
MLOpsとは?
- MLOps
MLOpsは、機械学習モデルの開発から運用までのプロセスを効率化し、ビジネスプロセスに革命をもたらす可能性を秘めたモデルを効果的に管理するために重要です。DevOpsの原則を適用し、再現性、透明性、スケーラビリティを確保することで、企業は機械学習プロジェクトの可能性を最大限に引き出し、ビジネス価値を創出することが可能になります。このブログでは、そもそもMLOpsとは何?から、実践に必要なプロセス、課題などの全体像を解説し、機械学習をビジネスに取り入れたいと考えるすべての方にとっての価値を探求します。
MLOpsは、機械学習の開発と運用を統合する新しい分野で、DevOpsの原則をMLシステムに適用して、効率的に高品質の機械学習モデルを実稼働環境にデプロイすることを目指します。各企業や組織によって定義は異なるものの、その核心は、データサイエンス、データエンジニアリング、ソフトウェア開発の協働を通じて、機械学習プロジェクトの品質と効率を向上させることにあります。MLOpsは、技術やツールセット以上に、効果的な機械学習プロジェクト運用のための文化とプロセスの枠組みです。
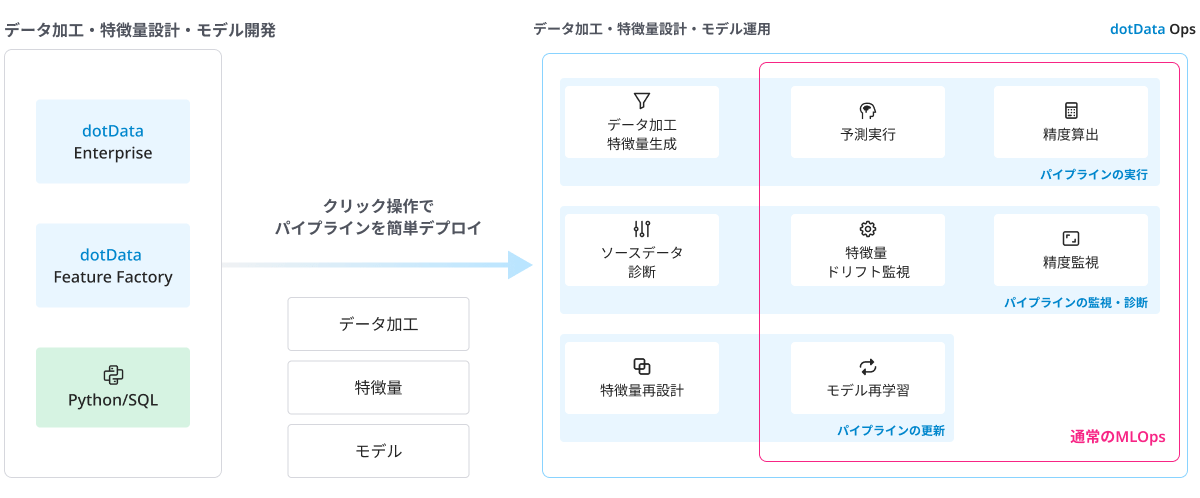
MLOpsは、機械学習モデルを効率的に運用することで、その価値を最大限活用するためのプラクティスです。既存のMLOpsではプラクティスの中心に機械学習モデルがあり、機械学習モデルを関心事として構築されていました。既存のMLOpsの活動としては、図のように予測の実行、精度の算出、監視、特徴量の監視、そしてモデルの再学習などがあります。こういった活動の目的は、機械学習モデルを継続的に活用し、精度が劣化したら新しいモデルを構築する、というものです。
dotDataのMLOpsでは、機械学習モデル中心のアプローチから特徴量生成モデル、機械学習モデルの両社にフォーカスを当てたアプローチを取っています。既存のMLOpsの枠組みの外側に追いやられがちなデータ加工、特徴量生成を機械学習モデルと同様にMLOpsのメインの登場人物と捉えます。
既存のMLOpsでは、予測の実行を行いますが、dotDataのMLOpsではソースデータからデータ加工、特徴量の生成、そして予測の実行までEnd-to-Endで処理を行います。機械学習のプロセスにおいて、データ加工、特徴量の生成も機械学習モデルと切り離すことが出来ない要素だと捉えているためです。
同様に、モデルのモニタリング、分析だけでなく、特徴量、ソースデータのモニタリング、分析も行います。さらに一番の特徴として、精度が劣化した際に、モデルの再学習だけでなく、特徴量の再設計もMLOpsのプロセスとして行います。
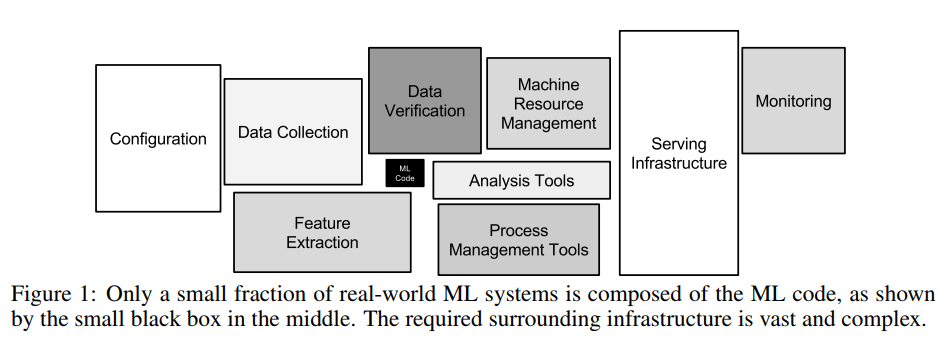
MLOpsは、機械学習の開発と運用の間のギャップを埋めることに重点をあてていますが、このアプローチの真の価値(MLOpsの重要性)は、機械学習プロジェクトにおけるタスク分布とその複雑さを理解することから生まれてきます。2014年にGoogleのチームが国際会議NeurIPSのワークショップSE4ML(Software Engineering for Machine Learning)に出した有名な論文にも、実際のMLシステムのうち、MLコードで構成されている部分は下の図の黒い部分のみで、その周辺インフラがいかに広大で複雑であるかを示しています。
”下の図は、機械学習の予測アルゴリズムなどを記述するいわゆるモデリングと呼ばれる処理に関するコードを書くのは本当に一部でしかないということを表している。これは、一般的に「機械学習の作業は前処理が大半を占め、モデルを学習する部分は少ない」と言われ続けてきたこととも一致する。”
https://research.google/pubs/machine-learning-the-high-interest-credit-card-of-technical-debt/
MLOpsが重要な理由として、「モデル精度の維持」と「迅速なビジネス活用」の2つが挙げられます。
モデル精度の維持は機械学習プロジェクトにおける重要な課題です。学習時には良い精度だったモデルが今日良い精度を出せるとは限りません。さらに言えば、昨日精度が高かったモデルが、今日大幅に精度が劣化する可能性すらあります。現代という絶え間なく目まぐるしいスピードで環境が変化している時代においては、1つの機械学習モデルを長期間に渡って利用し続けるというストラテジーは現実的ではありません。MLOpsのプラクティスを活用することで、精度のモニタリング、再学習をイテラティブに行い、モデルの精度の維持を効率的に行うことができます。
迅速なビジネス活用も近年求められています。AIの活用が急速に進む現代において、機械学習プロジェクトでビジネス価値を創出し、ROIに見合う成果を得るためには、ユースケース一つ一つに対して自動化なしで機械学習モデルを開発、運用していく従来のアプローチは適しません。特徴量生成や機械学習モデルの学習、運用、モニタリング、再学習の一連のプロセスをMLOpsのプラクティスに従って自動化することで数多くの機械学習プロジェクトを高速に推進することができます。
MLOpsは、機械学習プロジェクトのライフサイクル全体を通じて、効率性、再現性、およびスケーラビリティを確保するために不可欠です。データサイエンスチームと運用チームの間の連携を強化し、モデルのライフサイクル管理を合理化することで、企業は機械学習の可能性を最大限に引き出します。
データサイエンスチームが作業するための環境を整備し、成果物を適切に管理することです。これには、コード、データセット、モデルなどの成果物のバージョン管理が含まれます。
データサイエンスチームによって検証された処理を自動化し、パイプライン化します。これは、開発チームと運用チーム間の連携を強化し、モデルの開発からデプロイメントまでのプロセスをスムーズにします。
構築されたモデルを実際のシステムに統合し、推論結果をアプリケーションやビジネスプロセスに適用します。これにより、モデルが実世界の問題解決に直接貢献することが可能になります。
モデルがデプロイされた後も、その性能を継続的に監視し、必要に応じて再トレーニングや更新を行います。これにより、モデルが時間とともに変化するデータや環境に適応し続けることが保証され、効果をモニタリングすることができます。
データの品質を維持し、時間の経過とともにデータが変化すること(データドリフト)に対応するための戦略を実装します。これは、モデルの精度を長期にわたって保つために重要です。
次に、MLOpsのプロセスを、Google Cloudのドキュメントをベースに、ステップバイステップでMLOpsの成熟度モデルに沿った各段階の特徴と目標を解説します。
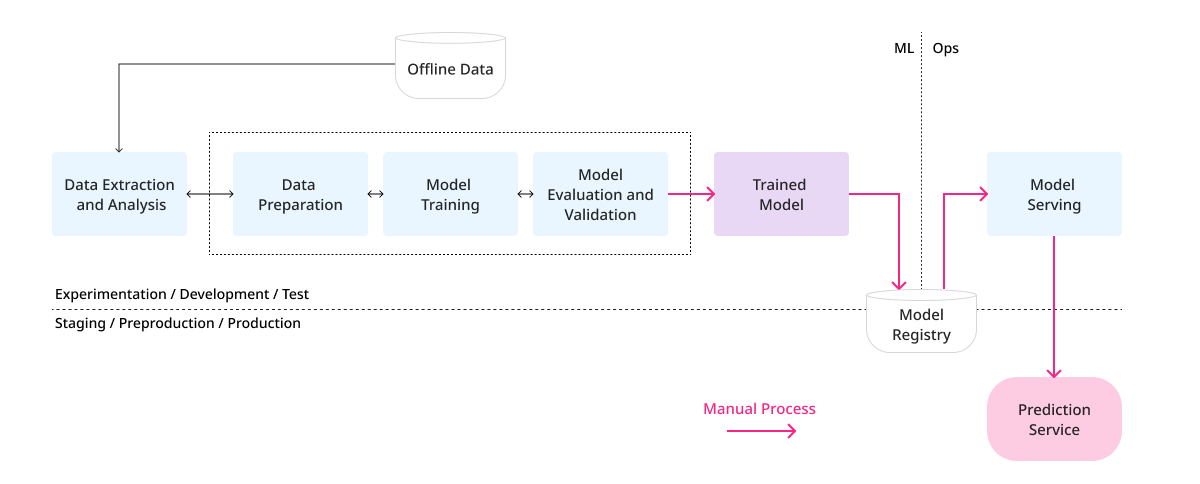
多くのチームでは、高度な技術を持つデータサイエンティストや、ML研究者が最先端のモデルを構築しますが、これらのモデル構築からデプロイメントに至るプロセスは、多くの場合、マニュアルでの作業に依存しています。この段階では、プロジェクト管理のモデルのデプロイメントに自動化が取り入れられていないため、効率性や再現性に欠け、エラーのリスクも高まります。
上の図は、自動化されたMLパイプラインを示しており、データの自動収集からモデルの自動デプロイメントに至るまでの流れを表現しています。
MLOpsレベル1は、MLパイプラインの自動化に焦点を当てています、この段階の目標は、モデルの継続的なトレーニングを自動化し、それによってモデル予測サービスの継続的なデリバリーを実現することです。この自動化により、新しいデータを用いた本番環境でのモデルの再トレーニングプロセスが容易になります。これを達成する為には、パイプラインに自動化されたデータとモデルの検証ステップ、パイプラインのトリガー、そして、メタデータの管理を組み込む必要があります。
自動化されたMLパイプラインは、データの収集から前処理、モデルのトレーニング、評価、そしてデプロイメントに至るまでの各ステップを自動的に実行します。これにより、データサイエンティストやMLエンジニアは、繰り返し発生する手作業から解放され、より創造的なタスクや、モデル改善などに集中できるようになります。また、自動化によって、プロセスの透明性が向上し、エラーの発生が減ることで、全体としてのプロジェクトの品質と速度が向上します。
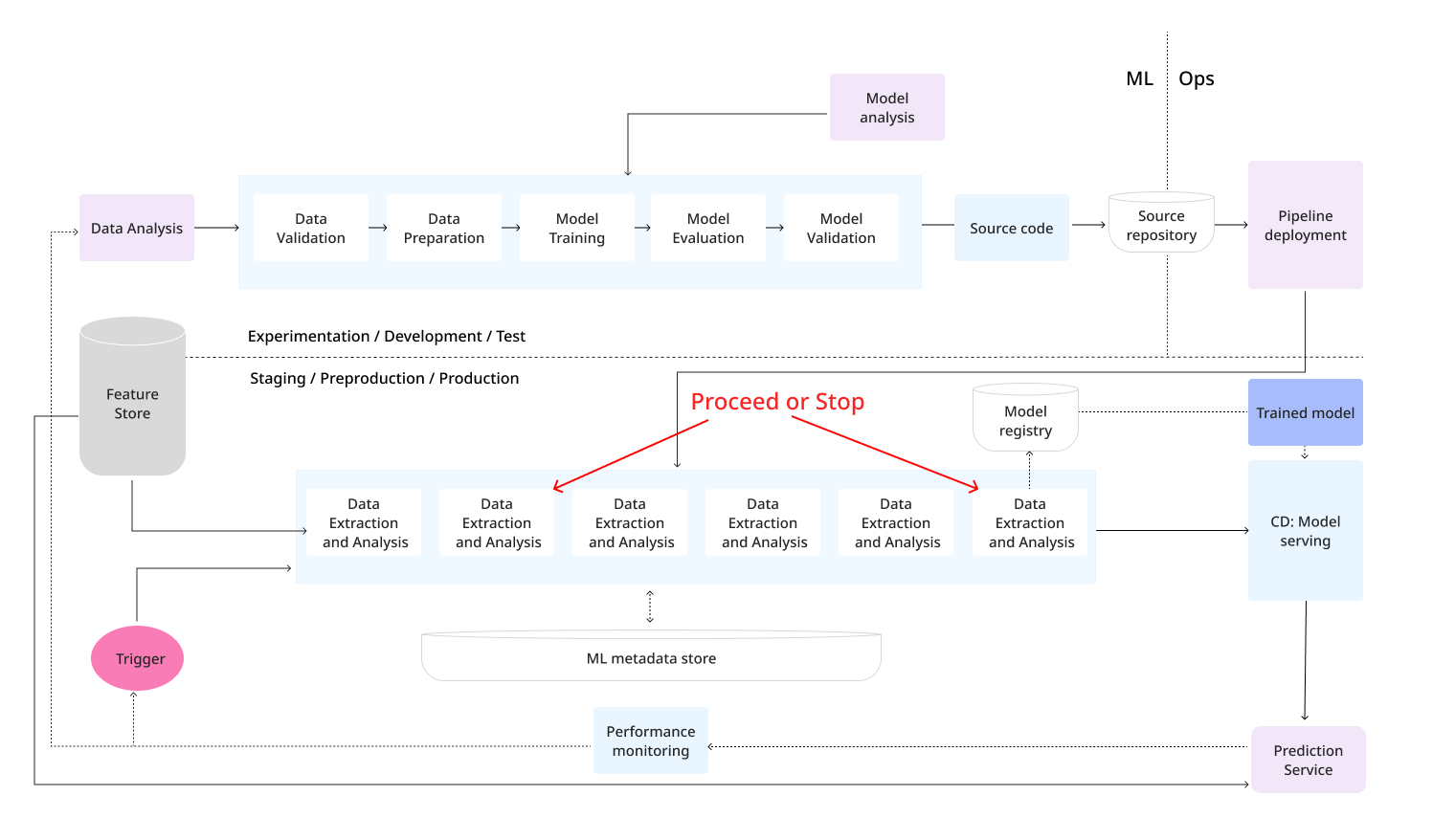
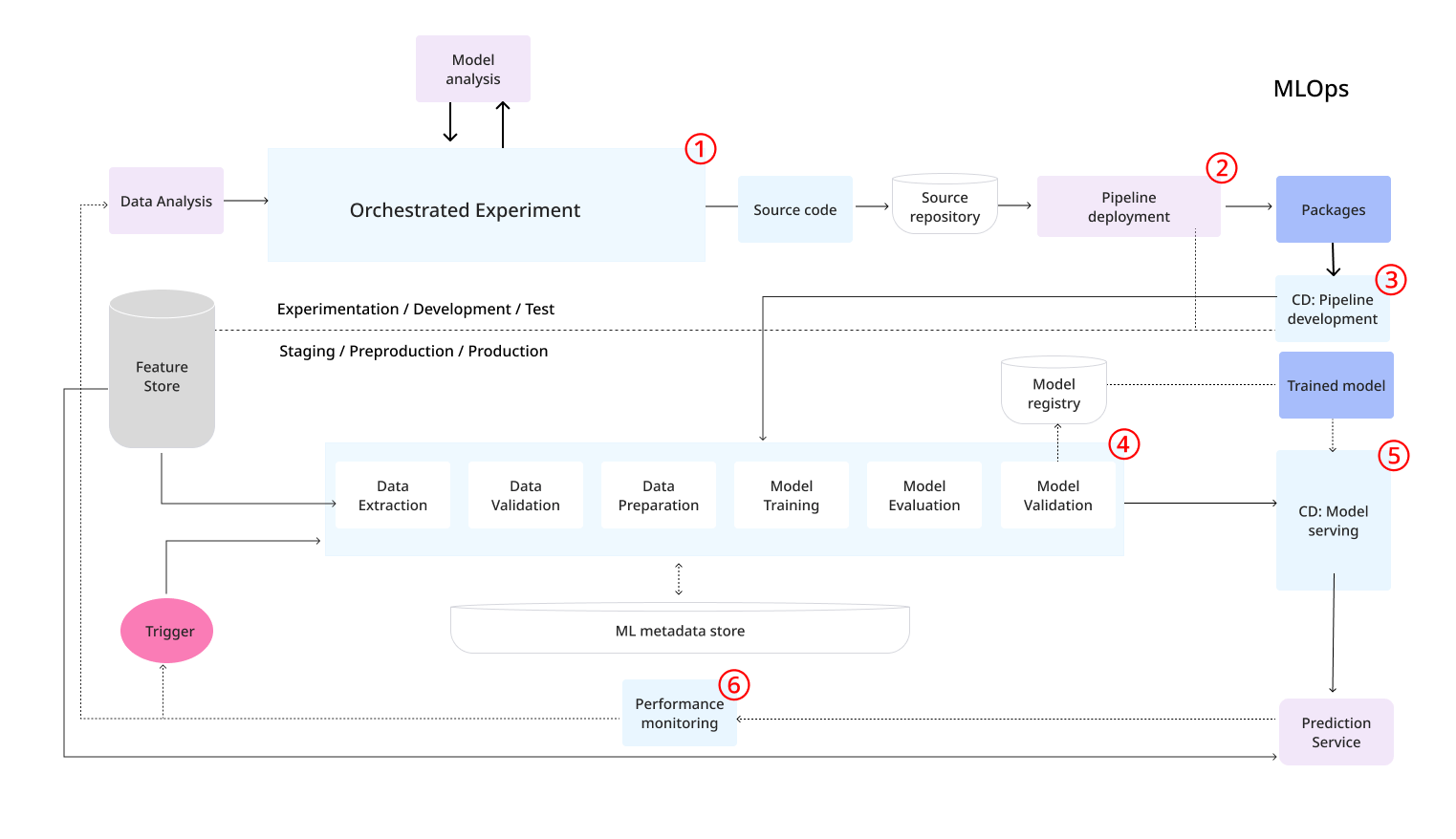
上の図は、CI/CDを活用したMLパイプラインの実装を示しており、自動化されたMLパイプラインの構築とCI/CDルーティンの自動化の特徴です。
MLOpsレベル2では、継続的インテグレーション(CI)と継続的デリバリー(CD)の自動化に焦点を当てています。この段階では、本番環境でのパイプラインの迅速かつ確実な更新を実現する為に、自動のCI/CDシステムの導入が不可欠となります。このシステムにより、データサイエンティストは、特徴量エンジニアリング、モデルアークテクチャ、モデルの品質向上、ハイパーパラメータの調整など、新しいアイデアを迅速に試すことができます。これらのアイデアを実装し、新しいパイプラインコンポーネントを自動的に構築、テストし、目標の環境にデプロイするプロセスが自動化されます。
このブログ記事では、MLOpsの基本概念からその他用な定義、重要性、そして段階別のプロセスについて詳しく掘り下げてきました。MLOpsは、機械学習の開発と運用を統合し、DevOpsの原則をMLシステムに適用することで、効率的に高品質の機械学習モデルを実稼働環境にデプロイすることを目指す新しい分野です。データサイエンス、データエンジニアリング、ソフトウェア開発の協働を通じて、機械学習プロジェクトの品質と効率を向上させることにあります。
次のブログでは、MLOpsのデザインとツールに焦点を当てます。MLOpsを実践する為に必要なツールやそれらを効果的に活用するための戦略について詳しく掘り下げていきます
dotData Opsは、データ、特徴量、予測パイプラインを、分析チームがセルフサービスでデプロイ、実ビジネスで運用するための環境を提供します。データ分析のビジネス価値を業務で試行し素早く検証することで、意思決定者からの信頼を高め、本番運用への投資判断を加速します。dotDataの特徴量自動設計によって、ビジネス価値の検証、特徴量ドリフトの診断、予測精度の改善など、MLOpsを革新します。


