
Webinarのスクリプトもご覧ください。↓
こんにちは。dotDataのwebinarをご覧いただきありがとうございます。
私は dotDataの山本と申します。よろしくお願いいたします。本日は、企業データの業務活用を加速させるデータプロダクトというタイトルで皆様にご説明差し上げたいと思います。
まず、自己紹介からさせていただきます。山本と申します。 dotDataの日本法人である dotDataジャパンというところでデータサイエンティストを務めております。皆様と一緒に今まで色々な分析をしてきた経験も踏まえて、今日の講演をさせていただきたいと思いますので、よろしくお願いいたします。
dotDataは、2018年に創業してまだ若い会社です。
色々なところからのご評価もいただいておりますが、何が得意かと申しますと、企業にあるデータは、必ずしも分析に対して使いやすいものの状態で保存されてないところで、そこのデータを活用するためのデータに、うまく変換をしてくる、使いやすい状態まで持っていくことに非常に長けた技術とサービスを提供しているという会社でございます。
今日は、データプロダクトや、特徴量の共有というお話をさせていただくのですが、我々が今までやってきたような知見を踏まえてご説明ができればと思っております。
発表のアジェンダは、最初に少し「データプロダクト」という言葉が出てくるので、データプロダクトとは?という概念をご説明します。それから、「特徴量ストアと特徴量の共有」について、データプロダクトの実現方法の一形態についても、御説明いたします。そして、最後に、弊社がそういったところにどのように関与しているのかについて、 dotDataのご紹介を差し上げたいと思います。
活用しやすいデータの形
では、データプロダクトのところからご説明いたします。本ウェビナーの前提として、活用しやすいデータの形っていうのはどのようなものを少し想定してお話を聞いていただいた方が分かりやすいかなと思うので、皆様と共有するためにこの資料を用意しました。
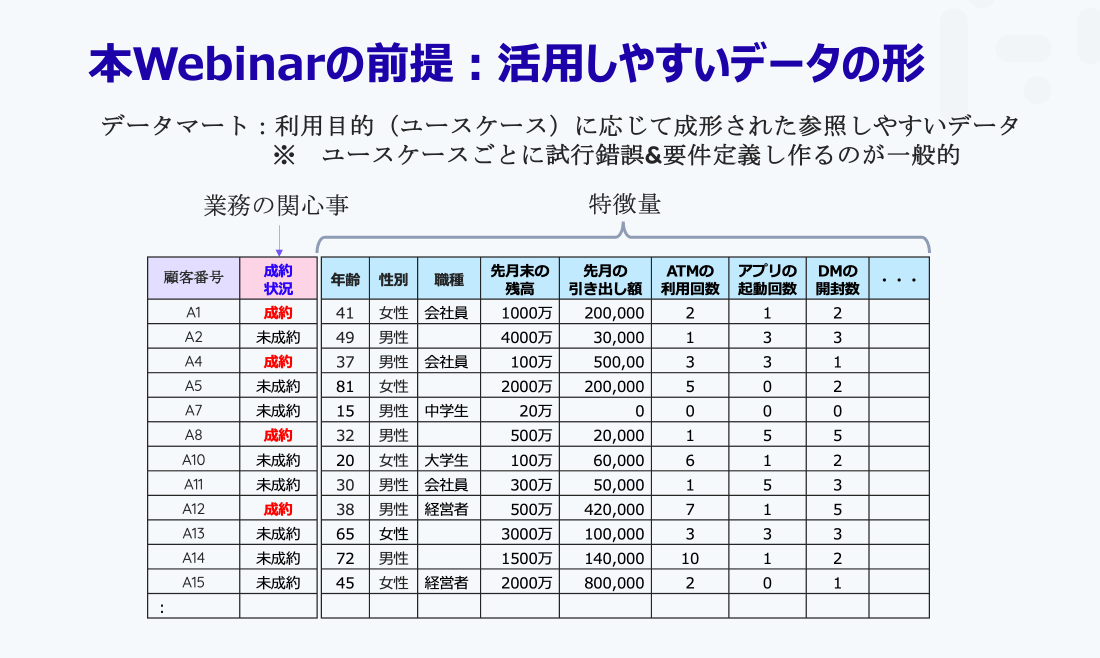
よく言葉としては、「データマート」というような言葉の言われ方をするのかなと思うのですが、ある利用目的(この資料とか他の資料とかユースケースという言葉)に応じて成形された参照しやすいデータのことを「データマート」と呼んでいると思ってください。
例えば、銀行業の方がだと、金融商品として何かをご購入されている方は、どのような人たちなんだろうか?と、上のようなものがデータマートとして用意されてると、とてもデータの活用がしやすいのです。
例えば、積立NISAとか投資信託とか何でもいいのですが、そういったものに対してあるお客様達がズラーと並んでいる中に、ある方は成約をなさっているし、ある方はまだ成約されていないという状態があると、どういった方が成約されるのだろうかなどの、情報があると助かります。
さらに各お客様に対して、例えば年齢とか性別とかあるいは職種であったり、その方の属性データが完備されていると、どういった方々、どういう年代層にこの商品は興味があるんだろうということが分かったりするかもしれませんし、或いは、もう少し行動的であれば、先月末の残高はいくらなんだろうとか、先月引き出したのはいくらなのか?といったような(例えばATMに何回行ったかとか、アプリを何回起動したのか)、その人の行動によって生まれてくるデータというのも、その人を特徴付ける上では面白いデータになるかもしれません。もしかして成約する方と成約されない方で、そのような情報が違うのかもしれません。
このような情報をきちんと集めて管理しておくと、色々なデータ活用の可能性というのが考えられます。これを可視化するでもいいですし、例えばATMの利用回数と成約状況って関係しそうだと分かれば、ATMの利用回数を表示して月次で表示してこの人たちがちょっとずつ利用回数が高まっているんだなということが、分かったりするかもしれませんし、あるいはもう少し、こういう条件を引き出すようなルールを作ってみようとなったりとか、あるいはもう少しもっと機械学習をして予測をしましょうかとか、色々なデータ活用の可能性というのがこういうデータがあると考えられます。ただし、そのユースケースに応じて考えていく必要があるデータではあるので、例えば試行錯誤をしたり、要件定義をして作っていくのが一般的な状況かなと思います。こういうデータがあれば便利だよね、というところをまずご共有させていただきました。
データプロダクトとは?
次に、データプロダクトとは?の概念について御説明をします。データプロダクトという言葉自体は、少し前にはなりますが、2022年に、ハーバードビジネスレビューで発表されている概念になります。
まず、こちらはどちらかと言うと、トラディショナルな方式で説明されている資料で、銀行さんのケースですが、例えばデジタルバンキングをやりたいとか、投資ポータルを作りたいとか、そういったユースケースが書いてあり、左側がそれを実現する為に、色々なところにデータがありますよねという話です。データプラットホームって書いてあるところが、一時期よく言われていたデータレイクとかビッグデータと呼ばれる、色々なデータをかき集めてきましたという層です。
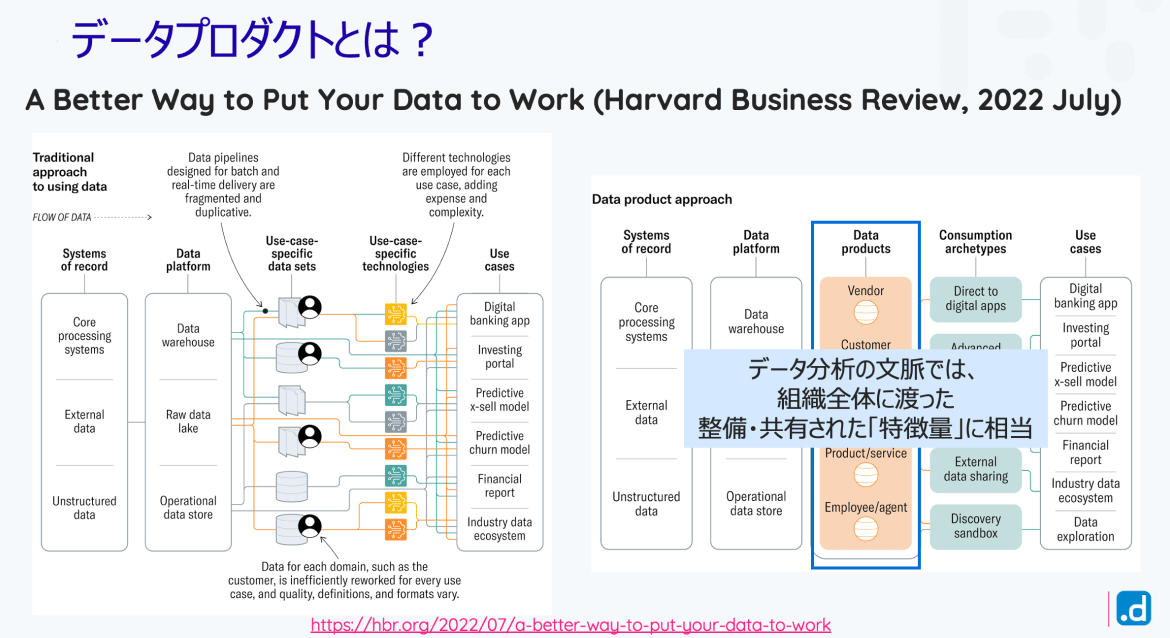
その時に、色々なユースケースを作る時に、今までかき集めてきたデータを何かしらさっきのようなデータマート、利用しやすい形態にデータを変えて特殊な技術、特別な技術を使って各ユースケースを実現していくっていうことをやっているのではないでしょうかという絵がここには書かれています。
例えばデータのパイプライン。パイプラインと呼んでるのは、業務データ、生でどんどん蓄積されているデータから、例えば最終的にどんな人が買うのかっていうのを可視化するようなことがあったとして、そこに至るまでのさっきのデータの成形をして可視化する、ビューまで持ってくることを、データパイプラインと呼びますが、そのデータパイプラインがユースケースごとに独立して作られていませんか?とか、そこに担当者とか部門がアサインされていて、その方々が作るとすると、そこからはバラバラでどんどん作っているとか、中にはお客様の分析をしているとか、お客様の状態を把握するようなユースケースはたくさんあるはずなのに、そこは全然共有されてないとか、データパイプライン再利用されていなくて、同じようなところと、他のところでもやっているとか、そのような事は、起こっていませんでしょうか?
あるいはそのユースケースごとにデータがツールからサイロ化されている。そこに特化したツールっていうのがずらっと並んでいて、それも共有されていない、そんな状態になっていないでしょうか?っていう指摘がされているというのが伝統的なやり方だということで、紹介されています。
一方でこうあるべきではないかというところに登場してるのが、データプロダクトという考え方になっていて、プロダクトと書いてあるので製品だということなんですね。データ領域ごとにちゃんと使う方のことを考えてデータを準備しておいたという、そういった層を設けるというのがデータプロダクトです。ですので、ここに層が増えていて、例えばベンダーさんの軸だったら、こういうデータの見方をした方がいいのか、カスタマーの層、お客様の層だったら、こういうデータの見方をする、しといたほうがいいよね、とか、さっきのデータマートのイメージを持っていただけるといいとか、そういうデータを準備しておいた方がいいとか、視点ごとにこういうデータの準備をしておいた方がいいとか、そういったものを、うまくみんなが再利用できるものは再利用して伝えながらユースケースを実現していくっていう、構成をとった方がいいんじゃないかということを提唱してるのが、データプロダクトになります。
ですので、イメージとしてはそれほど難しくなくて、さっきのデータマートの、大きい版みたいな、色々なところで、領域で使えるデータマートがざっと準備していて、そこから自分の必要なものを取ってこられるような世界を作るべきであるというのが書いてあるということです。
このデータ分析の文脈で言いますと、先程の私が最初に共有しますといった状態のところで、これっていうのはそれが特徴量と呼んでる各軸ですね。WEBアプリで何回起動したのかとか、ATM何回行ったのかみたいなのが影響するかもしれませんねっというデータです。それが特徴量に該当するものになろうかと思います。では、その特徴量というものは、データプロダクト自体の概念ですが、特徴量をどのように実装していくのか、作っていくのかという部分に関して、いろいろな取り組みがありますので、そこをご紹介したいと思います。
特徴量を共有するということで、どんな特徴量を共有するのか、共有すべき特徴量っていうのは?という概念も出てくるので、そこも少しお話ししたいと思います。
特徴量ストア
特徴量ストアという概念自体は、2018年から19年ぐらい北米で提唱されておりまして、Uberのミケランジェロというプロジェクトでで作っていたものがはしりじゃないかと言われています。で、狭義にはですね、機械学習ですね。その後にAIが予測するようなモデル、予測するようなもの、数式やルールを作るための事前準備として定義されているっていうのがフューチャーストア(特徴量ストア)なんですけど、特徴量管理、共有するための仕組みを提供しているというものになります。

特徴量を管理して提供するというお話ですので、狭く言うと特徴量というさっきのテーブルみたいな、そういったものが、きちんとあるタイミングで更新され、管理されている、そこから皆さんが使えるように情報を、どんどん提供できていく機能さえあれば、(一応狭義の特徴量ストアという考え方になりますが)その特徴量というものを作る前に、いろんなことやらないといけないよねとか、きちんと作った後も、整備しとかないといけないよねとなるので、特徴量ストアの周りには、他にも少し必要な要素っていうのは追加されます。そこを少し御説明をします。
特徴量ストアの周りに必要な要素
まず、データがあって、先程のようなATMの利用回数が影響するんじゃないかとか、いろんな軸を用意していくことになるのですが、その時には、そもそもどんな特徴量を作ればいいの?という話が当然出てきます。なので、特徴量設計(特徴量エンジニアリング)をしてあげます。 すると、こうやって特徴量を作ればいいんだとか、このテーブルのここを集計すると、例えばATMの利用回数がわかるぞとか、そういったことをクエリという形で、(よくデータベースの処理ですとSQLと呼ばれるクエリの書き方がありますが、)機械がわかる言葉で命令文を書いてあげる必要があります。こういう集計をしなさいというプログラムを書くというイメージです。そういう特徴量を作ったりとか、特徴量を作るクエリを決めてあげる必要があります。
そのクエリも当然、他の人が見た時に何をやっているか、わかるようにきちんと管理しておく必要があるので、まず特徴量のクエリを管理するぞ、というのが出てきます。これがあると例えば毎月とか、毎週とか、毎日とかで特徴量というのを更新していく必要があるので、実際に特徴量を実行していくと、そのクエリに従ってプログラムを実行することは、特徴量を生成していくという層が発生します。そうすると、生のデータから特徴量の計算がされて、特徴量テーブルの中にどんどん入っていくということで、ここでストアされていきます。ここに関していうと、従来からも別にデータベースそのものがこの機構そのものなので、データベースが、ほぼ担っているような機能(データカタログ)になっています。データカタログと呼ばれるデータがもう少しどこにあるのかとか、このデータは何を意味するのかみたいなところも含めて、データカタログというものが管理してると、大体この層のことは実現できるというような、そのようなイメージです。
特徴量の監視
もう一つですね、特徴量を作って皆さんがどんどん使っていくということをした時に、例えば昔はこれは、いい特徴だったとあるとします。 積立NISAを買う人、買わない人を分けるのに非常に役に立つようなデータだったっていうのが、どんどん、どんどん世の中の変遷と共に役に立たないかもしれない、となってくるかもしれません。ですので、そういう特徴量の監視みたいなことを随時していく。これは今も役立つんだろうかみたいなことをチェックしていくといったことも、特徴量ストアとして求められる気がします。
ただですね、この機能自体は、例えば今ですとマシンラーニングOps機能と、機械学習を運用している形ですね。運用していて、それを更新していくところを含む機能ですけども、MLOpsの一部としても、こういう機能を提供しているところも多々出てきておりますので、特徴量ストアというのがMLOpsの一部として提供されている形になります。

特徴量の提供
それから最終的に特徴量の提供で考えないといけないこととしては、バッチとか、リアルタイムで特徴量を皆さん、どんどん、どんどん配信していくっていう機能があるので、ここに関していうと、いろいろなシステムとの連携を担っていく部分になるので、何か特別な機能があるというふうに、バッチとリアルタイムでそれぞれ何か配信していくような仕組みっていうのを考えてあげる必要があります。
こういったものを備えているのが特徴量ストアっていうものの考え方、実装形態だというふうに思っていただければよくて、ただ実装に関していうと、いろんな過去のツールがそのまま使えるケースもあるということを御理解いただければと思います。
特徴量ストア(Feature Store)の構築
実際にそのような機能群達を作っていくのが特徴量ストアのあり方だと考えた時に、特徴量ストアの構築に関する論点を少し書いているのですが、そもそも特徴量ストアとはどのように実装するのでしょうか。
先程申し上げたようにある種汎用的な仕組みとして、過去提供されているものも特徴量ストアの一部になり得るので、それでは、専用の特徴量ストアが必要なのかとか、DWHを再利用するのかみたいな話が出てきますし、特徴量のストアを設計するといった時に共有される特徴量というのはどうあるべきかというのと、ユースケースごとに特徴量を作り直した方がいいのではないかという議論が当然出てきます。

あと、特徴量ストアの運用そのものをしていくとなった時に、さっきの仕組みはできたのですが、特徴量をそもそも誰が作っているのだろうかとか、誰が監視して、もう一度作り直す必要があるのだろうかみたいなところまで含めて考えないといけませんので、そういったところの議論を書かせていただいてます。
特徴量ストアの実装
特徴量ストアの実装の部分ですが、代表的な特徴量ストアというのは、、例えば大手プラットフォーマーの方々ですね、data bricksであるとか、Amazon SageMakerであるとか、GoogleのVertex AI、Azureなんかにも同じような機能があるかと思います。

そういうところが、それぞれトップフィーチャーストアーとかっていう名前で特徴量の領域を管理するようなツールっていうのを提供されているというところがあります。なので、こういった基盤を既に分析基盤として使われているところで言うと、その特徴量ストアの機能として使うのは、1つの代表的なスタートアップがもう既に出てきていて、ここに書いてあるような企業のところでいくと、特徴量ストアに特化したようなツールの提供を開始していますし、あるいは彼らが提供してる一部を切り出した形でオープンソースが作られていたりとか、そのままオープンソースとして成長してきたようなツール群っていう形もあります。
なのでこういう専用的なツールを使うべきなのか、あるいは従来型のDWHでも、クエリを管理して、特徴量をハイクということ自体は問題なくできると思いますので、こういう特徴量の専用ツールを使うべきか、あるいはこういう歴史のあるデータマネージメント業界の技術を使うか、というところが、切り替えのポイントに、判断のポイントになろうかと思います。
特徴量ストアの設計
では、特徴量ストアの中にどういう特徴量を貯め込んでいくべきなのかという、特徴量ストア設計の部分ですが、特徴量をできるだけみんなで共有した方が効率はいいということになりますが、いかなるユースケースにおいても、特徴量足り得るかっていうと、いろいろ考えないといけないところがあります。これは考え方の1例ですが、例えば、やっぱり似たケースだと似たものが役に立ちますよねっていうことは、すごく想像できると思います。
ですので、これはユースケースがどれぐらい似ているかの度合いを縦軸にもっていたと思ってください。例えばレベル0になると、既にある顧客軸の特徴を取りたいです。例えば、解約予測をする為に使いたいので、この特徴は何か?とか。あるいは解約予測の中でも、もうサービスAに関する解約予測なので既に特徴があります。さらに、誰を対象にして分析しているのか、20代の方を限定分析しますとなると、一つのユースケースがここで出来上がっていて、この中だったらまず1つの特徴量があるので、1つの特徴量ストアというのが役に立ちますよね。データマートというのが一つ役に立ちますよねっていう世界が作れます。では、20代以外にも、色々、他の年代の方々にもその拡張って使えるんじゃないのとか、あるいは年代だけじゃなくて、性別も変えてみましょうか、とか色々、この中で振り分けても大体役に立つんじゃないかという想像がたちます。

そうすると、そこまでこのサンプルの属性というところを振り分けても、役に立っている特徴たちは、一旦共有特徴として認定してもいいでしょうか。
今まではAに関するサービスをやっていたけど、サービスBの解約問題に対して複数化していく時でも、どの段階までサービスを変えていったとしても、この特徴量が役に立ちますよというのであれば、その特徴量を共有できます。この上の図の、Level2ぐらいまでであれば、同じ特徴量を共有できます。
あるいはサービスAは固定しておいた状態で、解約問題じゃなくて、今度は新規の新しく入ってくる方の、新規顧客を捕まえるための特徴としても役に立つんじゃないか、可視化して役に立つんじゃないか、機械学習して役に立つんじゃか、みたいなことを考えるように、ここをちょっと振っていっても、まだ役に立つのであればLevel2-bの特徴、かなり汎用的な特徴といった形で、どんどん、どこの部分を変えていっても役立つ特徴なんだということをきちんと決めていき、どのレベル間でこの特徴量、データマートが役に立つのであるかを決めておくと、複数の共有特徴量を持つ必要が出てくると思いますけれど、それがいくつか準備されているという世界観を作っていけますので、このように、ユースケースの似てる度合いを定義しておいて、どの範囲で役立つかを決めておくと、いい共有特徴量というのが整備できていくということになります。
特徴量ストアの運用
最後に、特徴量ストアの運用の部分ですね。特徴量をどう設計するか、そもそも設計するのかという話になると、今まではほとんどの場合、それも人の作業になっていますので、人がやるということですが、そこに対して弊社はいろんな技術を提供しております。そこで最後に、 dotDataのお話をさせて頂きたいと思います。
dotDataについて
dotDataという製品自体は、特徴量、このウェビナーでいうところの「特徴量を作る」ことに非常に長けたツールです。お客様ごとの、(例えば先程の積立NISA、ローン商品とかを買う、買わないとか)情報、答え、業務の関心となるデータと色々な企業様が持っていらっしゃるデータをそのままdotDataに追加、投入してくださいということを要求するツールです。そのデータを入れていただくと、 dotDataは買う人、買わない人、成約する人、しない人というのを分けるような軸を自動で見つけてくることができます。
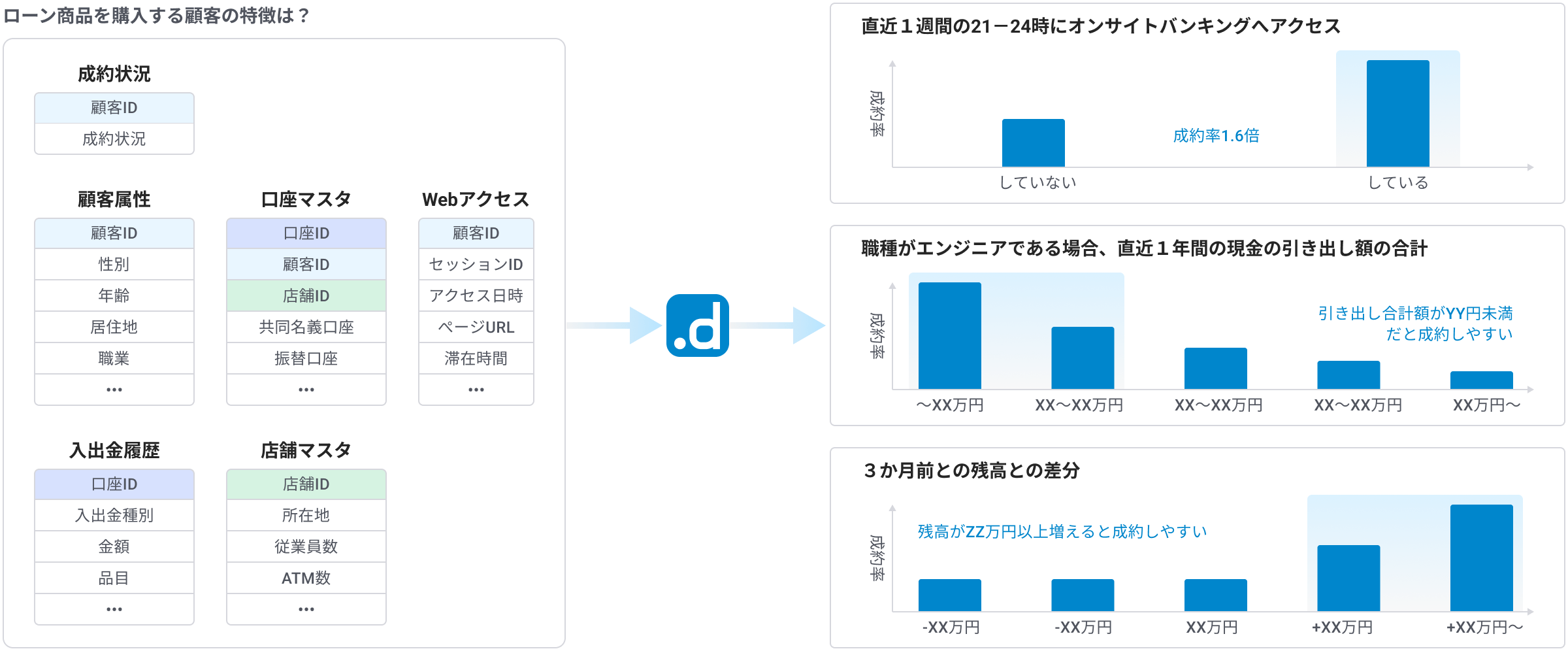
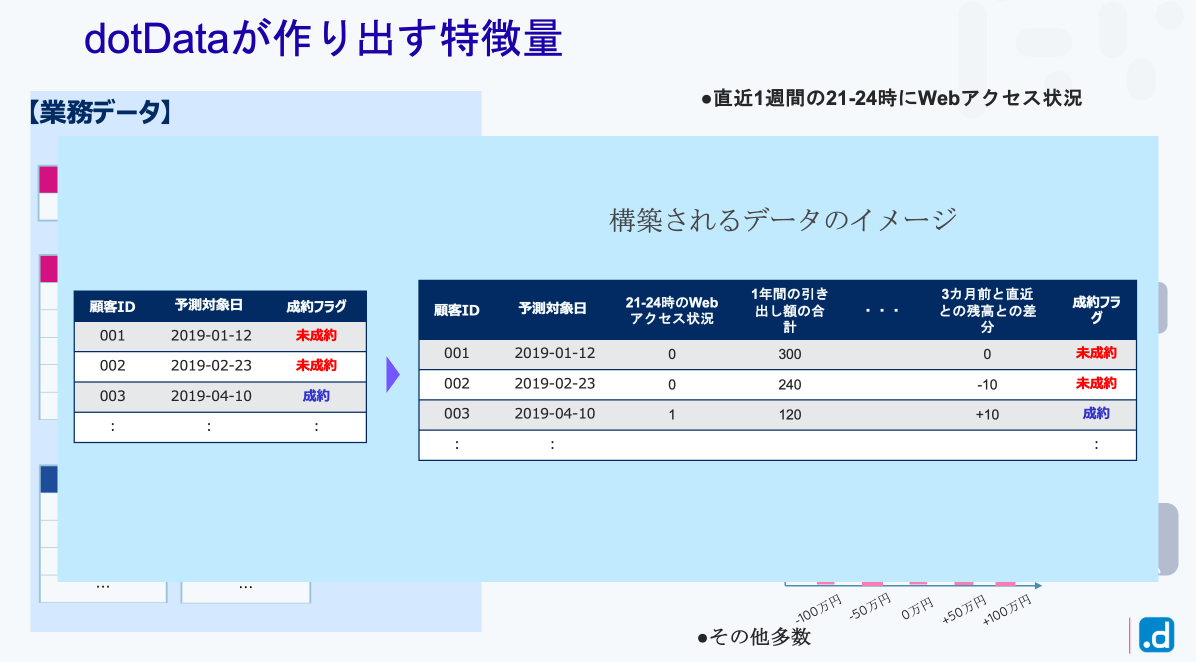
例えばこの直近1週間に21時から24時にWEBにアクセスしているか、していないかみたいなものがあるローン商品を買う、買わないに影響してますよとか、あるいは職種がエンジニアの方では、直近1年間、現金の引き出し額の合計額っていうのが、少ない人の方が成約率が高いですとかですね。多いと成約率が低いですっていうので、成約率が高い人と低い人を分けるような軸を提供していくということができるツールが dotDataです。
ですので、データのイメージだけをお伝えすると、最初にあるお客様がこの商品は成約してませんでした、成約していましたというデータ、答えのデータとこれに対して紐づくような業務のデータというのを入れていただくと、 dotDataがいろんな可能性を探索してきて、ここにどんどん、どんどんデータを追加していってくれます。21時から24時にWEBにアクセスしている、してないっていうのを、例えば0、1で表現したデータを追加していくとか、引き出し額の合計であれば、合計値をここに追加していきます。それらが全て成約する人、しない人を分けるような軸になっているのが、このようなデータを作り出してくれるのが、 dotDataの面白いところで、これが最初に私が御説明したデータマートそのものになっています。
ある業務の関心事に関して、1枚成型されたデータセットになっていることが我々のツールの強みですので、先程の特徴量ストアの話でいうと、特徴量を考えてくれる、特徴量を設計する部分を、自動で担ってくれるというのが、 dotDataの面白いところになります。ですので、その機能を使うというところで、今日のデータプロダクトとかですね、特徴量の共有というところでも貢献できるかなと思っています。
dotDataのプロダクト
dotData製品自体は、色々なバージョンがあって、 dotDataの企業の方々がノーコードで使えるような dotData Enterpriseから、逆にデータサイエンティストの方々が今までのPython環境で、さっきの dotDataがもたらす特徴量を自動で作ってくるとか、さらに自分で設計するのを dotDataに助けてもらうというような、Pythonユーザーの方々でも使っていただける、 dotData Feature Factoryを、ご提供していたり。あるいはもうちょっと業務部門の方々に対して、特徴量を自分で先程出てきたような特徴量を見て、例えば離職する方ってこんなタイプの方々なのかなというビジネス部門の方々が、自分たちの業務っていうのをあそこで分析するために使っていただくとか、そういったツールも、 dotData Insightという形でご提供を開始していますので、こういったところを是非使っていただければなというふうに感じております。
あとdotDataOpsという運用系の仕組みも用意していまして、ここの話でいいますと、先程特徴量監視をして、運用中にもし特徴量の変遷が起こっていたら、今までともう一回特徴量を作り直すっていうお話を差し上げたんですけれども、 dotDataのOps機能ですと、その特徴量が今までよりも違う変遷をしてきていると、違う値を持ち始めていることにも気付くようなことができますし、そこから、生データに戻って、 dotData自体が特徴量を生データから生成しているので、生データのどこが変わったのかというところも調べるようなことができるようになりますし、さらにもう一回特徴量を自動で作り直すということもできます。そういう特徴量から作るOpsということも実現できておりますので、こういったところも今日の話と関連して我々が提供できる価値かなと思っております。
dotDataのお話を最後申し上げると、特徴量ストアを作るための、中核となるようなところになっています。そういう製品として位置づけられるかなと思っております。各種特徴量ストアに関しましては先程のような形で、色々なベンダーさんが特徴量の、特徴量ストアとは管理するような、マネージメントを実施するソフトウェアを提供されてもいますし、それを自分たちで構築していくことも可能だということを、今日御理解いただければと思います。

ということで最終的に、データプロダクトという層の部分に関して実装形態の1つとして特徴量ストアが存在します。その特徴量ストアを作るところには、 dotDataというのも活用いただけますし、実際にその dotDataを使った後、皆様が分析する際にも、 dotData、Auto MLの機能も持ってるので、例えばAuto MLの機能を使って予測をするということもできますし、先程の業務の分析のところでdotData Insightという形で業務分析にもご利用いただけるものになっておりますので、中核として dotDataを位置づけていただけると思います。その使い方ができると大変嬉しく思うなというところでございます。
ということで、今日の私からの解説と、データプロダクトとか特徴量共有の解説が以上となっております。ありがとうございました。