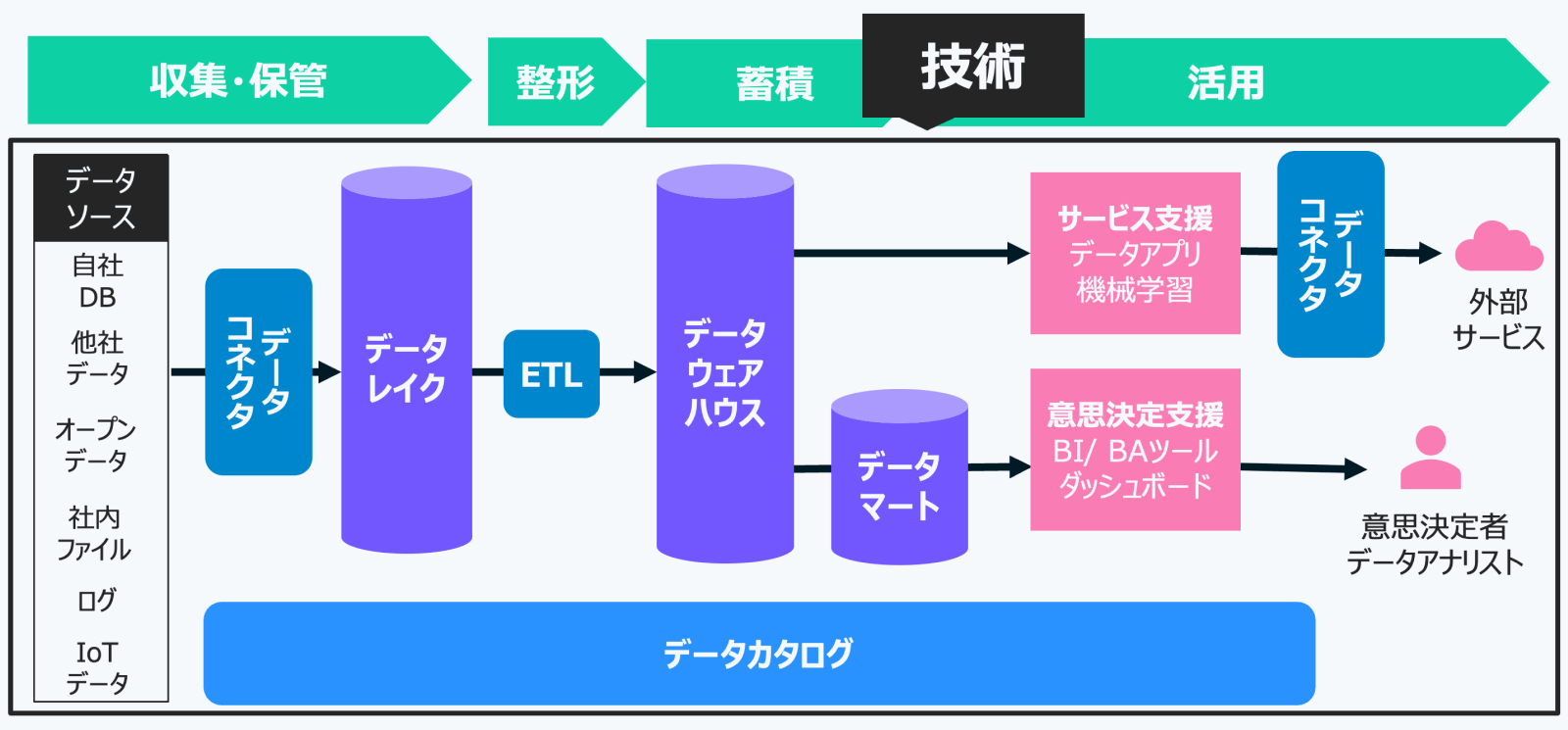
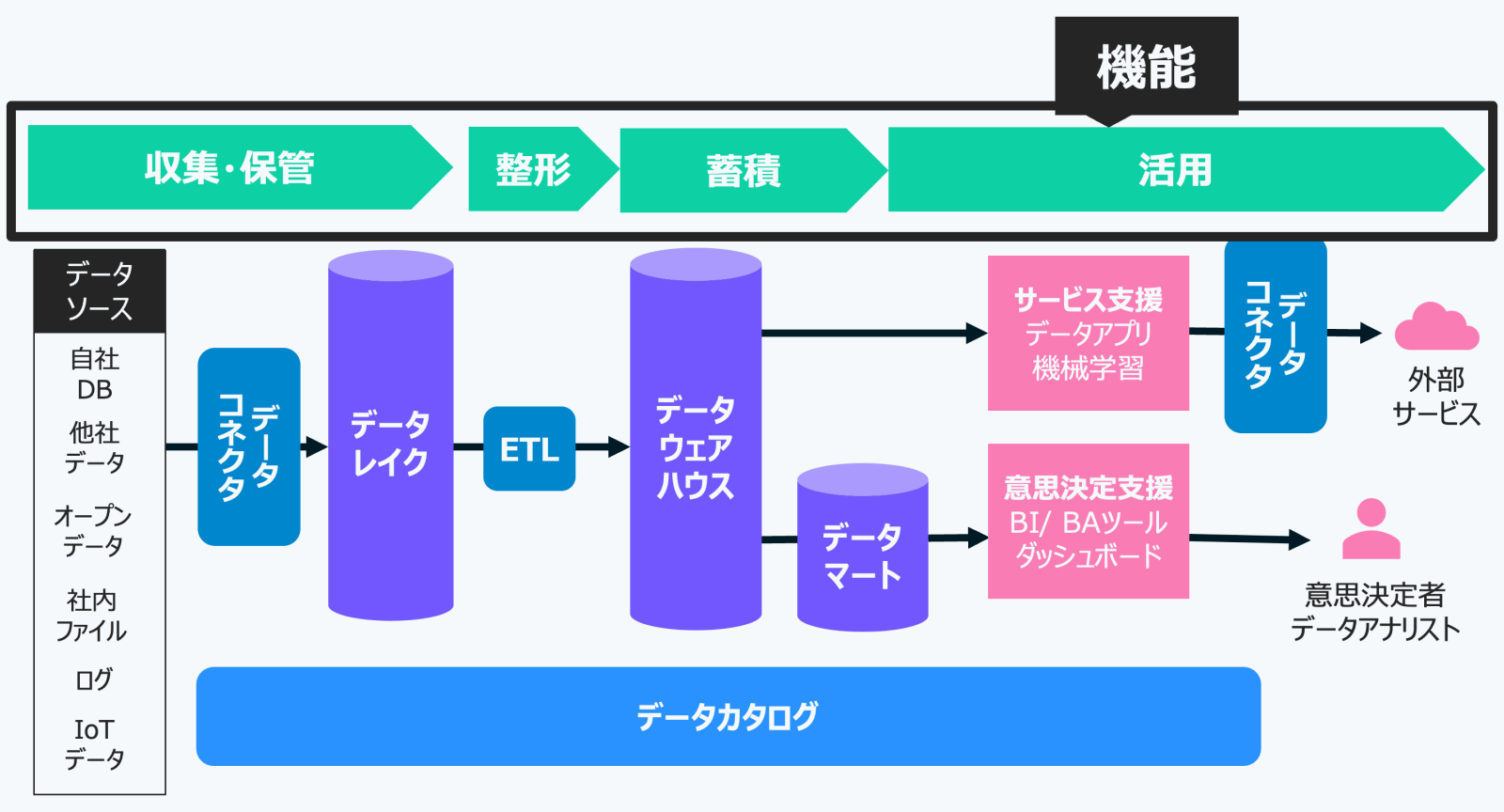
上記の機能を具体的なシステムとして実現するための技術要素が以下の7つです。
データコネクター(Data Connector)は、様々なデータソースからデータレイクにデータを収集・転送する仕組みです。多種多様なデータソースへの接続管理を担います。Fivetransやtoroccoなど、この責務に特化したSaaSもあります。
データコネクターから転送されたデータを、ありのままの形で大量に蓄積するための仕組みがデータレイク(Data Lake)です。構造化データ、半構造化データ(JSONなど)、非構造化データ(画像、音声、テキストなど)を問わず、あらゆる形式のデータを保存できるのが特徴です。データレイクを設けることで、後工程でのETLやモデリングを効率的に検討できるようになります。データウェアハウスと異なり、収集時にデータの形式やモデリングを厳密に定義する必要がありません。
補足:構造化データはRDBやCSVのようなテーブル形式のデータ。非構造化データは画像や音声、テキストなど。半構造化データはJSONのようにカラムが固定されていないデータ。
Extract(抽出)、Transform(変換)、Load(格納)の略で、データレイクからデータを抽出し、活用しやすいように加工・整形し、データウェアハウスなどに格納する仕組みです。データ品質の管理やセキュリティ対策もここで行われます。定期的なバッチ処理で実行されることが多いです。
データウェアハウス(DWH)は 企業内外のさまざまなデータを分析・レポート用途に最適化して蓄積するためのデータストアです。単なる“データを保存する場所”ではなく、大量データを効率的に集計できるよう設計された分析専用の基盤で、データ基盤の「肝」となる要素と言えます。
データマート(Data Mart)は、データウェアハウスの中から、特定の利用部門や分析テーマに合わせて必要なデータを切り出し、使いやすい形にまとめた小規模なデータウェアハウスです。データウェアハウスが大規模で全社的に使われる場合に、部門ごとに小回りの利くデータを利用したいという場合に作成されます。ただし、データマートを無計画に乱立させると、先に述べたデータのサイロ化を招く可能性があるため注意が必要です。
データ基盤の最終目的は、収集・整形・蓄積したデータを活用することです。具体的には、サービス支援として商品やサービスの向上、ユーザー体験の改善、業務効率化に活用され、例えば機械学習による予測やレコメンドシステムが含まれます。また、意思決定支援としては、経営層やアナリストがBIツールやダッシュボードを用いてデータに基づいた判断を行い、戦略を決定します。データは、ビジネス価値を創出するために活用される重要な要素です。
データカタログ(Data Catalog)とは、データの場所や意味、使用方法を整理し、必要な人が簡単にアクセスできるようにします。メタデータには、ファイル名やテーブル名の基本情報に加え、データの定義や更新頻度、保存期間なども記録され、部門間での共有を助けます。リネージ情報は、データの出所や変換経路を追跡でき、品質問題の原因を特定するのに役立ちます。最近では、Apache IcebergやApache Hudiなどのオープンソース技術も普及しています。
これらの技術要素が連携することで、データ収集から活用までの一連のプロセスが実現されます。
データモデリングとは、組織が必要とするデータの構造や関係性を整理・定義し、システムや業務に活用できる形に設計するプロセスです。特にデータ基盤においては、データウェアハウスやデータマートにどのような形式でデータを格納すると、より正確で再利用しやすく、分析しやすいデータになるかを設計する役割を担います。データ基盤を「より良いものにするため」にデータモデリングが存在すると言えます。
データモデリングには、大きく分けて二つのカテゴリーがあり、業務システム用とデータ分析用にわけられます。

業務システム用データモデリングは、日常業務のトランザクション処理(データの書き込みや更新)に最適化されたモデリングです。データ構造は正規化を行い、データの冗長性を排除し、整合性を保つことを重視します。また重要な処理として書き込み、更新があり、正確性とパフォーマンスが求められます。更新頻度はユーザが絶え間なく使うことが一般的なため、リアルタイムです。
一方、データ分析用データモデリングは、データの検索や集計といった分析処理に最適化されたモデリングです。ディメンショナルモデリングとも呼ばれます。データ構造は正規化はせずに、分析に必要なデータを結合して持ち、集計のパフォーマンスを向上させることを重視します。重要な処理は検索、集計で、分析者が直感的にデータを理解し、高速にクエリを実行できることが求められます。更新頻度はETLの実行タイミングなど、定期的に行われます。
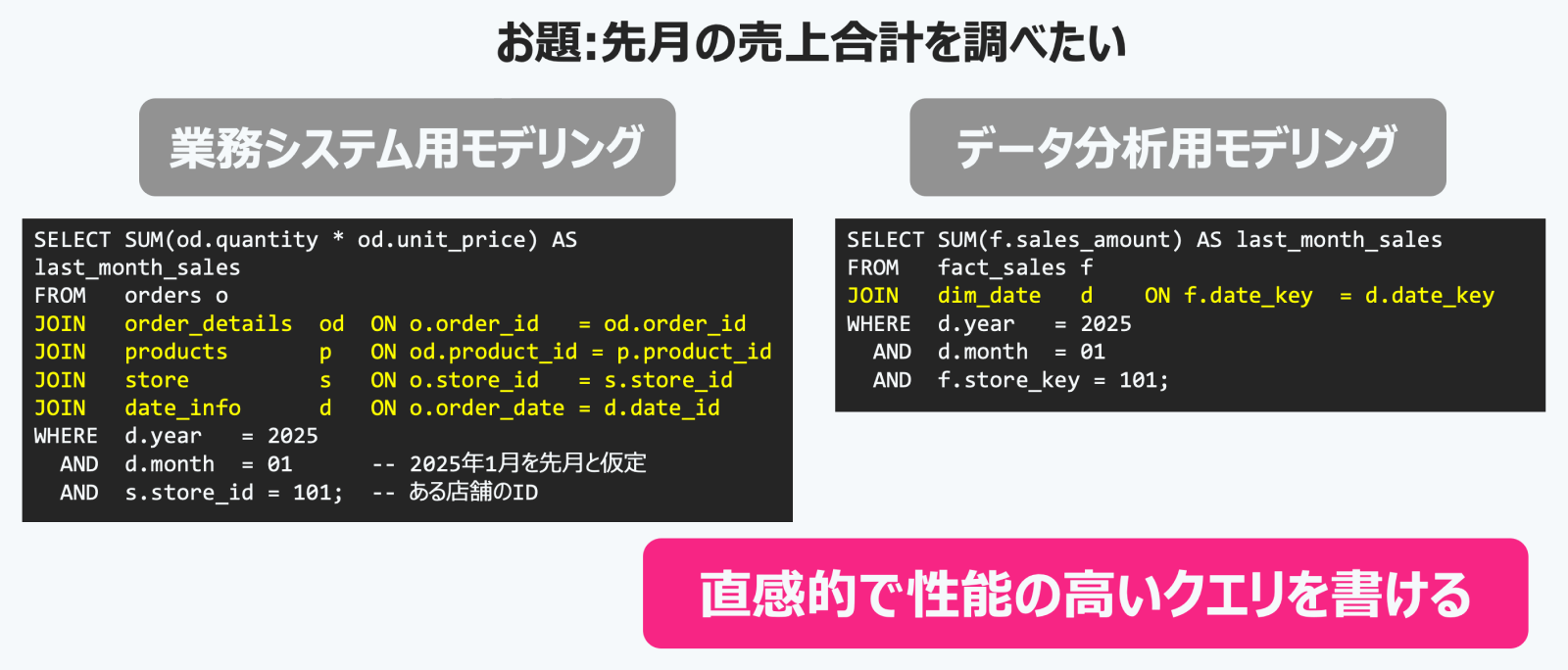
両者の違いを具体例で見てみましょう。例えば、「先月の特定店舗の売上合計」を分析したい場合、業務システム用モデルでは正規化されているため、複数のテーブルを結合(Join)して集計する必要があります。分析者はどのテーブルがあり、それらをどう結合すれば目的のデータが得られるかを理解している必要があります。一方、分析用モデルでは、売上という分析対象(ファクト)を中心に設計されているため、日付や店舗といった条件(WHERE句)を指定するだけで簡単に集計できます。これにより、分析者は直感的に、かつ高性能なクエリを実行できるのです。アジャイルデータモデリングに関する書籍でも、正規化はビジネスステークホルダーにとって複雑すぎるという指摘がある通りです。
分析用データモデリングで最も有名なものの1つがスタースキーマです。これは、ファクトテーブルとディメンションテーブルの2種類のテーブルを用いてデータ構造を設計する方法です。
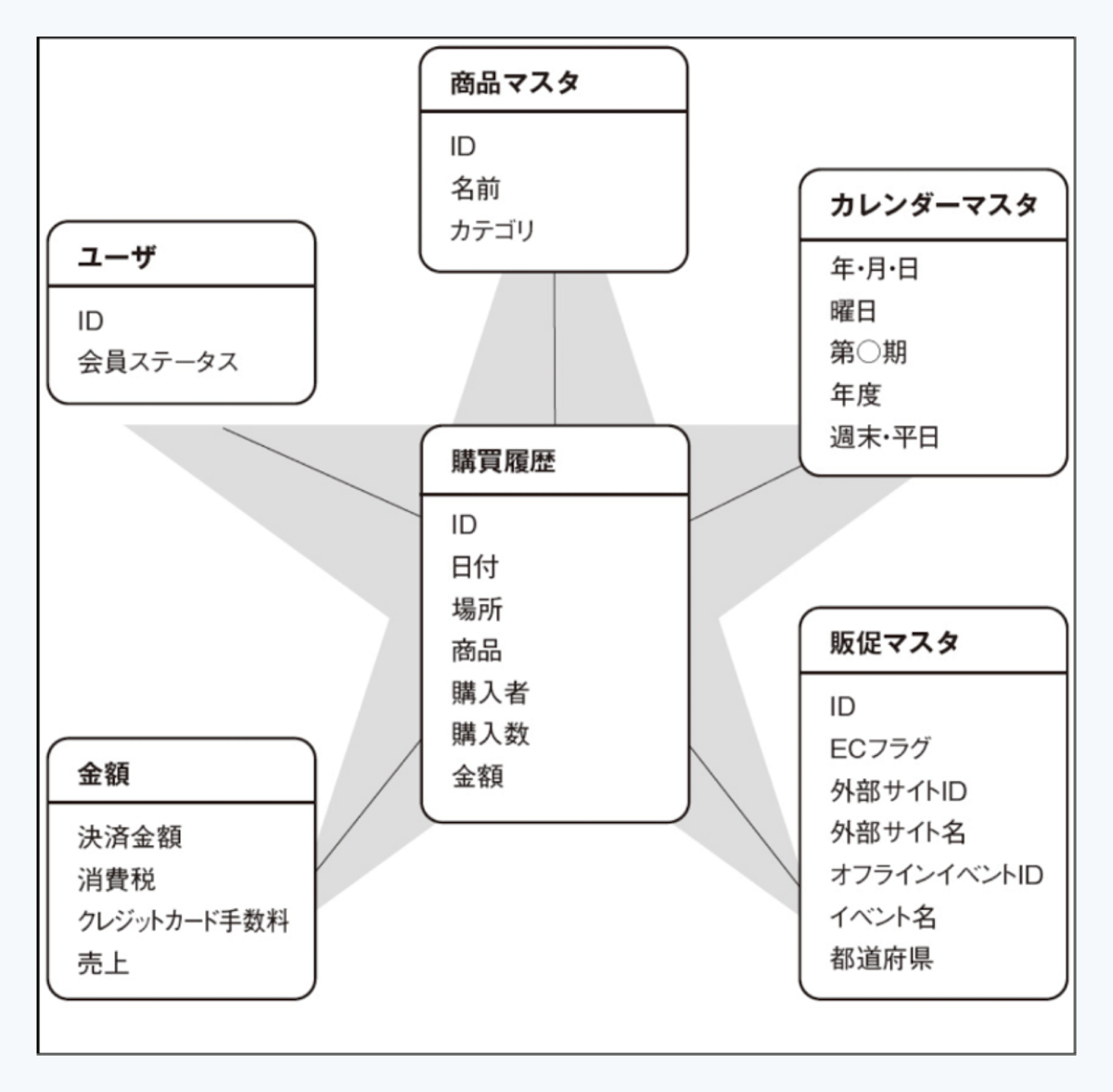
ファクトテーブルとは、ビジネス観点で計測・分析したい対象を表します。例えば、売上合計や商品購入といった「事象」や「測定値」がこれにあたります。分析の要望を基に、まずファクトテーブルを定義するのが最初のステップです。
ディメンションテーブルは、ファクトテーブルをどのような切り口で分析したいかを表します。日付、商品、ユーザー、店舗、金額帯などがディメンションにあたります。
スタースキーマでは、中央にファクトテーブルがあり、その周りをディメンションテーブルが取り囲む構造になります。この形が星のように見えることから「スタースキーマ」と呼ばれています。分析したい対象(ファクト)ごとにスタースキーマが作成されるイメージです。
データ基盤構築とデータモデリングは、一度行って終わりではありません。ソースでは、以下のようなプロセスが推奨されています。

このプロセスは、矢印が双方向になっているように、行き来しながら進めることが重要です。ETL構築中に設計上の問題が見つかったり、活用から新たな分析ニーズが生まれたりすれば、議論や設計に戻って見直しを行います。
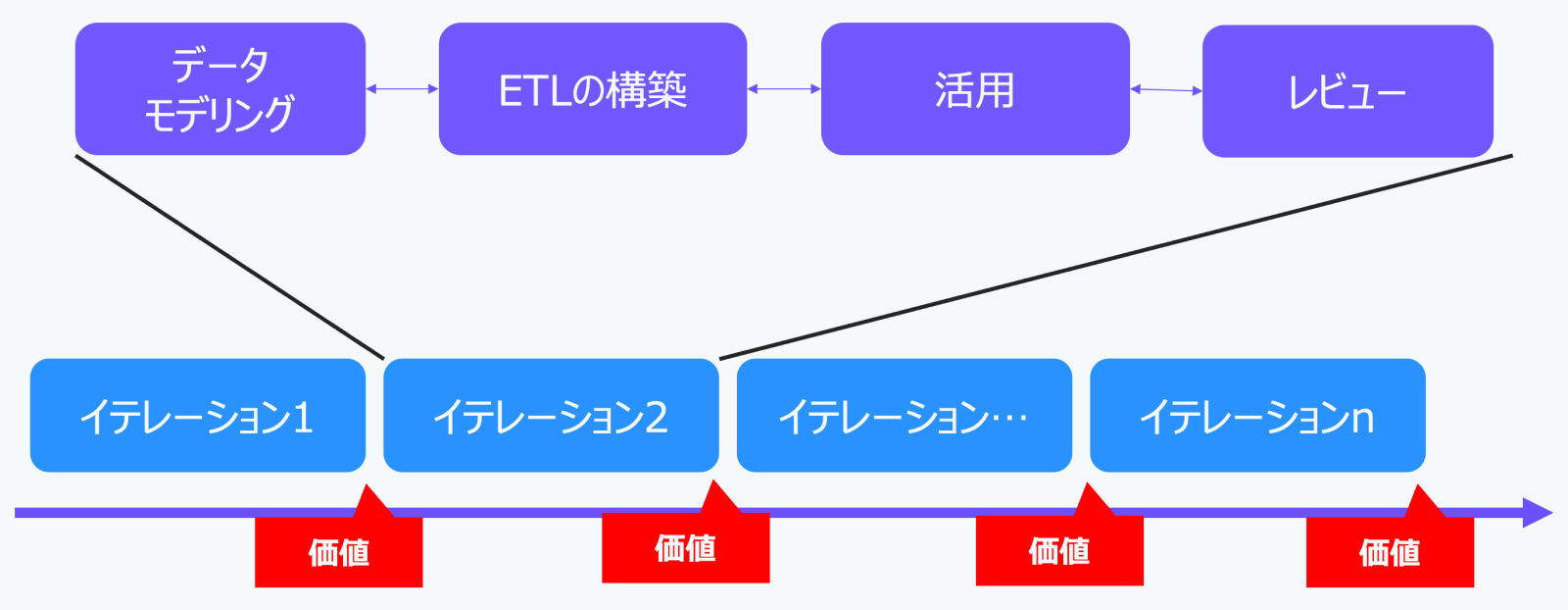
さらに、このプロセスをアジャイルに、すなわち反復的、段階的、協調的に進めることが、よりビジネス価値を創出するデータモデルを作る上で重要とされています。例えば、2週間や1ヶ月を1イテレーション(繰り返し)として、その期間内に議論、設計、構築、活用、レビューの一連のプロセスを行います。
これは、ソフトウェア開発におけるアジャイル開発の考え方と共通しています。データモデリングも同様に、小規模なサイクルで議論・設計、ETL構築、活用、レビューを回すことで、インクリメンタルに価値を実感しながら進めることができ、間違った方向へ進むリスクを減らし、チームの効果的な動きを促進できます。
dotDataは、このようなデータ活用を強力に支援するアプローチをとっています。その特徴は、一気通貫でのデータ活用サポートです。データ基盤を構成する様々な要素・機能を、自社のプロダクト群で担当しています。
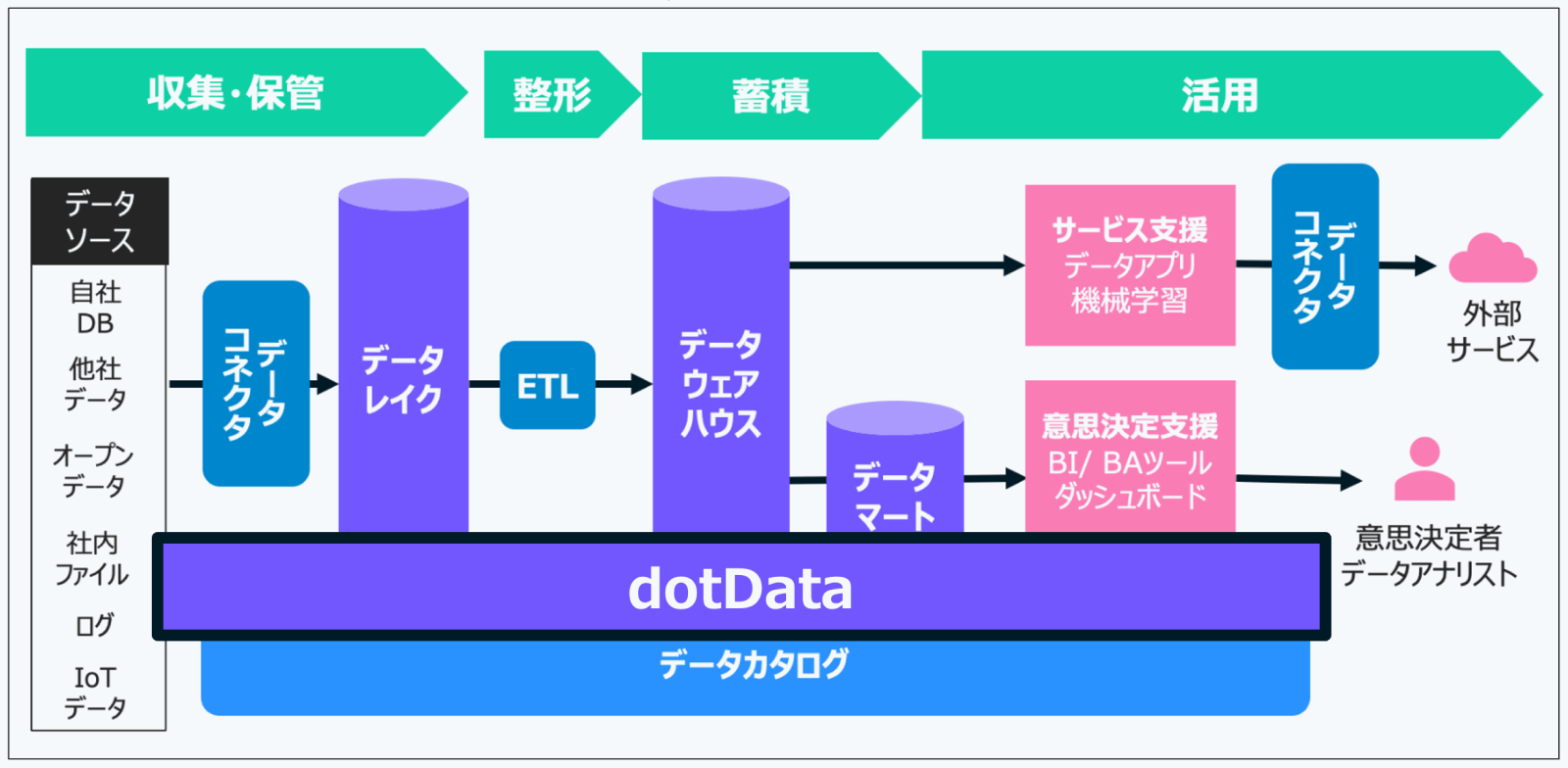
dotDataのプロダクト群を活用することで、データモデリングのアジャイルプロセス(議論、設計、ETL構築、活用、レビュー)を高速化することが可能です。これにより、イテレーションの速度が向上し、結果として得られるビジネス価値も拡大・改良されます。
激しい環境変化の中で、競争力を保ち続けるためにデータ活用の重要性はますます高まっています。しかし、単にデータを集めるだけでは不十分で、それを価値に変えるためには、課題の克服と基盤の整備が欠かせません。dotDataは、こうしたデータ基盤の構築やデータモデリングを含むデータ活用プロセス全体を強力に支援しています。もしデータ活用にご興味をお持ちであれば、ぜひお気軽にお問い合わせください。


